AWS Big Data Blog
Doing more with less: Moving from transactional to stateful batch processing
Amazon processes hundreds of millions of financial transactions each day, including accounts receivable, accounts payable, royalties, amortizations, and remittances, from over a hundred different business entities. All of this data is sent to the eCommerce Financial Integration (eCFI) systems, where they are recorded in the subledger.
Ensuring complete financial reconciliation at this scale is critical to day-to-day accounting operations. With transaction volumes exhibiting double-digit percentage growth each year, we found that our legacy transactional-based financial reconciliation architecture proved too expensive to scale and lacked the right level of visibility for our operational needs.
In this post, we show you how we migrated to a batch processing system, built on AWS, that consumes time-bounded batches of events. This not only reduced costs by almost 90%, but also improved visibility into our end-to-end processing flow. The code used for this post is available on GitHub.
Legacy architecture
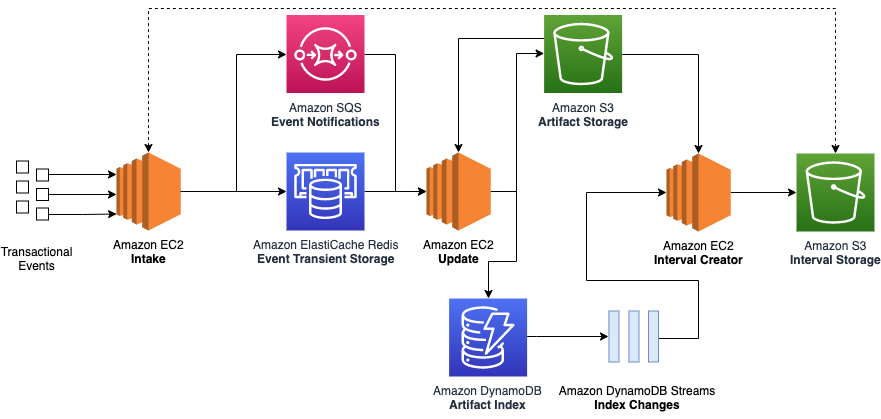
Our legacy architecture primarily utilized Amazon Elastic Compute Cloud (Amazon EC2) to group related financial events into stateful artifacts. However, a stateful artifact could refer to any persistent artifact, such as a database entry or an Amazon Simple Storage Service (Amazon S3) object.
We found this approach resulted in deficiencies in the following areas:
- Cost – Individually storing hundreds of millions of financial events per day in Amazon S3 resulted in high I/O and Amazon EC2 compute resource costs.
- Data completeness – Different events flowed through the system at different speeds. For instance, while a small stateful artifact for a single customer order could be recorded in a couple of seconds, the stateful artifact for a bulk shipment containing a million lines might require several hours to update fully. This made it difficult to know whether all the data had been processed for a given time range.
- Complex retry mechanisms – Financial events were passed between legacy systems using individual network calls, wrapped in a backoff retry strategy. Still, network timeouts, throttling, or traffic spikes could result in some events erroring out. This required us to build a separate service to sideline, manage, and retry problematic events at a later date.
- Scalability – Bottlenecks occurred when different events competed to update the same stateful artifact. This resulted in excessive retries or redundant updates, making it less cost-effective as the system grew.
- Operational support – Using dedicated EC2 instances meant that we needed to take valuable development time to manage OS patching, handle host failures, and schedule deployments.
The following diagram illustrates our legacy architecture.
Evolution is key
Our new architecture needed to address the deficiencies while preserving the core goal of our service: update stateful artifacts based on incoming financial events. In our case, a stateful artifact refers to a group of related financial transactions used for reconciliation. We considered the following as part of the evolution of our stack:
- Stateless and stateful separation
- Minimized end-to-end latency
- Scalability
Stateless and stateful separation
In our transactional system, each ingested event results in an update to a stateful artifact. This became a problem when thousands of events came in all at once for the same stateful artifact.
However, by ingesting batches of data, we had the opportunity to create separate stateless and stateful processing components. The stateless component performs an initial reduce operation on the input batch to group together related events. This meant that the rest of our system could operate on these smaller stateless artifacts and perform fewer write operations (fewer operations means lower costs).
The stateful component would then join these stateless artifacts with existing stateful artifacts to produce an updated stateful artifact.
As an example, imagine an online retailer suddenly received thousands of purchases for a popular item. Instead of updating an item database entry thousands of times, we can first produce a single stateless artifact that summaries the latest purchases. The item entry can now be updated one time with the stateless artifact, reducing the update bottleneck. The following diagram illustrates this process.

Minimized end-to-end latency
Unlike traditional extract, transform, and load (ETL) jobs, we didn’t want to perform daily or even hourly extracts. Our accountants need to be able to access the updated stateful artifacts within minutes of data arriving in our system. For instance, if they had manually sent a correction line, they wanted to be able to check within the same hour that their adjustment had the intended effect on the targeted stateful artifact instead of waiting until the next day. As such, we focused on parallelizing the incoming batches of data as much as possible by breaking down the individual tasks of the stateful component into subcomponents. Each subcomponent could run independently of each other, which allowed us to process multiple batches in an assembly line format.
Scalability
Both the stateless and stateful components needed to respond to shifting traffic patterns and possible input batch backlogs. We also wanted to incorporate serverless compute to better respond to scale while reducing the overhead of maintaining an instance fleet.
This meant we couldn’t simply have a one-to-one mapping between the input batch and stateless artifact. Instead, we built flexibility into our service so the stateless component could automatically detect a backlog of input batches and group multiple input batches together in one job. Similar backlog management logic was applied to the stateful component. The following diagram illustrates this process.

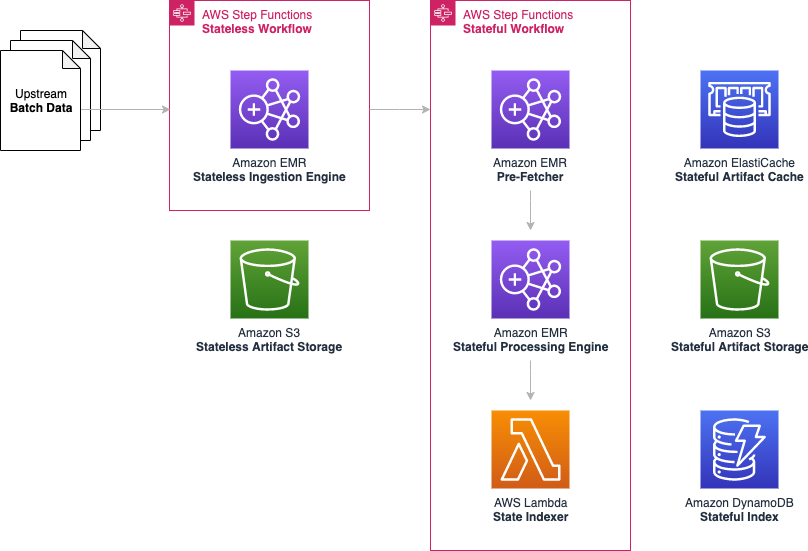
Current architecture
To meet our needs, we combined multiple AWS products:
- AWS Step Functions – Orchestration of our stateless and stateful workflows
- Amazon EMR – Apache Spark operations on our stateless and stateful artifacts
- AWS Lambda – Stateful artifact indexing and orchestration backlog management
- Amazon ElastiCache – Optimizing Amazon S3 request latency
- Amazon S3 – Scalable storage of our stateless and stateful artifacts
- Amazon DynamoDB – Stateless and stateful artifact index
The following diagram illustrates our current architecture.
The following diagram shows our stateless and stateful workflow.

The AWS CloudFormation template to render this architecture and corresponding Java code is available in the following GitHub repo.
Stateless workflow
We used an Apache Spark application on a long-running Amazon EMR cluster to simultaneously ingest input batch data and perform reduce operations to produce the stateless artifacts and a corresponding index file for the stateful processing to use.
We chose Amazon EMR for its proven highly available data-processing capability in a production setting and also its ability to horizontally scale when we see increased traffic loads. Most importantly, Amazon EMR had lower cost and better operational support when compared to a self-managed cluster.
Stateful workflow
Each stateful workflow performs operations to create or update millions of stateful artifacts using the stateless artifacts. Similar to the stateless workflows, all stateful artifacts are stored in Amazon S3 across a handful of Apache Spark part-files. This alone resulted in a huge cost reduction, because we significantly reduced the number of Amazon S3 writes (while using the same amount of overall storage). For instance, storing 10 million individual artifacts using the transactional legacy architecture would cost $50 in PUT requests alone, whereas 10 Apache Spark part-files would cost only $0.00005 in PUT requests (based on $0.005 per 1,000 requests).
However, we still needed a way to retrieve individual stateful artifacts, because any stateful artifact could be updated at any point in the future. To do this, we turned to DynamoDB. DynamoDB is a fully managed and scalable key-value and document database. It’s ideal for our access pattern because we wanted to index the location of each stateful artifact in the stateful output file using its unique identifier as a primary key. We used DynamoDB to index the location of each stateful artifact within the stateful output file. For instance, if our artifact represented orders, we would use the order ID (which has high cardinality) as the partition key, and store the file location, byte offset, and byte length of each order as separate attributes. By passing the byte-range in Amazon S3 GET requests, we can now fetch individual stateful artifacts as if they were stored independently. We were less concerned about optimizing the number of Amazon S3 GET requests because the GET requests are over 10 times cheaper than PUT requests.
Overall, this stateful logic was split across three serial subcomponents, which meant that three separate stateful workflows could be operating at any given time.
Pre-fetcher
The following diagram illustrates our pre-fetcher subcomponent.

The pre-fetcher subcomponent uses the stateless index file to retrieve pre-existing stateful artifacts that should be updated. These might be previous shipments for the same customer order, or past inventory movements for the same warehouse. For this, we turn once again to Amazon EMR to perform this high-throughput fetch operation.
Each fetch required a DynamoDB lookup and an Amazon S3 GET partial byte-range request. Due to the large number of external calls, fetches were highly parallelized using a thread pool contained within an Apache Spark flatMap operation. Pre-fetched stateful artifacts were consolidated into an output file that was later used as input to the stateful processing engine.
Stateful processing engine
The following diagram illustrates the stateful processing engine.

The stateful processing engine subcomponent joins the pre-fetched stateful artifacts with the stateless artifacts to produce updated stateful artifacts after applying custom business logic. The updated stateful artifacts are written out across multiple Apache Spark part-files.
Because stateful artifacts could have been indexed at the same time that they were pre-fetched (also called in-flight updates), the stateful processor also joins recently processed Apache Spark part-files.
We again used Amazon EMR here to take advantage of the Apache Spark operations that are required to join the stateless and stateful artifacts.
State indexer
The following diagram illustrates the state indexer.

This Lambda-based subcomponent records the location of each stateful artifact within the stateful part-file in DynamoDB. The state indexer also caches the stateful artifacts in an Amazon ElastiCache for Redis cluster to provide a performance boost in the Amazon S3 GET requests performed by the pre-fetcher.
However, even with a thread pool, a single Lambda function isn’t powerful enough to index millions of stateful artifacts within the 15-minute time limit. Instead, we employ a cluster of Lambda functions. The state indexer begins with a single coordinator Lambda function, which determines the number of worker functions that are needed. For instance, if 100 part-files are generated by the stateful processing engine, then the coordinator might assign five part-files for each of the 20 Lambda worker functions to work on. This method is highly scalable because we can dynamically assign more or fewer Lambda workers as required.
Each Lambda worker then performs the ElastiCache and DynamoDB writes for all the stateful artifacts within each assigned part-file in a multi-threaded manner. The coordinator function monitors the health of each Lambda worker and restarts workers as needed.

Orchestration
We used Step Functions to coordinate each of the stateless and stateful workflows, as shown in the following diagram.

Every time a new workflow step ran, the step was recorded in a DynamoDB table via a Lambda function. This table not only maintained the order in which stateful batches should be run, but it also formed the basis of the backlog management system, which directed the stateless ingestion engine to group more or fewer input batches together depending on the backlog.
We chose Step Functions for its native integration with many AWS services (including triggering by an Amazon CloudWatch scheduled event rule and adding Amazon EMR steps) and its built-in support for backoff retries and complex state machine logic. For instance, we defined different backoff retry rates based on the type of error.
Conclusion
Our batch-based architecture helped us overcome the transactional processing limitations we originally set out to resolve:
- Reduced cost – We have been able to scale to thousands of workflows and hundreds of million events per day using only three or four core nodes per EMR cluster. This reduced our Amazon EC2 usage by over 90% when compared with a similar transactional system. Additionally, writing out batches instead of individual transactions reduced the number of Amazon S3 PUT requests by over 99.8%.
- Data completeness guarantees – Because each input batch is associated with a time interval, when a batch has finished processing, we know that all events in that time interval have been completed.
- Simplified retry mechanisms – Batch processing means that failures occur at the batch level and can be retried directly through the workflow. Because there are far fewer batches than transactions, batch retries are much more manageable. For instance, in our service, a typical batch contains about two million entries. During a service outage, only a single batch needs to be retried, as opposed to two million individual entries in the legacy architecture.
- High scalability – We’ve been impressed with how easy it is to scale our EMR clusters on the fly if we detect an increase in traffic. Using Amazon EMR instance fleets also helps us automatically choose the most cost-effective instances across different Availability Zones. We also like the performance achieved by our Lambda-based state indexer. This subcomponent not only dynamically scales with no human intervention, but has also been surprisingly cost-efficient. A large portion of our usage has fallen within the free tier.
- Operational excellence – Replacing traditional hosts with serverless components such as Lambda allowed us to spend less time on compliance tickets and focus more on delivering features for our customers.
We are particularly excited about the investments we have made moving from a transactional-based system to a batch processing system, especially our shift from using Amazon EC2 to using serverless Lambda and big data Amazon EMR services. This experience demonstrates that even services originally built on AWS can still achieve cost reductions and improve performance by rethinking how AWS services are used.
Inspired by our progress, our team is moving to replace many other legacy services with serverless components. Likewise, we hope that other engineering teams can learn from our experience, continue to innovate, and do more with less.
Find the code used for this post in the following GitHub repository.
Special thanks to development team: Ryan Schwartz, Abhishek Sahay, Cecilia Cho, Godot Bian, Sam Lam, Jean-Christophe Libbrecht, and Nicholas Leong.
About the Authors
 Tom Jin is a Senior Software Engineer for eCommerce Financial Integration (eCFI) at Amazon. His interests include building large-scale systems and applying machine learning to healthcare applications. He is based in Vancouver, Canada and is a fan of ocean conservation.
Tom Jin is a Senior Software Engineer for eCommerce Financial Integration (eCFI) at Amazon. His interests include building large-scale systems and applying machine learning to healthcare applications. He is based in Vancouver, Canada and is a fan of ocean conservation.
 Karthik Odapally is a Senior Solutions Architect at AWS supporting our Gaming Customers. He loves presenting at external conferences like AWS Re:Invent, and helping customers learn about AWS. His passion outside of work is to bake cookies and bread for family and friends here in the PNW. In his spare time, he plays Legend of Zelda (Link’s Awakening) with his 4 yr old daughter.
Karthik Odapally is a Senior Solutions Architect at AWS supporting our Gaming Customers. He loves presenting at external conferences like AWS Re:Invent, and helping customers learn about AWS. His passion outside of work is to bake cookies and bread for family and friends here in the PNW. In his spare time, he plays Legend of Zelda (Link’s Awakening) with his 4 yr old daughter.