AWS Big Data Blog
Category: Storage
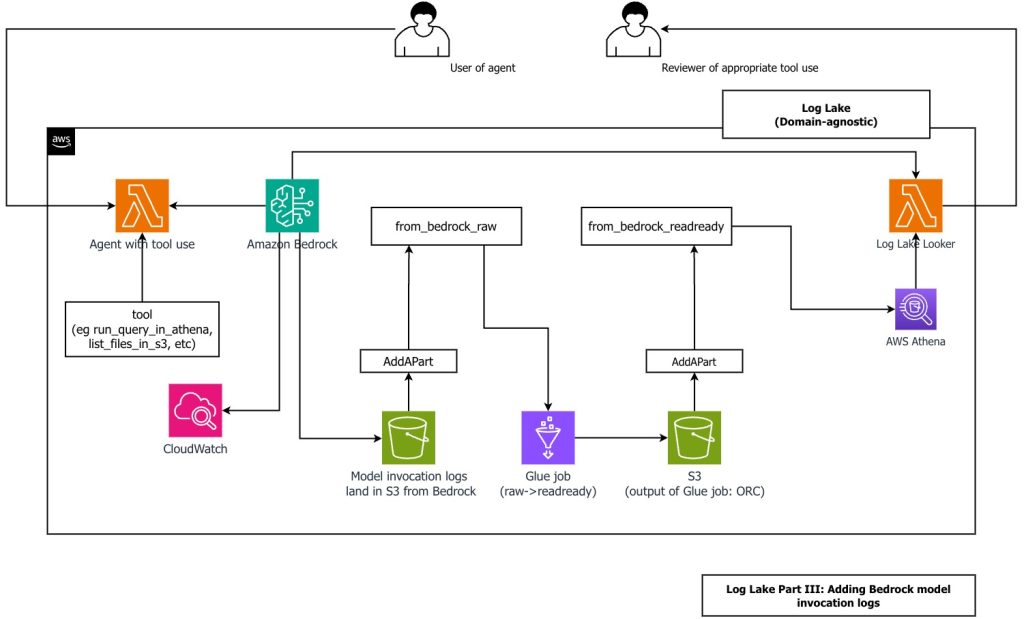
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.
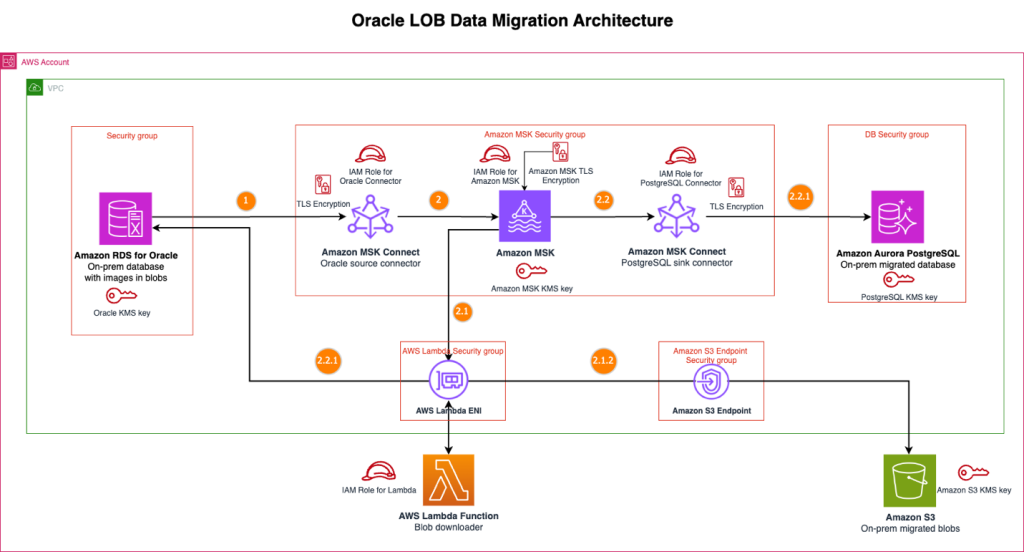
Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3
In this post, we present a scalable solution that addresses the challenge of migrating your large binary objects (LOBs) from Oracle to AWS by using a streaming architecture that separates LOB storage from structured data. This approach avoids size constraints, reduces Oracle licensing costs, and preserves data integrity throughout extended migration periods.

How Taxbit achieved cost savings and faster processing times using Amazon S3 Tables
In this post, we discuss how Taxbit partnered with Amazon Web Services (AWS) to streamline their crypto tax analytics solution using Amazon S3 Tables, achieving 82% cost savings and five times faster processing times.

Best practices for querying Apache Iceberg data with Amazon Redshift
In this post, we discuss the best practices that you can follow while querying Apache Iceberg data with Amazon Redshift

SAP data ingestion and replication with AWS Glue zero-ETL
AWS Glue zero-ETL with SAP now supports data ingestion and replication from SAP data sources such as Operational Data Provisioning (ODP) managed SAP Business Warehouse (BW) extractors, Advanced Business Application Programming (ABAP), Core Data Services (CDS) views, and other non-ODP data sources. Zero-ETL data replication and schema synchronization writes extracted data to AWS services like Amazon Redshift, Amazon SageMaker lakehouse, and Amazon S3 Tables, alleviating the need for manual pipeline development. In this post, we show how to create and monitor a zero-ETL integration with various ODP and non-ODP SAP sources.

Medidata’s journey to a modern lakehouse architecture on AWS
In this post, we show you how Medidata created a unified, scalable, real-time data platform that serves thousands of clinical trials worldwide with AWS services, Apache Iceberg, and a modern lakehouse architecture.

Accelerate data lake operations with Apache Iceberg V3 deletion vectors and row lineage
In this post, we walk you through the new capabilities in Iceberg V3, explain how deletion vectors and row lineage address these challenges, explore real-world use cases across industries, and provide practical guidance on implementing Iceberg V3 features across AWS analytics, catalog, and storage services.

Getting started with Apache Iceberg write support in Amazon Redshift
In this post, we show how you can use Amazon Redshift to write data directly to Apache Iceberg tables stored in Amazon S3 and S3 Tables for seamless integration between your data warehouse and data lake while maintaining ACID compliance.

Getting started with Amazon S3 Tables in Amazon SageMaker Unified Studio
In this post, you learn how to integrate SageMaker Unified Studio with S3 Tables and query your data using Amazon Athena, Amazon Redshift, or Apache Spark in EMR and AWS Glue.

Cross-account lakehouse governance with Amazon S3 Tables and SageMaker Catalog
In this post, we walk you through a practical solution for secure, efficient cross-account data sharing and analysis. You’ll learn how to set up cross-account access to S3 Tables using federated catalogs in Amazon SageMaker, perform unified queries across accounts with Amazon Athena in Amazon SageMaker Unified Studio, and implement fine-grained access controls at the column level using AWS Lake Formation.