AWS Big Data Blog
Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
During the recent years, there has been a shift from monolithic to the microservices architecture. The microservices architecture makes applications easier to scale and quicker to develop, enabling innovation and accelerating time to market for new features. However, this approach causes data to live in different silos, which makes it difficult to perform analytics. To gain deeper and richer insights, you should bring all your data from different silos into one place.
AWS offers replication tools such as AWS Database Migration Service (AWS DMS) to replicate data changes from a variety of source databases to various destinations including Amazon Simple Storage Service (Amazon S3). But customers who need to sync the data in a data lake with updates and deletes on the source systems still face a few challenges:
- It’s difficult to apply record-level updates or deletes when records are stored in open data format files (such as JSON, ORC, or Parquet) on Amazon S3.
- In streaming use cases, where jobs need to write data with low latency, row-based formats such as JSON and Avro are best suited. However, scanning many small files with these formats degrades the read query performance.
- In use cases where the schema of the source data changes frequently, maintaining the schema of the target datasets via custom code is difficult and error-prone.
Apache Hudi provides a good way to solve these challenges. Hudi builds indexes when it writes the records for the first time. Hudi uses these indexes to locate the files to which an update (or delete) belongs. This enables Hudi to perform fast upsert (or delete) operations by avoiding the need to scan the whole dataset. Hudi provides two table types, each optimized for certain scenarios:
- Copy-On-Write (COW) – These tables are common for batch processing. In this type, data is stored in a columnar format (Parquet), and each update (or delete) creates a new version of files during the write.
- Merge-On-Read (MOR) – Stores Data using a combination of columnar (for example Parquet) and row-based (for example Avro) file formats and is intended to expose near-real time data.
Hudi datasets stored in Amazon S3 provide native integration with other AWS services. For example, you can write Apache Hudi tables using AWS Glue (see Writing to Apache Hudi tables using AWS Glue Custom Connector) or Amazon EMR (see New features from Apache Hudi available in Amazon EMR). Those approaches require having a deep understanding of Hudi’s Spark APIs and programming skills to build and maintain data pipelines.
In this post, I show you a different way of working with streaming data with minimum coding. The steps in this post demonstrate how to build fully scalable pipelines using SQL language without prior knowledge of Flink or Hudi. You can query and explore your data in multiple data streams by writing familiar SELECT queries. You can join the data from multiple streams and materialize the result to a Hudi dataset on Amazon S3.
Solution overview
The following diagram provides an overall architecture of the solution described in this post. I describe the components and steps fully in the sections that follow.
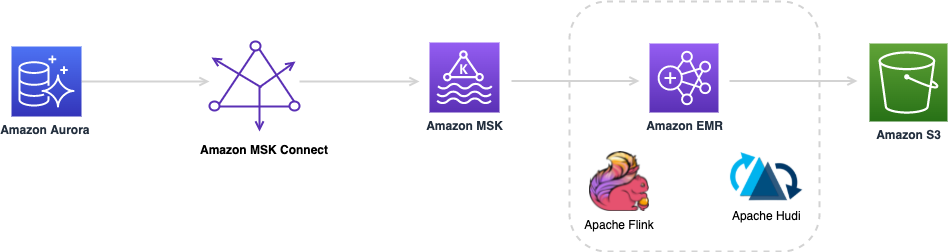
You use an Amazon Aurora MySQL database as the source and a Debezium MySQL connector with the setup described in the MSK Connect lab as the change data capture (CDC) replicator. This lab walks you through the steps to set up the stack for replicating an Aurora database salesdb to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster, using Amazon MSK Connect with a MySql Debezium source Kafka connector.
In September 2021, AWS announced MSK Connect for running fully managed Kafka Connect clusters. With a few clicks, MSK Connect allows you to easily deploy, monitor, and scale connectors that move data in and out of Apache Kafka and MSK clusters from external systems such as databases, file systems, and search indexes. You can now use MSK Connect for building a full CDC pipeline from many database sources to your MSK cluster.
Amazon MSK is a fully managed service that makes it easy to build and run applications that use Apache Kafka to process streaming data. When you use Apache Kafka, you capture real-time data from sources such as database change events or website clickstreams. Then you build pipelines (using stream processing frameworks such as Apache Flink) to deliver them to destinations such as a persistent storage or Amazon S3.
Apache Flink is a popular framework for building stateful streaming and batch pipelines. Flink comes with different levels of abstractions to cover a broad range of use cases. See Flink Concepts for more information.
Flink also offers different deployment modes depending on which resource provider you choose (Hadoop YARN, Kubernetes, or standalone). See Deployment for more information.
In this post, you use the SQL Client tool as an interactive way of authoring Flink jobs in SQL syntax. sql-client.sh compiles and submits jobs to a long-running Flink cluster (session mode) on Amazon EMR. Depending on the script, sql-client.sh either shows the tabular formatted output of the job in real time, or returns a job ID for long-running jobs.
You implement the solution with the following high-level steps:
- Create an EMR cluster.
- Configure Flink with Kafka and Hudi table connectors.
- Develop your real-time extract, transform, and load (ETL) job.
- Deploy your pipeline to production.
Prerequisites
This post assumes you have a running MSK Connect stack in your environment with the following components:
- Aurora MySQL hosting a database. In this post, you use the example database
salesdb. - The Debezium MySQL connector running on MSK Connect, ending in Amazon MSK in your Amazon Virtual Private Cloud (Amazon VPC).
- An MSK cluster running within in a VPC.
If you don’t have an MSK Connect stack, follow the instructions in the MSK Connect lab setup and verify that your source connector replicates data changes to the MSK topics.
You also need the ability to connect directly to the EMR leader node. Session Manager is a feature of AWS Systems Manager that provides you with an interactive one-click browser-based shell window. Session Manager also allows you to comply with corporate policies that require controlled access to managed nodes. See Setting up Session Manager to learn how to connect to your managed nodes in your account via this method.
If Session Manager is not an option, you can also use Amazon Elastic Compute Cloud (Amazon EC2) private key pairs, but you’ll need to launch the cluster in a public subnet and provide inbound SSH access. See Connect to the master node using SSH for more information.
Create an EMR cluster
The latest released version of Apache Hudi is 0.10.0, at the time of writing. Hudi release version 0.10.0 is compatible with Flink release version 1.13. You need Amazon EMR release version emr-6.4.0 and later, which comes with Flink release version 1.13. To launch a cluster with Flink installed using the AWS Command Line Interface (AWS CLI), complete the following steps:
- Create a file,
configurations.json, with the following content: - Create an EMR cluster in a private subnet (recommended) or in a public subnet of the same VPC as where you host your MSK cluster. Enter a name for your cluster with the
--nameoption, and specify the name of your EC2 key pair as well as the subnet ID with the--ec2-attributesoption. See the following code: - Wait until the cluster state changes to
Running. - Retrieve the DNS name of the leader node using either the Amazon EMR console or the AWS CLI.
- Connect to the leader node via Session Manager or using SSH and an EC2 private key on Linux, Unix, and Mac OS X.
- When connecting using SSH, port 22 must be allowed by the leader node’s security group.
- Make sure the MSK cluster’s security group has an inbound rules that accepts traffic from the EMR cluster’s security groups.
Configure Flink with Kafka and Hudi table connectors
Flink table connectors allow you to connect to external systems when programming your stream operations using Table APIs. Source connectors provide access to streaming services including Kinesis or Apache Kafka as a data source. Sink connectors allow Flink to emit stream processing results to external systems or storage services like Amazon S3.
On your Amazon EMR leader node, download the following connectors and save them in the /lib/flink/lib directory:
- Source connector – Download flink-connector-kafka_2.11-1.13.1.jar from the Apache repository. The Apache Kafka SQL connector allows Flink to read data from Kafka topics.
- Sink connector – Amazon EMR release version emr-6.4.0 comes with Hudi release version 0.8.0. However, in this post you need Hudi Flink bundle connector release version 0.10.0, which is compatible with Flink release version 1.13. Download hudi-flink-bundle_2.11-0.10.0.jar from the Apache repository. It also contains multiple file system clients, including S3A for integrating with Amazon S3.
Develop your real-time ETL job
In this post, you use the Debezium source Kafka connector to stream data changes of a sample database, salesdb, to your MSK cluster. Your connector produces data changes in JSON. See Debezium Event Deserialization for more details. The Flink Kafka connector can deserialize events in JSON format by setting value.format with debezium-json in the table options. This configuration provides the full support for data updates and deletes, in addition to inserts.
You build a new job using Flink SQL APIs. These APIs allow you to work with the streaming data, similar to tables in relational databases. SQL queries specified in this method run continuously over the data events in the source stream. Because the Flink application consumes unbounded data from a stream, the output constantly changes. To send the output to another system, Flink emits update or delete events to the downstream sink operators. Therefore, when you work with CDC data or write SQL queries where the output rows need to update or delete, you must provide a sink connector that supports these actions. Otherwise, the Flink job ends with an error with the following message:
Launch the Flink SQL client
Start a Flink YARN application on your EMR cluster with the configurations you previously specified in the configurations.json file:
After the command runs successfully, you’re ready to write your first job. Run the following command to launch sql-client:
Your terminal window looks like the following screenshot.

Set the job parameters
Run the following command to set the checkpointing interval for this session:
Define your source tables
Conceptually, processing streams using SQL queries requires interpreting the events as logical records in a table. Therefore, the first step before reading or writing the data with SQL APIs is to create source and target tables. The table definition includes the connection settings and configuration along with a schema that defines the structure and the serialization format of the objects in the stream.
In this post, you create three source tables. Each corresponds to a topic in Amazon MSK. You also create a single target table that writes the output data records to a Hudi dataset stored on Amazon S3.
Replace BOOTSTRAP SERVERS ADDRESSES with your own Amazon MSK cluster information in the 'properties.bootstrap.servers' option and run the following commands in your sql-client terminal:
By default, sql-client stores these tables in memory. They only live for the duration of the active session. Anytime your sql-client session expires, or you exit, you need to recreate your tables.
Define the sink table
The following command creates the target table. You specify 'hudi' as the connector in this table. The rest of the Hudi configurations are set in the with(…) section of the CREATE TABLE statement. See the full list of Flink SQL configs to learn more. Replace S3URI OF HUDI DATASET LOCATION with your Hudi dataset location in Amazon S3 and run the following code:
Verify the Flink job’s results from multiple topics
For select queries, sql-client submits the job to a Flink cluster, then displays the results on the screen in real time. Run the following select query to view your Amazon MSK data:
This query joins three streams and aggregates the count of customer orders, grouped by each customer record. After a few seconds, you should see the result in your terminal. Note how the terminal output changes as the Flink job consumes more events from the source streams.
Sink the result to a Hudi dataset
To have a complete pipeline, you need to send the result to a Hudi dataset on Amazon S3. To do that, add an insert into CustomerHudi statement in front of the select query:
This time, the sql-client disconnects from the cluster after submitting the job. The client terminal doesn’t have to wait for the results of the job as it sinks its results to a Hudi dataset. The job continues to run on your Flink cluster even after you stop the sql-client session.
Wait a few minutes until the job generates Hudi commit log files to Amazon S3. Then navigate to the location in Amazon S3 you specified for your CustomerHudi table, which contains a Hudi dataset partitioned by MKTSEGMENT column. Within each partition you also find Hudi commit log files. This is because you defined the table type as MERGE_ON_READ. In this mode with the default configurations, Hudi merges commit logs to larger Parquet files after five delta commit logs occur. Refer to Table & Query Types for more information. You can change this setup by changing the table type to COPY_ON_WRITE or specifying your custom compaction configurations.
Query the Hudi dataset
You may also use a Hudi Flink connector as a source connector to read from a Hudi dataset stored on Amazon S3. You do that by running a select statement against the CustomerHudi table, or create a new table with hudi specified for connector. The path must point to an existing Hudi dataset’s location on Amazon S3. Replace S3URI OF HUDI DATASET LOCATION with your location and run the following command to create a new table:
Note the additional column names prefixed with _hoodie_. These columns are added by Hudi during the write to maintain the metadata of each record. Also note the extra 'hoodie.datasource.query.type' read configuration passed in the WITH portion of the table definition. This makes sure you read from the real-time view of your Hudi dataset. Run the following command:
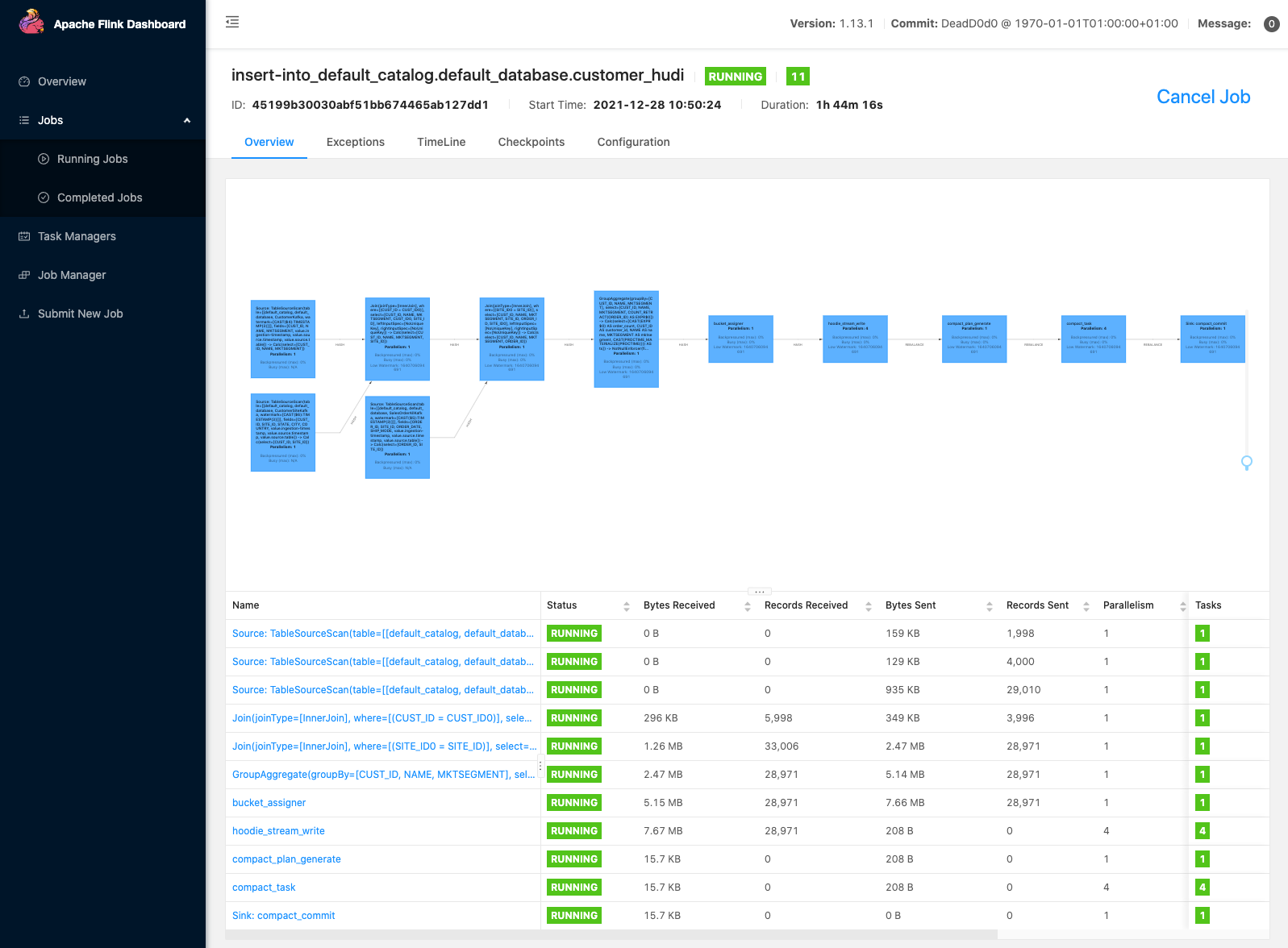
The terminal displays the result within 30 seconds. Navigate to the Flink web interface, where you can observe a new Flink job started by the select query (See below for how to find the Flink web interface). It scans the committed files in the Hudi dataset and returns the result to the Flink SQL client.
Use a mysql CLI or your preferred IDE to connect to your salesdb database, which is hosted on Aurora MySQL. Run a few insert statements against the SALES_ORDER_ALL table:
After a few seconds, a new commit log file appears in your Hudi dataset on Amazon S3. The Debezium for MySQL Kafka connector captures the changes and produces events to the MSK topic. The Flink application consumes the new events from the topic and updates the customer_count column accordingly. It then sends the changed records to the Hudi connector for merging with the Hudi dataset.
Hudi supports different write operation types. The default operation is upsert, where it initially inserts the records in the dataset. When a record with an existing key arrives in a process, it’s treated as an update. This operation is useful here where you expect to sync your dataset with the source database, and duplicate records are not expected.
Find the Flink web interface
The Flink web interface helps you view a Flink job’s configuration, graph, status, exception errors, resource utilization, and more. To access it, first you need to set up an SSH tunnel and activate a proxy in your browser, to connect to the YARN Resource Manager. After you connect to the Resource Manager, you choose the YARN application that’s hosting your Flink session. Choose the link under the Tracking UI column to navigate to the Flink web interface. For more information, see Finding the Flink web interface.
Deploy your pipeline to production
I recommend using Flink sql-client for quickly building data pipelines in an interactive way. It’s a good choice for experiments, development, or testing your data pipelines. For production environments, however, I recommend embedding your SQL scripts in a Flink Java application and running it on Amazon Kinesis Data Analytics. Kinesis Data Analytics is a fully managed service for running Flink applications; it has built-in auto scaling and fault tolerance features to provide your production applications the availability and scalability they need. A Flink Hudi application with the scripts from this this post is available on GitHub. I encourage you to visit this repo, and compare the differences between running in sql-client and Kinesis Data Analytics.
Clean up
To avoid incurring ongoing charges, complete the following cleanup steps:
- Stop the EMR cluster.
- Delete the AWS CloudFormation stack you created using the MSK Connect Lab setup.
Conclusion
Building a data lake is the first step to break down data silos and running analytics to gain insights from all your data. Syncing the data between the transactional databases and data files on a data lake isn’t trivial and involves significant effort. Before Hudi added support for Flink SQL APIs, Hudi customers had to have the necessary skills for writing Apache Spark code and running it on AWS Glue or Amazon EMR. In this post, I showed you a new way in which you can interactively explore your data in streaming services using SQL queries, and accelerate the development process for your data pipelines.
To learn more, visit Hudi on Amazon EMR documentation.
About the Author
 Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems which are reliable, secure, efficient, and cost-effective. He works backward from customer’s use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the Cloud.
Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems which are reliable, secure, efficient, and cost-effective. He works backward from customer’s use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the Cloud.