AWS Big Data Blog
How Plugsurfing doubled performance and reduced cost by 70% with purpose-built databases and AWS Graviton
Plugsurfing aligns the entire car charging ecosystem—drivers, charging point operators, and carmakers—within a single platform. The over 1 million drivers connected to the Plugsurfing Power Platform benefit from a network of over 300,000 charging points across Europe. Plugsurfing serves charging point operators with a backend cloud software for managing everything from country-specific regulations to providing diverse payment options for customers. Carmakers benefit from white label solutions as well as deeper integrations with their in-house technology. The platform-based ecosystem has already processed more than 18 million charging sessions. Plugsurfing was acquired fully by Fortum Oyj in 2018.
Plugsurfing uses Amazon OpenSearch Service as a central data store to store 300,000 charging stations’ information and to power search and filter requests coming from mobile, web, and connected car dashboard clients. With the increasing usage, Plugsurfing created multiple read replicas of an OpenSearch Service cluster to meet demand and scale. Over time and with the increase in demand, this solution started to become cost exhaustive and limited in terms of cost performance benefit.
AWS EMEA Prototyping Labs collaborated with the Plugsurfing team for 4 weeks on a hands-on prototyping engagement to solve this problem, which resulted in 70% cost savings and doubled the performance benefit over the current solution. This post shows the overall approach and ideas we tested with Plugsurfing to achieve the results.
The challenge: Scaling higher transactions per second while keeping costs under control
One of the key issues of the legacy solution was keeping up with higher transactions per second (TPS) from APIs while keeping costs low. The majority of the cost was coming from the OpenSearch Service cluster, because the mobile, web, and EV car dashboards use different APIs for different use cases, but all query the same cluster. The solution to achieve higher TPS with the legacy solution was to scale the OpenSearch Service cluster.
The following figure illustrates the legacy architecture.

Plugsurfing APIs are responsible for serving data for four different use cases:
- Radius search – Find all the EV charging stations (latitude/longitude) with in x km radius from the point of interest (or current location on GPS).
- Square search – Find all the EV charging stations within a box of length x width, where the point of interest (or current location on GPS) is at the center.
- Geo clustering search – Find all the EV charging stations clustered (grouped) by their concentration within a given area. For example, searching all EV chargers in all of Germany results in something like 50 in Munich and 100 in Berlin.
- Radius search with filtering – Filter the results by EV charger that are available or in use by plug type, power rating, or other filters.
The OpenSearch Service domain configuration was as follows:
- m4.10xlarge.search x 4 nodes
- Elasticsearch 7.10 version
- A single index to store 300,000 EV charger locations with five shards and one replica
- A nested document structure
The following code shows the example document
Solution overview
AWS EMEA Prototyping Labs proposed an experimentation approach to try three high-level ideas for performance optimization and to lower overall solution costs.
We launched an Amazon Elastic Compute Cloud (EC2) instance in a prototyping AWS account to host a benchmarking tool based on k6 (an open-source tool that makes load testing simple for developers and QA engineers) Later, we used scripts to dump and restore production data to various databases, transforming it to fit with different data models. Then we ran k6 scripts to run and record performance metrics for each use case, database, and data model combination. We also used the AWS Pricing Calculator to estimate the cost of each experiment.
Experiment 1: Use AWS Graviton and optimize OpenSearch Service domain configuration
We benchmarked a replica of the legacy OpenSearch Service domain setup in a prototyping environment to baseline performance and costs. Next, we analyzed the current cluster setup and recommended testing the following changes:
- Use AWS Graviton based memory optimized EC2 instances (r6g) x 2 nodes in the cluster
- Reduce the number of shards from five to one, given the volume of data (all documents) is less than 1 GB
- Increase the refresh interval configuration from the default 1 second to 5 seconds
- Denormalize the full document; if not possible, then denormalize all the fields that are part of the search query
- Upgrade to Amazon OpenSearch Service 1.0 from Elasticsearch 7.10
Plugsurfing created multiple new OpenSearch Service domains with the same data and benchmarked them against the legacy baseline to obtain the following results. The row in yellow represents the baseline from the legacy setup; the rows with green represent the best outcome out of all experiments performed for the given use cases.
| DB Engine | Version | Node Type | Nodes in Cluster | Configurations | Data Modeling | Radius req/sec | Filtering req/sec | Performance Gain % |
| Elasticsearch | 7.1 | m4.10xlarge | 4 | 5 shards, 1 replica | Nested | 2841 | 580 | 0 |
| Amazon OpenSearch Service | 1.0 | r6g.xlarge | 2 | 1 shards, 1 replica | Nested | 850 | 271 | 32.77 |
| Amazon OpenSearch Service | 1.0 | r6g.xlarge | 2 | 1 shards, 1 replica | Denormalized | 872 | 670 | 45.07 |
| Amazon OpenSearch Service | 1.0 | r6g.2xlarge | 2 | 1 shards, 1 replica | Nested | 1667 | 474 | 62.58 |
| Amazon OpenSearch Service | 1.0 | r6g.2xlarge | 2 | 1 shards, 1 replica | Denormalized | 1993 | 1268 | 95.32 |
Plugsurfing was able to gain 95% (doubled) better performance across the radius and filtering use cases with this experiment.
Experiment 2: Use purpose-built databases on AWS for different use cases
We tested Amazon OpenSearch Service, Amazon Aurora PostgreSQL-Compatible Edition, and Amazon DynamoDB extensively with many data models for different use cases.
We tested the square search use case with an Aurora PostgreSQL cluster with a db.r6g.2xlarge single node as the reader and a db.r6g.large single node as the writer. The square search used a single PostgreSQL table configured via the following steps:
- Create the geo search table with geography as the data type to store latitude/longitude:
- Create an index on the geog field:
- Query the data for the square search use case:
We achieved an eight-times greater improvement in TPS for the square search use case, as shown in the following table.
| DB Engine | Version | Node Type | Nodes in Cluster | Configurations | Data modeling | Square req/sec | Performance Gain % |
| Elasticsearch | 7.1 | m4.10xlarge | 4 | 5 shards, 1 replica | Nested | 412 | 0 |
| Aurora PostgreSQL | 13.4 | r6g.large | 2 | PostGIS, Denormalized | Single table | 881 | 213.83 |
| Aurora PostgreSQL | 13.4 | r6g.xlarge | 2 | PostGIS, Denormalized | Single table | 1770 | 429.61 |
| Aurora PostgreSQL | 13.4 | r6g.2xlarge | 2 | PostGIS, Denormalized | Single table | 3553 | 862.38 |
We tested the geo clustering search use case with a DynamoDB model. The partition key (PK) is made up of three components: <zoom-level>:<geo-hash>:<api-key>, and the sort key is the EV charger current status. We examined the following:
- The zoom level of the map set by the user
- The geo hash computed based on the map tile in the user’s view port area (at every zoom level, the map of Earth is divided into multiple tiles, where each tile can be represented as a geohash)
- The API key to identify the API user
| Partition Key: String | Sort Key: String | total_pins: Number | filter1_pins: Number | filter2_pins: Number | filter3_pins: Number |
| 5:gbsuv:api_user_1 | Available | 100 | 50 | 67 | 12 |
| 5:gbsuv:api_user_1 | in-use | 25 | 12 | 6 | 1 |
| 6:gbsuvt:api_user_1 | Available | 35 | 22 | 8 | 0 |
| 6:gbsuvt:api_user_1 | in-use | 88 | 4 | 0 | 35 |
The writer updates the counters (increment or decrement) against each filter condition and charger status whenever the EV charger status is updated at all zoom levels. With this model, the reader can query pre-clustered data with a single direct partition hit for all the map tiles viewable by the user at the given zoom level.
The DynamoDB model helped us gain a 45-times greater read performance for our geo clustering use case. However, it also added extra work on the writer side to pre-compute numbers and update multiple rows when the status of a single EV charger is updated. The following table summarizes our results.
| DB Engine | Version | Node Type | Nodes in Cluster | Configurations | Data modeling | Clustering req/sec | Performance Gain % |
| Elasticsearch | 7.1 | m4.10xlarge | 4 | 5 shards, 1 replica | Nested | 22 | 0 |
| DynamoDB | NA | Serverless | 0 | 100 WCU, 500 RCU | Single table | 1000 | 4545.45 |
Experiment 3: Use AWS Lambda@Edge and AWS Wavelength for better network performance
We recommended that Plugsurfing use Lambda@Edge and AWS Wavelength to optimize network performance by shifting some of the APIs at the edge to closer to the user. The EV car dashboard can use the same 5G network connectivity to invoke Plugsurfing APIs with AWS Wavelength.
Post-prototype architecture
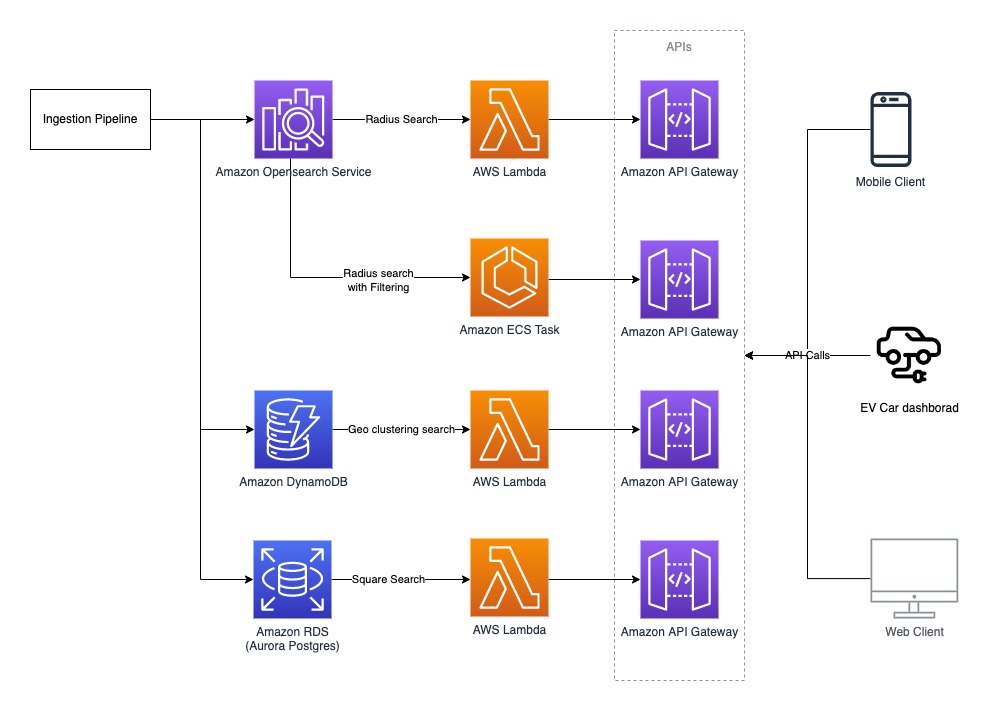
The post-prototype architecture used purpose-built databases on AWS to achieve better performance across all four use cases. We looked at the results and split the workload based on which database performs best for each use case. This approach optimized performance and cost, but added complexity on readers and writers. The final experiment summary represents the database fits for the given use cases that provide the best performance (highlighted in orange).
Plugsurfing has already implemented a short-term plan (light green) as an immediate action post-prototype and plans to implement mid-term and long-term actions (dark green) in the future.
| DB Engine | Node Type | Configurations | Radius req/sec | Radius Filtering req/sec | Clustering req/sec | Square req/sec | Monthly Costs $ | Cost Benefit % | Performance Gain % |
| Elasticsearch 7.1 | m4.10xlarge x4 | 5 shards | 2841 | 580 | 22 | 412 | 9584,64 | 0 | 0 |
| Amazon OpenSearch Service 1.0 | r6g.2xlarge x2 |
1 shard Nested |
1667 | 474 | 34 | 142 | 1078,56 | 88,75 | -39,9 |
| Amazon OpenSearch Service 1.0 | r6g.2xlarge x2 | 1 shard | 1993 | 1268 | 125 | 685 | 1078,56 | 88,75 | 5,6 |
| Aurora PostgreSQL 13.4 | r6g.2xlarge x2 | PostGIS | 0 | 0 | 275 | 3553 | 1031,04 | 89,24 | 782,03 |
| DynamoDB | Serverless |
100 WCU 500 RCU |
0 | 0 | 1000 | 0 | 106,06 | 98,89 | 4445,45 |
| Summary | . | . | 2052 | 1268 | 1000 | 3553 | 2215,66 | 76,88 | 104,23 |
The following diagram illustrates the updated architecture.
Conclusion
Plugsurfing was able to achieve a 70% cost reduction over their legacy setup with two-times better performance by using purpose-built databases like DynamoDB, Aurora PostgreSQL, and AWS Graviton based instances for Amazon OpenSearch Service. They achieved the following results:
- The radius search and radius search with filtering use cases achieved better performance using Amazon OpenSearch Service on AWS Graviton with a denormalized document structure
- The square search use case performed better using Aurora PostgreSQL, where we used the PostGIS extension for geo square queries
- The geo clustering search use case performed better using DynamoDB
Learn more about AWS Graviton instances and purpose-built databases on AWS, and let us know how we can help optimize your workload on AWS.
About the Author
 Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS Analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using art-of-the-possible technology. He enjoys beaches in his leisure time.
Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS Analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using art-of-the-possible technology. He enjoys beaches in his leisure time.