AWS Big Data Blog
New features from Apache Hudi available in Amazon EMR
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development by providing record-level insert, update and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon S3 or HDFS. You can use it to comply with data privacy regulations and simplify data ingestion pipelines that deal with late-arriving or updated records from streaming data sources, or retrieve data using change data capture (CDC) from transactional systems. Apache Hudi is integrated with open source big data analytics frameworks like Apache Spark, Apache Hive, Presto and Trino. It allows you to maintain data in Amazon S3 or HDFS in open formats like Apache Parquet and Apache Avro.
Starting with release version 5.28, Amazon EMR installs Hudi components by default when Spark, Hive, or Presto is installed. Since then, several new capabilities and bug fixes have been added to Apache Hudi and incorporated into Amazon EMR. In June 2020, Apache Hudi graduated from incubator to a top-level Apache project. In this blog post, we provide a summary of some of the key features in Apache Hudi release 0.6.0, which are available with Amazon EMR releases 5.31.0, 6.2.0 and later. We also summarize some of the recent integrations of Apache Hudi with other AWS services.
Use Apache Hudi without having to convert existing Parquet data in your data lake
For customers operating at scale on several terabytes or petabytes of data, migrating their datasets to start using Apache Hudi is a very time-consuming operation. Depending on the size of the dataset and the compute power, it might take several hours using insert or bulk insert write operations. These operations rewrite the entire dataset into an Apache Hudi table format so that Apache Hudi could generate per-record metadata and index information required to perform record-level operations. Even if the existing dataset is in Parquet format, Hudi would rewrite it entirely in its compatible format, which is also Parquet. This created an obstacle to customer adoption and onboarding.
To address this problem, Amazon EMR team collaborated with the Apache Hudi community to create a feature in release version 0.6.0, the bootstrap operation, which allows customers to use Hudi with their existing Parquet datasets without needing to rewrite the dataset. As part of this operation, Hudi generates metadata only. It writes the metadata in a separate file that corresponds to each data file in the dataset. The original data is left as-is and not copied over. The result is a faster, less compute-intensive onboarding process. The bootstrap operation is available in Amazon EMR releases 5.31.0 and 6.2.0, which ship with Apache Hudi 0.6.0.
The following code snippet shows how you can bootstrap an existing Parquet dataset:
Hudi supports two modes for the bootstrap operation that can be defined at partition level:
- METADATA_ONLY: Generates record-level metadata for each source record and stores it in a separate file that corresponds to each source data file at the Hudi table location. The source data is not copied over. It is the default mode for the bootstrap operation and makes onboarding faster and more lightweight. During query execution, the source data is merged with Hudi metadata to return the results.
- FULL_RECORD: Generates record-level metadata and copies over the source data to a single file a the Hudi table location. This is similar to initializing Hudi datasets using bulk insert or insert operation. During query execution both the data and metadata is read from a single file, which can improve performance for queries that touch both the data and metadata columns. Thus, this mode might be better for partitions that are queried more frequently than others.
With a single bootstrap operation, users can choose some partitions to be bootstrapped with FULL_RECORD mode, while others with METADATA_ONLY mode using a regular expression. The following example shows the configurations that can be used to bootstrap partitions for the months January to August 2020 with FULL_RECORD mode, while rest of the partitions will use the default METADATA_ONLY mode:
For more information about the bootstrap configurations, see the Efficient Migration of Large Parquet Tables to Apache Hudi blog post published by the Apache Hudi community.
We measured bootstrap operation performance. We used it to create a new Hudi dataset from a 1 TB Parquet dataset on Amazon S3 and then compared it against bulk insert performance on the same dataset. For our testing, we used an EMR cluster with 11 c5.4xlarge instances. The bootstrap performed five times faster than bulk insert. The operation was complete in 93 minutes, compared to the bulk insert operation, which took 465 minutes.
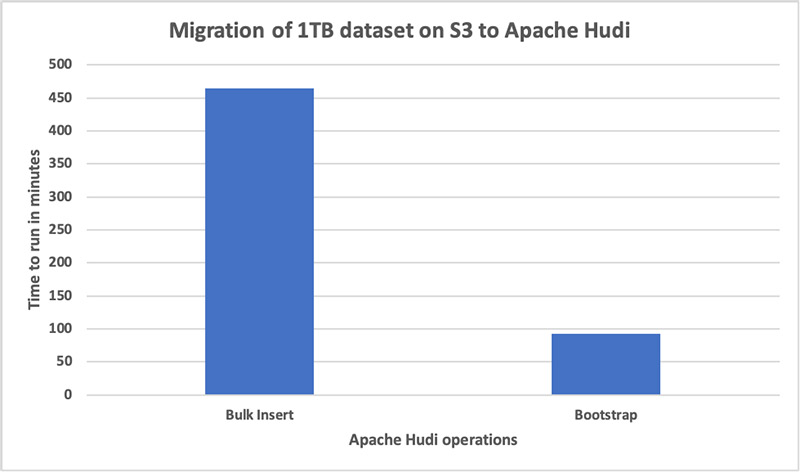
Bulk insert performance improvement
Hudi provides a bulk insert operation, which is recommended for scenarios where customers want to ingest terabytes of data into a new or existing table. In release 0.6.0, the Hudi community redesigned the functionality to remove the performance overhead of intermediate conversion of incoming Spark rows to Avro format before writing the Avro rows to Parquet. Now the bulk insert operation can write the incoming Spark rows directly to Parquet files using Spark’s native Parquet writers. This makes the bulk insert performance very similar to direct Parquet writes through Apache Spark. The optimization is disabled by default. To enable it, set the hoodie.datasource.write.row.writer.enable configuration property to true when you perform the bulk insert.
We compared the bulk insert performance with hoodie.datasource.write.row.writer.enable set to true and hoodie.datasource.write.row.writer.enable set to false (the default). We used the bulk insert operation to create a new Hudi dataset from a 1 TB Parquet dataset on Amazon S3. For our testing, we used an EMR cluster with 11 c5.4xlarge instances . The bulk insert was three times faster when the property was set to true. The operation was complete in 155 minutes, compared to 465 minutes when the property was set to false.

Use Apache Hudi on Amazon EMR with AWS Database Migration Service
Apache Hudi recently added support for AWS Database Migration Service (AWS DMS). Using this integration, you can now ingest data from upstream relational databases to your Amazon S3 data lakes in a seamless, efficient, and continuous manner. You simply configure AWS DMS to deliver the CDC data to Amazon S3 as a target and Apache Hudi to pick up the CDC data from Amazon S3 and apply it to the target table. For more information, see the Apply record level changes from relational databases to Amazon S3 data lake using Apache Hudi on Amazon EMR and AWS Database Migration Service blog post.
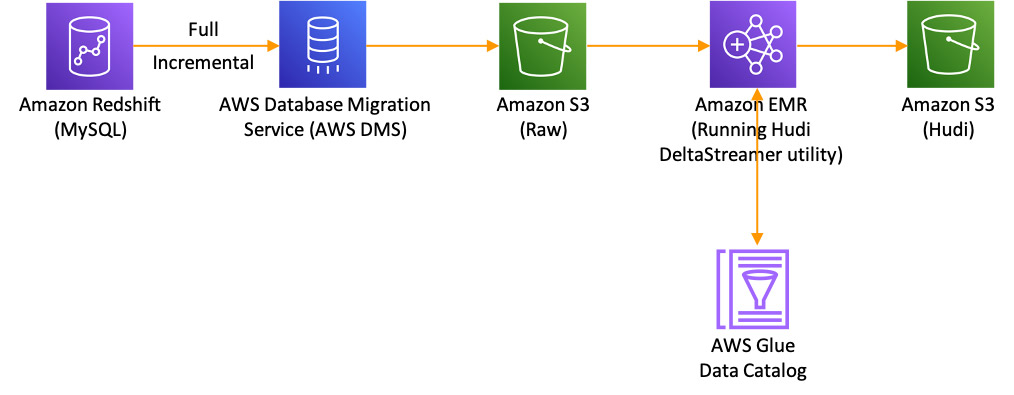
The example in the blog post shows how can use Apache Hudi’s DeltaStreamer utility to start a job that converts a CDC log created by AWS DMS into an Apache Hudi dataset.
Query your Apache Hudi dataset from Amazon Athena and Amazon Redshift Spectrum
Apache Hudi has been integrated with AWS Glue Data Catalog since the time it was added to Amazon EMR in release 5.28. This allows AWS Glue Data Catalog to be used as the metastore for Apache Hive, Presto and Trino tables created with Hudi. This means you can simply launch an EMR cluster configured to use AWS Glue Data Catalog, and query their existing Hudi tables through Apache Spark, Apache Hive, Presto and Trino. Additionally, you can now execute read optimized queries on your Apache Hudi datasets from Amazon Athena and Amazon Redshift Spectrum. For Copy on Write datasets, this means you can query the latest committed snapshot available at the time query execution was started. For Merge on Read datasets, this means you can query the data as of the latest commit or compaction action, which ignores the latest updates appended to not-yet-compacted delta files. Using these services, you can create a table that references your Hudi datasets on Amazon S3 or use already created tables in the AWS Glue Data Catalog and query them using SQL. Hudi supports snapshot isolation, which means you can query data that has been committed before the query starts executing without picking up any in-progress or not-yet-committed changes. You can continue to use Apache Hudi support in Amazon EMR to make changes to the dataset at the same time it is being queried by Amazon Athena and Amazon Redshift Spectrum.
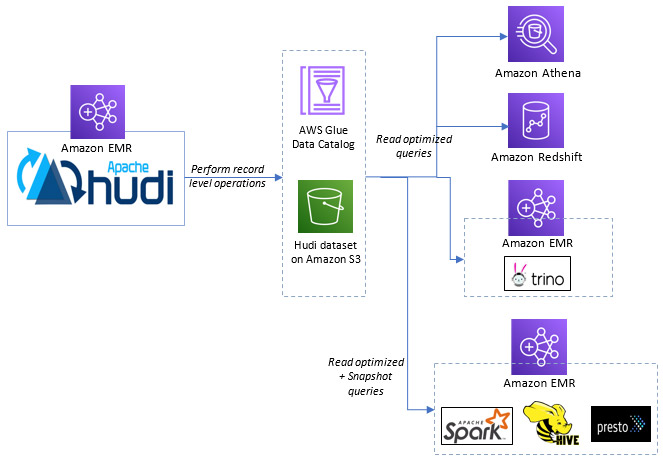
Other new features available in Apache Hudi release 0.6.0 with Amazon EMR
The 0.6.0 release of Apache Hudi also includes other useful features:
- Snapshot query support for MOR tables from Presto and Apache Spark DataSource: Before this release, you could only run a read-optimized query from Presto or Spark DataSource. It would use the data from a MOR table as of the last commit or compaction action and ignored the latest updates appended to the delta files that had not been compacted. You can now run snapshot queries on MOR tables via both Presto and Hudi’s DataSource implementation. In the case of a MOR table, a snapshot query provides the up-to-date results by merging the base and delta files of the latest file slice on the fly.
- Asynchronous compaction for Structured Streaming in Apache Spark: Apache Hudi provides a DeltaStreamer tool that performs compactions asynchronously so that the main ingestion process can run continuously without getting blocked. In this release, Hudi also supports asynchronous compactions when writing data using Spark Streaming. By default, whether you use DeltaStreamer or Spark Streaming, your ingestion job runs continuously and writes out compaction plans that are then read by a background process that performs the compaction.
- Ingesting multiple tables through a single job: When you’re building a CDC pipeline for existing or newly created relational databases, you need a simplified onboarding process for multiple tables. This feature makes it possible to ingest multiple tables to a Hudi dataset through a single job with the DeltaStreamer tool. This feature currently supports the COPY_ON_WRITE storage type only and the ingestion is done in a sequential way. For information about configuring this feature, see the Ingest multiple tables through a single job blog post.
Conclusion
These new features allow you to easily build your CDC pipelines using Apache Hudi with Amazon EMR in a streamlined and efficient manner and query your dataset from your preferred query engine, Apache Spark, Presto, Apache Hive, Trino, Amazon Redshift Spectrum, or Amazon Athena.
About the Author
 Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi committer. He works on cutting-edge features of EMR and is also involved in open source projects such as Apache Hudi, Apache Spark, Apache Hadoop and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch and hang out with friends.
Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi committer. He works on cutting-edge features of EMR and is also involved in open source projects such as Apache Hudi, Apache Spark, Apache Hadoop and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch and hang out with friends.