AWS Big Data Blog
How SOCAR built a streaming data pipeline to process IoT data for real-time analytics and control
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
SOCAR is the leading Korean mobility company with strong competitiveness in car-sharing. SOCAR has become a comprehensive mobility platform in collaboration with Nine2One, an e-bike sharing service, and Modu Company, an online parking platform. Backed by advanced technology and data, SOCAR solves mobility-related social problems, such as parking difficulties and traffic congestion, and changes the car ownership-oriented mobility habits in Korea.
SOCAR is building a new fleet management system to manage the many actions and processes that must occur in order for fleet vehicles to run on time, within budget, and at maximum efficiency. To achieve this, SOCAR is looking to build a highly scalable data platform using AWS services to collect, process, store, and analyze internet of things (IoT) streaming data from various vehicle devices and historical operational data.
This in-car device data, combined with operational data such as car details and reservation details, will provide a foundation for analytics use cases. For example, SOCAR will be able to notify customers if they have forgotten to turn their headlights off or to schedule a service if a battery is running low. Unfortunately, the previous architecture didn’t enable the enrichment of IoT data with operational data and couldn’t support streaming analytics use cases.
AWS Data Lab offers accelerated, joint-engineering engagements between customers and AWS technical resources to create tangible deliverables that accelerate data and analytics modernization initiatives. The Build Lab is a 2–5-day intensive build with a technical customer team.
In this post, we share how SOCAR engaged the Data Lab program to assist them in building a prototype solution to overcome these challenges, and to build the basis for accelerating their data project.
Use case 1: Streaming data analytics and real-time control
SOCAR wanted to utilize IoT data for a new business initiative. A fleet management system, where data comes from IoT devices in the vehicles, is a key input to drive business decisions and derive insights. This data is captured by AWS IoT and sent to Amazon Managed Streaming for Apache Kafka (Amazon MSK). By joining the IoT data to other operational datasets, including reservations, car information, device information, and others, the solution can support a number of functions across SOCAR’s business.
An example of real-time monitoring is when a customer turns off the car engine and closes the car door, but the headlights are still on. By using IoT data related to the car light, door, and engine, a notification is sent to the customer to inform them that the car headlights should be turned off.
Although this real-time control is important, they also want to collect historical data—both raw and curated data—in Amazon Simple Storage Service (Amazon S3) to support historical analytics and visualizations by using Amazon QuickSight.
Use case 2: Detect table schema change
The first challenge SOCAR faced was existing batch ingestion pipelines that were prone to breaking when schema changes occurred in the source systems. Additionally, these pipelines didn’t deliver data in a way that was easy for business analysts to consume. In order to meet the future data volumes and business requirements, they needed a pattern for the automated monitoring of batch pipelines with notification of schema changes and the ability to continue processing.
The second challenge was related to the complexity of the JSON files being ingested. The existing batch pipelines weren’t flattening the five-level nested structure, which made it difficult for business users and analysts to gain business insights without any effort on their end.
Overview of solution
In this solution, we followed the serverless data architecture to establish a data platform for SOCAR. This serverless architecture allowed SOCAR to run data pipelines continuously and scale automatically with no setup cost and without managing servers.
AWS Glue is used for both the streaming and batch data pipelines. Amazon Kinesis Data Analytics is used to deliver streaming data with subsecond latencies. In terms of storage, data is stored in Amazon S3 for historical data analysis, auditing, and backup. However, when frequent reading of the latest snapshot data is required by multiple users and applications concurrently, the data is stored and read from Amazon DynamoDB tables. DynamoDB is a key-value and document database that can support tables of virtually any size with horizontal scaling.
Let’s discuss the components of the solution in detail before walking through the steps of the entire data flow.
Component 1: Processing IoT streaming data with business data
The first data pipeline (see the following diagram) processes IoT streaming data with business data from an Amazon Aurora MySQL-Compatible Edition database.
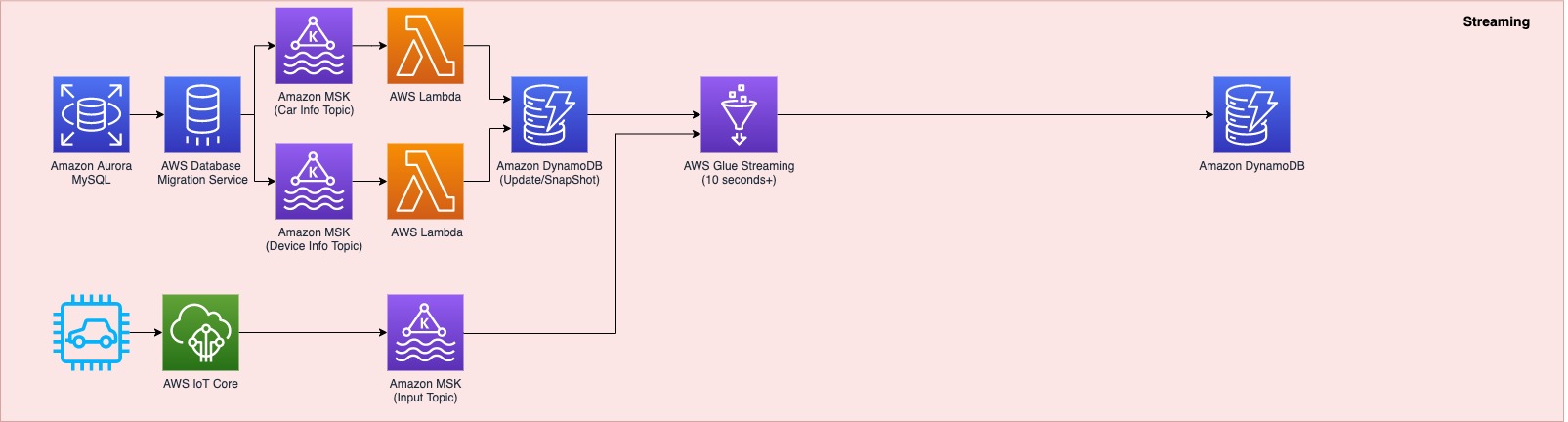
Whenever a transaction occurs in two tables in the Aurora MySQL database, this transaction is captured as data and then loaded into two MSK topics via AWS Database Management (AWS DMS) tasks. One topic conveys the car information table, and the other topic is for the device information table. This data is loaded into a single DynamoDB table that contains all the attributes (or columns) that exist in the two tables in the Aurora MySQL database, along with a primary key. This single DynamoDB table contains the latest snapshot data from the two DB tables, and is important because it contains the latest information of all the cars and devices for the lookup against the streaming IoT data. If the lookup were done on the database directly with the streaming data, it would impact the production database performance.
When the snapshot is available in DynamoDB, an AWS Glue streaming job runs continuously to collect the IoT data and join it with the latest snapshot data in the DynamoDB table to produce the up-to-date output, which is written into another DynamoDB table.
The up-to-date data in DynamoDB is used for real-time monitoring and control that SOCAR’s Data Analytics team performs for safety maintenance and fleet management. This data is ultimately consumed by a number of apps to perform various business activities, including route optimization, real-time monitoring for oil consumption and temperature, and to identify a driver’s driving pattern, tire wear and defect detection, and real-time car crash notifications.
Component 2: Processing IoT data and visualizing the data in dashboards
The second data pipeline (see the following diagram) batch processes the IoT data and visualizes it in QuickSight dashboards.
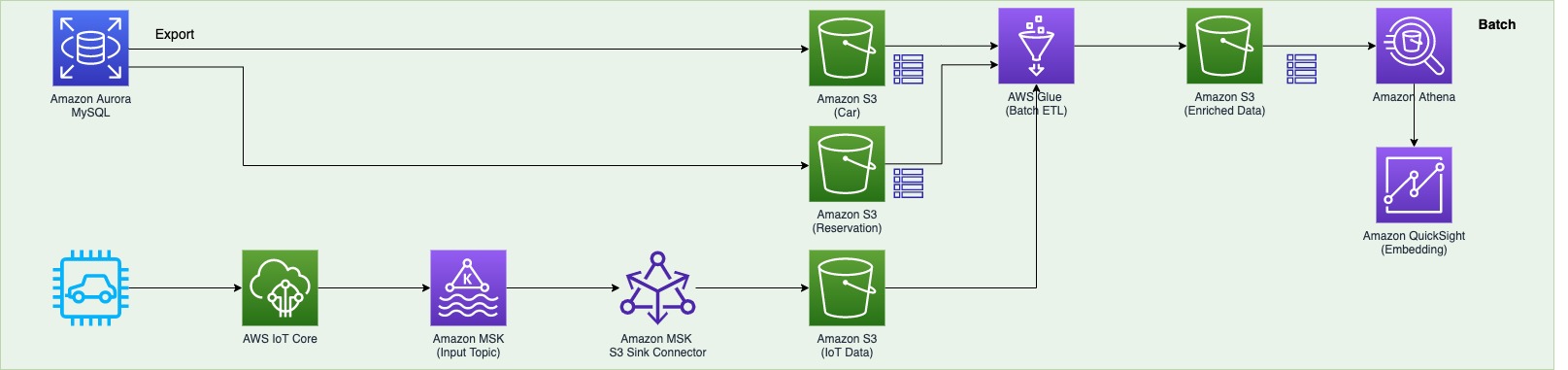
There are two data sources. The first is the Aurora MySQL database. The two database tables are exported into Amazon S3 from the Aurora MySQL cluster and registered in the AWS Glue Data Catalog as tables. The second data source is Amazon MSK, which receives streaming data from AWS IoT Core. This requires you to create a secure AWS Glue connection for an Apache Kafka data stream. SOCAR’s MSK cluster requires SASL_SSL as a security protocol (for more information, refer to Authentication and authorization for Apache Kafka APIs). To create an MSK connection in AWS Glue and set up connectivity, we use the following CLI command:
Component 3: Real-time control
The third data pipeline processes the streaming IoT data in millisecond latency from Amazon MSK to produce the output in DynamoDB, and sends a notification in real time if any records are identified as an outlier based on business rules.

AWS IoT Core provides integrations with Amazon MSK to set up real-time streaming data pipelines. To do so, complete the following steps:
- On the AWS IoT Core console, choose Act in the navigation pane.
- Choose Rules, and create a new rule.
- For Actions, choose Add action and choose Kafka.
- Choose the VPC destination if required.
- Specify the Kafka topic.
- Specify the TLS bootstrap servers of your Amazon MSK cluster.
You can view the bootstrap server URLs in the client information of your MSK cluster details. The AWS IoT rule was created with the Kafka topic as an action to provide data from AWS IoT Core to Kafka topics.
SOCAR used Amazon Kinesis Data Analytics Studio to analyze streaming data in real time and build stream-processing applications using standard SQL and Python. We created one table from the Kafka topic using the following code:
Then we applied a query with business logic to identify a particular set of records that need to be alerted. When this data is loaded back into another Kafka topic, AWS Lambda functions trigger the downstream action: either load the data into a DynamoDB table or send an email notification.
Component 4: Flattening the nested structure JSON and monitoring schema changes
The final data pipeline (see the following diagram) processes complex, semi-structured, and nested JSON files.

This step uses an AWS Glue DynamicFrame to flatten the nested structure and then land the output in Amazon S3. After the data is loaded, it’s scanned by an AWS Glue crawler to update the Data Catalog table and detect any changes in the schema.
Data flow: Putting it all together
The following diagram illustrates our complete data flow with each component.

Let’s walk through the steps of each pipeline.
The first data pipeline (in red) processes the IoT streaming data with the Aurora MySQL business data:
- AWS DMS is used for ongoing replication to continuously apply source changes to the target with minimal latency. The source includes two tables in the Aurora MySQL database tables (
carinfoanddeviceinfo), and each is linked to two MSK topics via AWS DMS tasks. - Amazon MSK triggers a Lambda function, so whenever a topic receives data, a Lambda function runs to load data into DynamoDB table.
- There is a single DynamoDB table with columns that exist from the
carinfotable and thedeviceinfotable of the Aurora MySQL database. This table consists of all the data from two tables and stores the latest data by performing anupsertoperation. - An AWS Glue job continuously receives the IoT data and joins it with data in the DynamoDB table to produce the output into another DynamoDB target table.
- This target table contains the final data, which includes all the device and car status information from the IoT devices as well as metadata from the Aurora MySQL table.
The second data pipeline (in green) batch processes IoT data to use in dashboards and for visualization:
- The car and reservation data (in two DB tables) is exported via a SQL command from the Aurora MySQL database with the output data available in an S3 bucket. The folders that contain data are registered as an S3 location for the AWS Glue crawler and become available via the AWS Glue Data Catalog.
- The MSK input topic continuously receives data from AWS IoT. Each car has a number of IoT devices, and each device captures data and sends it to an MSK input topic. The Amazon MSK S3 sink connector is configured to export data from Kafka topics to Amazon S3 in JSON formats. In addition, the S3 connector exports data by guaranteeing exactly-once delivery semantics to consumers of the S3 objects it produces.
- The AWS Glue job runs in a daily batch to load the historical IoT data into Amazon S3 and into two tables (refer to step 1) to produce the output data in an Enriched folder in Amazon S3.
- Amazon Athena is used to query data from Amazon S3 and make it available as a dataset in QuickSight for visualizing historical data.
The third data pipeline (in blue) processes streaming IoT data from Amazon MSK with millisecond latency to produce the output in DynamoDB and send a notification:
- An Amazon Kinesis Data Analytics Studio notebook powered by Apache Zeppelin and Apache Flink is used to build and deploy its output as a Kinesis Data Analytics application. This application loads data from Amazon MSK in real time, and users can apply business logic to select particular events coming from the IoT real-time data, for example, the car engine is off and the doors are closed, but the headlights are still on. The particular event that users want to capture can be sent to another MSK topic (Outlier) via the Kinesis Data Analytics application.
- Amazon MSK triggers a Lambda function, so whenever a topic receives data, a Lambda function runs to send an email notification to users that are subscribed to an Amazon Simple Notification Service (Amazon SNS) topic. An email is published using an SNS notification.
- The Kinesis Data Analytics application loads data from AWS IoT, applies business logic, and then loads it into another MSK topic (output). Amazon MSK triggers a Lambda function when data is received, which loads data into a DynamoDB Append table.
- Amazon Kinesis Data Analytics Studio is used to run SQL commands for ad hoc interactive analysis on streaming data.
The final data pipeline (in yellow) processes complex, semi-structured, and nested JSON files, and sends a notification when a schema evolves.
- An AWS Glue job runs and reads the JSON data from Amazon S3 (as a source), applies logic to flatten the nested schema using a DynamicFrame, and pivots out array columns from the flattened frame.
- The output is stored in Amazon S3 and is automatically registered to the AWS Glue Data Catalog table.
- Whenever there is a new attribute or change in the JSON input data at any level in the nested structure, the new attribute and change are captured in Amazon EventBridge as an event from the AWS Glue Data Catalog. An email notification is published using Amazon SNS.
Conclusion
As a result of the four-day Build Lab, the SOCAR team left with a working prototype that is custom fit to their needs, gaining a clear path to production. The Data Lab allowed the SOCAR team to build a new streaming data pipeline, enrich IoT data with operational data, and enhance the existing data pipeline to process complex nested JSON data. This establishes a baseline architecture to support the new fleet management system beyond the car-sharing business.
About the Authors
 DoYeun Kim is the Head of Data Engineering at SOCAR. He is a passionate software engineering professional with 19+ years experience. He leads a team of 10+ engineers who are responsible for the data platform, data warehouse and MLOps engineering, as well as building in-house data products.
DoYeun Kim is the Head of Data Engineering at SOCAR. He is a passionate software engineering professional with 19+ years experience. He leads a team of 10+ engineers who are responsible for the data platform, data warehouse and MLOps engineering, as well as building in-house data products.
 SangSu Park is a Lead Data Architect in SOCAR’s cloud DB team. His passion is to keep learning, embrace challenges, and strive for mutual growth through communication. He loves to travel in search of new cities and places.
SangSu Park is a Lead Data Architect in SOCAR’s cloud DB team. His passion is to keep learning, embrace challenges, and strive for mutual growth through communication. He loves to travel in search of new cities and places.
 YoungMin Park is a Lead Architect in SOCAR’s cloud infrastructure team. His philosophy in life is-whatever it may be-to challenge, fail, learn, and share such experiences to build a better tomorrow for the world. He enjoys building expertise in various fields and basketball.
YoungMin Park is a Lead Architect in SOCAR’s cloud infrastructure team. His philosophy in life is-whatever it may be-to challenge, fail, learn, and share such experiences to build a better tomorrow for the world. He enjoys building expertise in various fields and basketball.
 Younggu Yun works at AWS Data Lab in Korea. His role involves helping customers across the APAC region meet their business objectives and overcome technical challenges by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together.
Younggu Yun works at AWS Data Lab in Korea. His role involves helping customers across the APAC region meet their business objectives and overcome technical challenges by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together.
 Vicky Falconer leads the AWS Data Lab program across APAC, offering accelerated joint engineering engagements between teams of customer builders and AWS technical resources to create tangible deliverables that accelerate data analytics modernization and machine learning initiatives.
Vicky Falconer leads the AWS Data Lab program across APAC, offering accelerated joint engineering engagements between teams of customer builders and AWS technical resources to create tangible deliverables that accelerate data analytics modernization and machine learning initiatives.