AWS Big Data Blog
How Novo Nordisk built distributed data governance and control at scale
This is a guest post co-written with Jonatan Selsing and Moses Arthur from Novo Nordisk.
This is the second post of a three-part series detailing how Novo Nordisk, a large pharmaceutical enterprise, partnered with AWS Professional Services to build a scalable and secure data and analytics platform. The first post of this series describes the overall architecture and how Novo Nordisk built a decentralized data mesh architecture, including Amazon Athena as the data query engine. The third post will show how end-users can consume data from their tool of choice, without compromising data governance. This will include how to configure Okta, AWS Lake Formation, and a business intelligence tool to enable SAML-based federated use of Athena for an enterprise BI activity.
When building a scalable data architecture on AWS, giving autonomy and ownership to the data domains are crucial for the success of the platform. By providing the right mix of freedom and control to those people with the business domain knowledge, your business can maximize value from the data as quickly and effectively as possible. The challenge facing organizations, however, is how to provide the right balance between freedom and control. At the same time, data is a strategic asset that needs to be protected with the highest degree of rigor. How can organizations strike the right balance between freedom and control?
In this post, you will learn how to build decentralized governance with Lake Formation and AWS Identity and Access Management (IAM) using attribute-based access control (ABAC). We discuss some of the patterns we use, including Amazon Cognito identity pool federation using ABAC in permission policies, and Okta-based SAML federation with ABAC enforcement on role trust policies.
Solution overview
In the first post of this series, we explained how Novo Nordisk and AWS Professional Services built a modern data architecture based on data mesh tenets. This architecture enables data governance on distributed data domains, using an end-to-end solution to create data products and providing federated data access control. This post dives into three elements of the solution:
- How IAM roles and Lake Formation are used to manage data access across data domains
- How data access control is enforced at scale, using a group membership mapping with an ABAC pattern
- How the system maintains state across the different layers, so that the ecosystem of trust is configured appropriately
From the end-user perspective, the objective of the mechanisms described in this post is to enable simplified data access from the different analytics services adopted by Novo Nordisk, such as those provided by software as a service (SaaS) vendors like Databricks, or self-hosted ones such as JupyterHub. At the same time, the platform must guarantee that any change in a dataset is immediately reflected at the service user interface. The following figure illustrates at a high level the expected behavior.
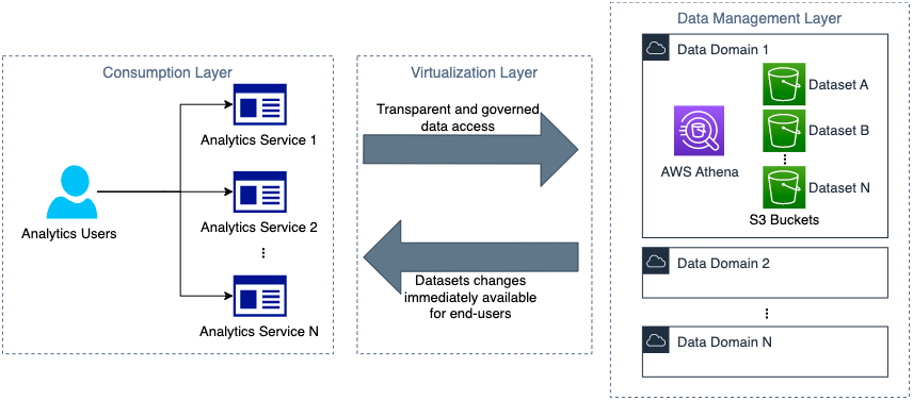
Following the layer nomenclature established in the first post, the services are created and managed in the consumption layer. The domain accounts are created and managed in the data management layer. Because changes can occur from both layers, continuous communication in both directions is required. The state information is kept in the virtualization layer along with the communication protocols. Additionally, at sign-in time, the services need information about data resources required to provide data access abstraction.
Managing data access
The data access control in this architecture is designed around the core principle that all access is encapsulated in isolated IAM role sessions. The layer pattern that we described in the first post ensures that the creation and curation of the IAM role policies involved can be delegated to the different data management ecosystems. Each data management platform integrated can use their own data access mechanisms, with the unique requirement that the data is accessed via specific IAM roles.
To illustrate the potential mechanisms that can be used by data management solutions, we show two examples of data access permission mechanisms used by two different data management solutions. Both systems utilize the same trust policies as described in the following sections, but have a completely different permission space.
Example 1: Identity-based ABAC policies
The first mechanism we discuss is an ABAC role that provides access to a home-like data storage area, where users can share within their departments and with the wider organization in a structure that mimics the organizational structure. Here, we don’t utilize the group names, but instead forward user attributes from the corporate Active Directory directly into the permission policy through claim overrides. We do this by having the corporate Active Directory as the identity provider (IdP) for the Amazon Cognito user pool and mapping the relevant IdP attributes to user pool attributes. Then, in the Amazon Cognito identity pool, we map the user pool attributes to session tags to use them for access control. Custom overrides can be included in the claim mapping, through the use of a pre token generation Lambda trigger. This way, claims from AD can be mapped to Amazon Cognito user pool attributes and then ultimately used in the Amazon Cognito identity pool to control IAM role permissions. The following is an example of an IAM policy with sessions tags:
This role is then embedded in the analytics layer (together with the data domain roles) and assumed on behalf of the user. This enables users to mix and match between data domains—as well as utilizing private and public data paths that aren’t necessarily tied to any data domain. For more examples of how ABAC can be used with permission policies, refer to How to scale your authorization needs by using attribute-based access control with S3.
Example 2: Lake Formation name-based access controls
In the data management solution named Novo Nordisk Enterprise Datahub (NNEDH), which we introduced in the first post, we use Lake Formation to enable standardized data access. The NNEDH datasets are registered in the Lake Formation Data Catalog as databases and tables, and permissions are granted using the named resource method. The following screenshot shows an example of these permissions.
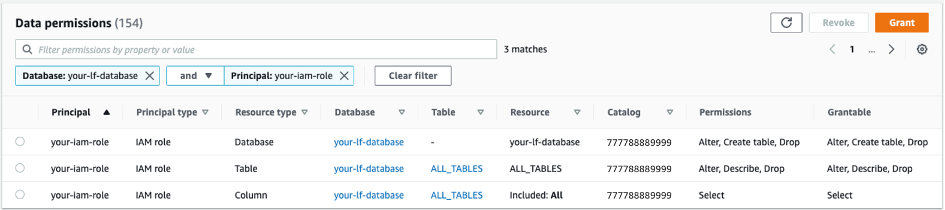
In this approach, data access governance is delegated to Lake Formation. Every data domain in NNEDH has isolated permissions synthesized by NNEDH as the central governance management layer. This is a similar pattern to what is adopted for other domain-oriented data management solutions. Refer to Use an event-driven architecture to build a data mesh on AWS for an example of tag-based access control in Lake Formation.
These patterns don’t exclude implementations of peer-to-peer type data sharing mechanisms, such as those that can be achieved using AWS Resource Access Manager (AWS RAM), where a single IAM role session can have permissions that span across accounts.
Delegating role access to the consumption later
The following figure illustrates the data access workflow from an external service.

The workflow steps are as follows:
- A user authenticates on an IdP used by the analytics tool that they are trying to access. A wide range of analytics tools are supported by Novo Nordisk platform, such as Databricks and JupyterHub, and the IdP can be either SAML or OIDC type depending on the capabilities of the third-party tool. In this example, an Okta SAML application is used to sign into a third-party analytics tool, and an IAM SAML IdP is configured in the data domain AWS account to federate with the external IdP. The third post of this series describes how to set up an Okta SAML application for IAM role federation on Athena.
- The SAML assertion obtained during the sign-in process is used to request temporary security credentials of an IAM role through the AssumeRole operation. In this example, the SAML assertion is used on
AssumeRoleWithSAMLoperation. For OpenID Connect-compatible IdPs, the operationAssumeRoleWithWebIdentitymust be used with the JWT. The SAML attributes in the assertion or the claims in the token can be generated at sign-in time, to ensure that the group memberships are forwarded, for the ABAC policy pattern described in the following sections. - The analytics tool, such as Databricks or JupyterHub, abstracts the usage of the IAM role session credentials in the tool itself, and data can be accessed directly according to the permissions of the IAM role assumed. This pattern is similar in nature to IAM passthrough as implemented by Databricks, but in Novo Nordisk it’s extended across all analytics services. In this example, the analytics tool accesses the data lake on Amazon Simple Storage Service (Amazon S3) through Athena queries.
As the data mesh pattern expands across domains covering more downstream services, we need a mechanism to keep IdPs and IAM role trusts continuously updated. We come back to this part later in the post, but first we explain how role access is managed at scale.
Attribute-based trust policies
In previous sections, we emphasized that this architecture relies on IAM roles for data access control. Each data management platform can implement its own data access control method using IAM roles, such as identity-based policies or Lake Formation access control. For data consumption, it’s crucial that these IAM roles are only assumable by users that are part of Active Directory groups with the appropriate entitlements to use the role. To implement this at scale, the IAM role’s trust policy uses ABAC.
When a user authenticates on the external IdP of the consumption layer, we add in the access token a claim derived from their Active Directory groups. This claim is propagated by theAssumeRoleoperation into the trust policy of the IAM role, where it is compared with the expected Active Directory group. Only users that belong to the expected groups can assume the role. This mechanism is illustrated in the following figure.
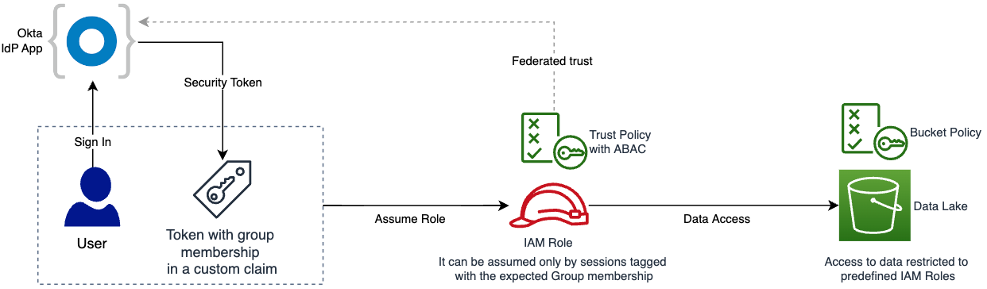
Translating group membership to attributes
To enforce the group membership entitlement at the role assumption level, we need a way to compare the required group membership with the group memberships that a user comes with in their IAM role session. To achieve this, we use a form of ABAC, where we have a way to represent the sum of context-relevant group memberships in a single attribute. A single IAM role session tag value is limited to 256 characters. The corresponding limit for SAML assertions is 100,000 characters, so for systems where a very large number of either roles or group-type mappings are required, SAML can support a wider range of configurations.
In our case, we have opted for a compression algorithm that takes a group name and compresses it to a 4-character string hash. This means that, together with a group-separation character, we can fit 51 groups in a single attribute. This gets pushed down to approximately 20 groups for OIDC type role assumption due to the PackedPolicySize, but is higher for a SAML-based flow. This has shown to be sufficient for our case. There is a risk that two different groups could hash to the same character combination; however, we have checked that there are no collisions in the existing groups. To mitigate this risk going forward, we have introduced guardrails in multiples places. First, before adding new groups entitlements in the virtualization layer, we check if there’s a hash collision with any existing group. When a duplicated group is attempted to be added, our service team is notified and we can react accordingly. But as stated earlier, there is a low probability of clashes, so the flexibility this provides outweighs the overhead associated with managing clashes (we have not had any yet). We additionally enforce this at SAML assertion creation time as well, to ensure that there are no duplicated groups in the users group list, and in cases of duplication, we remove both entirely. This means malicious actors can at most limit the access of other users, but not gain unauthorized access.
Enforcing audit functionality across sessions
As mentioned in the first post, on top of governance, there are strict requirements around auditability of data accesses. This means that for all data access requests, it must be possible to trace the specific user across services and retain this information. We achieve this by setting (and enforcing) a source identity for all role sessions and make sure to propagate enterprise identity to this attribute. We use a combination of Okta inline hooks and SAML session tags to achieve this. This means that the AWS CloudTrail logs for an IAM role session have the following information:
On the IAM role level, we can enforce the required attribute configuration with the following example trust policy. This is an example for a SAML-based app. We support the same patterns through OpenID Connect IdPs.
We now go through the elements of an IAM role trust policy, based on the following example:
The policy contains the following details:
- The
Principalstatement should point to the list of apps that are served through the consumption layer. These can be Azure app registrations, Okta apps, or Amazon Cognito app clients. This means that SAML assertions (in the case of SAML-based flows) minted from these applications can be used to run the operationAssumeRoleWithSamlif the remaining elements are also satisfied. - The
Actionstatement includes the required permissions for theAssumeRolecall to succeed, including adding the contextual information to the role session. - In the first condition, the audience of the assertion needs to be targeting AWS.
- In the second condition, there are two
StringLikerequirements:- A requirement on the source identity as the naming convention to follow at Novo Nordisk (users must come with enterprise identity, following our audit requirements).
- The
aws:RequestTag/GroupHashneeds to bexxxx, which represents the hashed group name mentioned in the upper section.
- Lastly, we enforce that sessions can’t be started without setting the source identity.
This policy enforces that all calls are from recognized services, include auditability, have the right target, and enforces that the user has the right group memberships.
Building a central overview of governance and trust
In this section, we discuss how Novo Nordisk keeps track of the relevant group-role relations and maps these at sign-in time.
Entitlements
In Novo Nordisk, all accesses are based on Active Directory group memberships. There is no user-based access. Because this pattern is so central, we have extended this access philosophy into our data accesses. As mentioned earlier, at sign-in time, the hooks need to be able to know which roles to assume for a given user, given this user’s group membership. We have modeled this data in Amazon DynamoDB, where just-in-time provisioning ensures that only the required user group memberships are available. By building our application around the use of groups, and by having the group propagation done by the application code, we avoid having to make a more general Active Directory integration, which would, for a company the size of Novo Nordisk, severely impact the application, simply due to the volume of users and groups.
The DynamoDB entitlement table contains all relevant information for all roles and services, including role ARNs and IdP ARNs. This means that when users log in to their analytics services, the sign-in hook can construct the required information for the Roles SAML attribute.
When new data domains are added to the data management layer, the data management layer needs to communicate both the role information and the group name that gives access to the role.
Single sign-on hub for analytics services
When scaling this permission model and data management pattern to a large enterprise such as Novo Nordisk, we ended up creating a large number of IAM roles distributed across different accounts. Then, a solution is required to map and provide access for end-users to the required IAM role. To simplify user access to multiple data sources and analytics tools, Novo Nordisk developed a single sign-on hub for analytics services. From the end-user perspective, this is a web interface that glues together different offerings in a unified system, making it a one-stop tool for data and analytics needs. When signing in to each of the analytical offerings, the authenticated sessions are forwarded, so users never have to reauthenticate.
Common for all the services supported in the consumption layer is that we can run a piece of application code at sign-in time, allowing sign-in time permissions to be calculated. The hooks that achieve this functionality can, for instance, be run by Okta inline hooks. This means that each of the target analytics services can have custom code to translate relevant contextual information or provide other types of automations for the role forwarding.
The sign-in flow is demonstrated in the following figure.
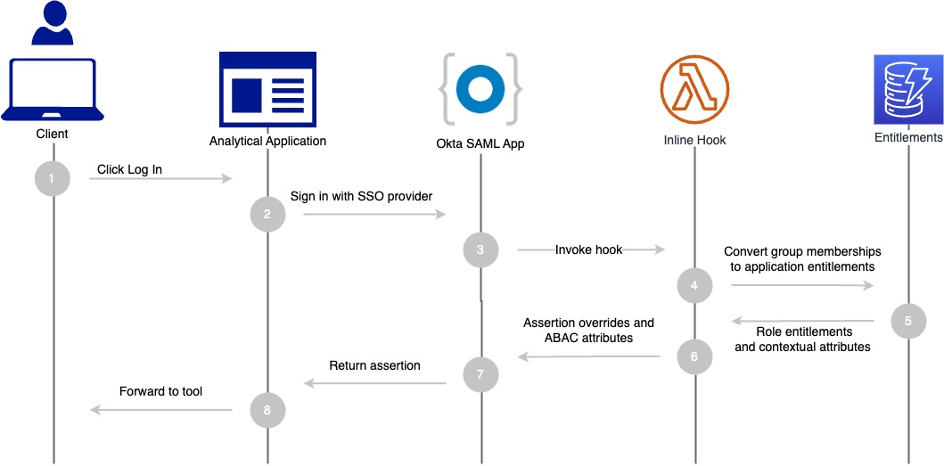
The workflow steps are as follows:
- A user accesses an analytical service such as Databricks in the Novo Nordisk analytics hub.
- The service uses Okta as the SAML-based IdP.
- Okta invokes an AWS Lambda-based SAML assertion inline hook.
- The hook uses the entitlement database, converting application-relevant group memberships into role entitlements.
- Relevant contextual information is returned from the entitlement database.
- The Lambda-based hook adds new SAML attributes to the SAML assertion, including the hashed group memberships and other contextual information such as source identity.
- A modified SAML assertion is used to sign users in to the analytical service.
- The user can now use the analytical tool with active IAM role sessions.
Synchronizing role trust
The preceding section gives an overview of how federation works in this solution. Now we can go through how we ensure that all participating AWS environments and accounts are in sync with the latest configuration.
From the end-user perspective, the synchronization mechanism must ensure that every analytics service instantiated can access the data domains assigned to the groups that the user belongs to. Also, changes in data domains—such as granting data access to an Active Directory group—must be effective immediately to every analytics service.
Two event-based mechanisms are used to maintain all the layers synchronized, as detailed in this section.
Synchronize data access control on the data management layer with changes to services in the consumption layer
As describe in the previous section, the IAM roles used for data access are created and managed by the data management layer. These IAM roles have a trust policy providing federated access to the external IdPs used by the analytics tools of the consumption layer. It implies that for every new analytical service created with a different IDP, the IAM roles used for data access on data domains must be updated to trust this new IdP.
Using NNEDH as an example of a data management solution, the synchronization mechanism is demonstrated in the following figure.
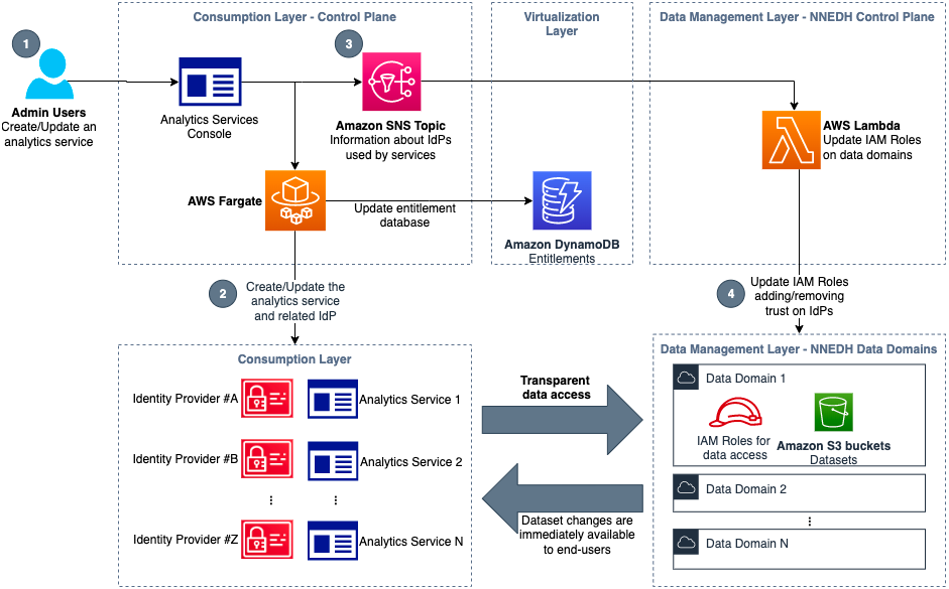
Taking as an example a scenario where a new analytics service is created, the steps in this workflow are as follows:
- A user with access to the administration console of the consumption layer instantiates a new analytics service, such as JupyterHub.
- A job running on AWS Fargate creates the resources needed for this new analytics service, such as an Amazon Elastic Compute Cloud (Amazon EC2) instance for JupyterHub, and the IdP required, such as a new SAML IdP.
- When the IdP is created in the previous step, an event is added in an Amazon Simple Notification Service (Amazon SNS) topic with its details, such as name and SAML metadata.
- In the NNEDH control plane, a Lambda job is triggered by new events on this SNS topic. This job creates the IAM IdP, if needed, and updates the trust policy of the required IAM roles in all the AWS accounts used as data domains, adding the trust on the IdP used by the new analytics service.
In this architecture, all the update steps are event-triggered and scalable. This means that users of new analytics services can access their datasets almost instantaneously when they are created. In the same way, when a service is removed, the federation to the IdP is automatically removed if not used by other services.
Propagate changes on data domains to analytics services
Changes to data domains, such as the creation of a new S3 bucket used as a dataset, or adding or removing data access to a group, must be reflected immediately on analytics services of the consumption layer. To accomplish it, a mechanism is used to synchronize the entitlement database with the relevant changes made in NNEDH. This flow is demonstrated in the following figure.
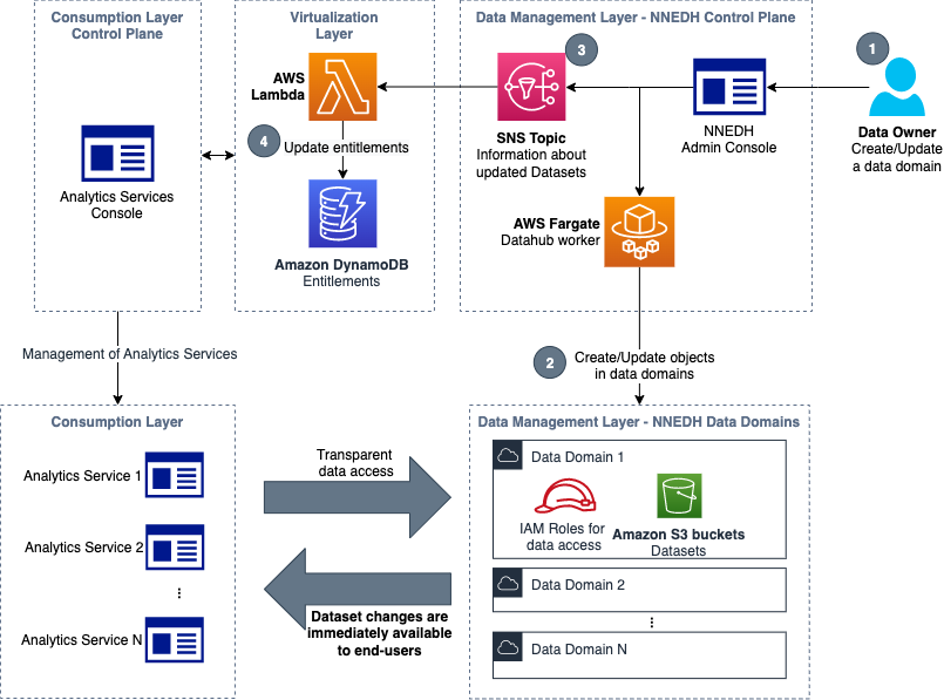
Taking as an example a scenario where access to a specific dataset is granted to a new group, the steps in this workflow are as follows:
- Using the NNEDH admin console, a data owner approves a dataset sharing request that grants access on a dataset to an Active Directory group.
- In the AWS account of the related data domain, the dataset components such as the S3 bucket and Lake Formation are updated to provide data access to the new group. The cross-account data sharing in Lake Formation uses AWS RAM.
- An event is added in an SNS topic with the current details about this dataset, such as the location of the S3 bucket and the groups that currently have access to it.
- In the virtualization layer, the updated information from the data management layer is used to update the entitlement database in DynamoDB.
These steps make sure that changes on data domains are automatically and immediately reflected on the entitlement database, which is used to provide data access to all the analytics services of the consumption layer.
Limitations
Many of these patterns rely on the analytical tool to support a clever use of IAM roles. When this is not the case, the platform teams themselves need to develop custom functionality at the host level to ensure that role accesses are correctly controlled. This, for example, includes writing custom authenticators for JupyterHub.
Conclusion
This post shows an approach to building a scalable and secure data and analytics platform. It showcases some of the mechanisms used at Novo Nordisk and how to strike the right balance between freedom and control. The architecture laid out in the first post in this series enables layer independence, and exposes some extremely useful primitives for data access and governance. We make heavy use of contextual attributes to modulate role permissions at the session level, which provide just-in-time permissions. These permissions are propagated at a scale, across data domains. The upside is that a lot of the complexity related to managing data access permission can be delegated to the relevant business groups, while enabling the end-user consumers of data to think as little as possible about data accesses and focus on providing value for the business use cases. In the case of Novo Nordisk, they can provide better outcomes for patients and acceleration innovation.
The next post in this series describes how end-users can consume data from their analytics tool of choice, aligned with the data access controls detailed in this post.
About the Authors
 Jonatan Selsing is former research scientist with a PhD in astrophysics that has turned to the cloud. He is currently the Lead Cloud Engineer at Novo Nordisk, where he enables data and analytics workloads at scale. With an emphasis on reducing the total cost of ownership of cloud-based workloads, while giving full benefit of the advantages of cloud, he designs, builds, and maintains solutions that enable research for future medicines.
Jonatan Selsing is former research scientist with a PhD in astrophysics that has turned to the cloud. He is currently the Lead Cloud Engineer at Novo Nordisk, where he enables data and analytics workloads at scale. With an emphasis on reducing the total cost of ownership of cloud-based workloads, while giving full benefit of the advantages of cloud, he designs, builds, and maintains solutions that enable research for future medicines.
 Hassen Riahi is a Sr. Data Architect at AWS Professional Services. He holds a PhD in Mathematics & Computer Science on large-scale data management. He works with AWS customers on building data-driven solutions.
Hassen Riahi is a Sr. Data Architect at AWS Professional Services. He holds a PhD in Mathematics & Computer Science on large-scale data management. He works with AWS customers on building data-driven solutions.
 Alessandro Fior is a Sr. Data Architect at AWS Professional Services. He is passionate about designing and building modern and scalable data platforms that accelerate companies to extract value from their data.
Alessandro Fior is a Sr. Data Architect at AWS Professional Services. He is passionate about designing and building modern and scalable data platforms that accelerate companies to extract value from their data.
 Moses Arthur comes from a mathematics and computational research background and holds a PhD in Computational Intelligence specialized in Graph Mining. He is currently a Cloud Product Engineer at Novo Nordisk, building GxP-compliant enterprise data lakes and analytics platforms for Novo Nordisk global factories producing digitalized medical products.
Moses Arthur comes from a mathematics and computational research background and holds a PhD in Computational Intelligence specialized in Graph Mining. He is currently a Cloud Product Engineer at Novo Nordisk, building GxP-compliant enterprise data lakes and analytics platforms for Novo Nordisk global factories producing digitalized medical products.
 Anwar Rizal is a Senior Machine Learning consultant based in Paris. He works with AWS customers to develop data and AI solutions to sustainably grow their business.
Anwar Rizal is a Senior Machine Learning consultant based in Paris. He works with AWS customers to develop data and AI solutions to sustainably grow their business.
 Kumari Ramar is an Agile certified and PMP certified Senior Engagement Manager at AWS Professional Services. She delivers data and AI/ML solutions that speed up cross-system analytics and machine learning models, which enable enterprises to make data-driven decisions and drive new innovations.
Kumari Ramar is an Agile certified and PMP certified Senior Engagement Manager at AWS Professional Services. She delivers data and AI/ML solutions that speed up cross-system analytics and machine learning models, which enable enterprises to make data-driven decisions and drive new innovations.