AWS Big Data Blog
Category: Amazon Athena
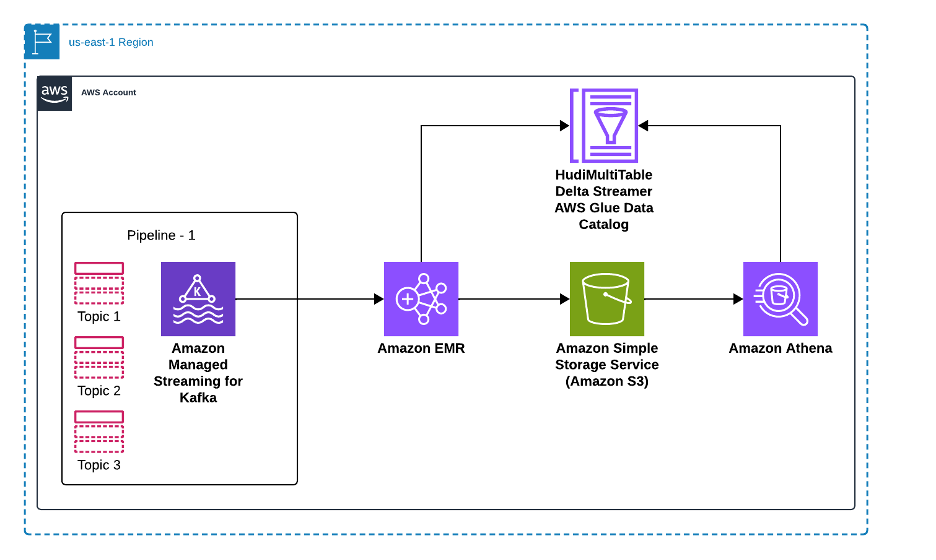
Using Amazon EMR DeltaStreamer to stream data to multiple Apache Hudi tables
In this post, we show you how to implement real-time data ingestion from multiple Kafka topics to Apache Hudi tables using Amazon EMR. This solution streamlines data ingestion by processing multiple Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics in parallel while providing data quality and scalability through change data capture (CDC) and Apache Hudi.
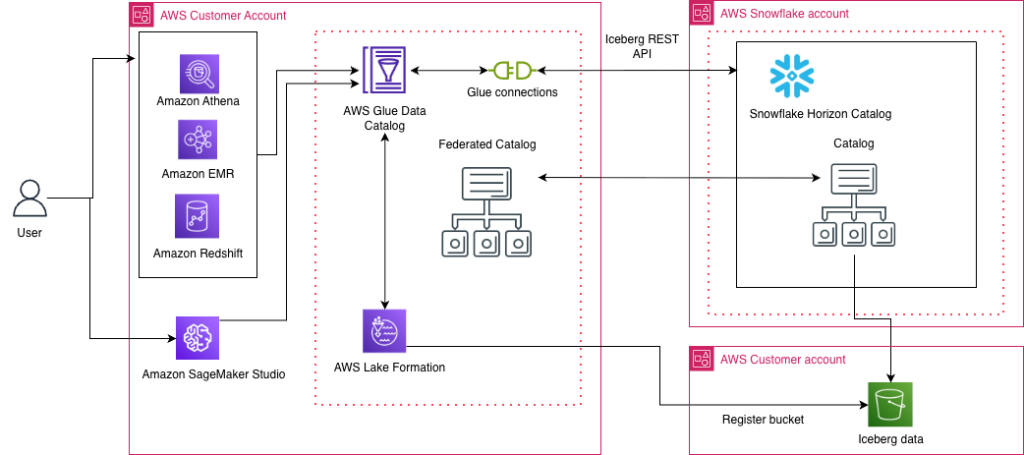
Access Snowflake Horizon Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has introduced a new catalog federation feature that enables direct access to Snowflake Horizon Catalog data through AWS Glue Data Catalog. This integration allows organizations to discover and query data in Iceberg format while maintaining security through AWS Lake Formation. This post provides a step-by-step guide to establishing this integration, including configuring Snowflake Horizon Catalog, setting up authentication, creating necessary IAM roles, and implementing AWS Lake Formation permissions. Learn how to enable cross-platform analytics while maintaining robust security and governance across your data environment.

How Twilio built a multi-engine query platform using Amazon Athena and open-source Presto
At Twilio, we manage a 20 petabyte-scale Amazon S3 data lake that serves the analytics needs of over 1,500 users, processing 2.5 million queries monthly and scanning an average of 85 PB of data. To meet our growing demands for scalability, emerging technology support, and data mesh architecture adoption, we built Odin, a multi-engine query platform that provides an abstraction layer built on top of Presto Gateway. In this post, we discuss how we designed and built Odin, combining Amazon Athena with open-source Presto to create a flexible, scalable data querying solution.

Visualize data lineage using Amazon SageMaker Catalog for Amazon EMR, AWS Glue, and Amazon Redshift
Amazon SageMaker offers a comprehensive hub that integrates data, analytics, and AI capabilities, providing a unified experience for users to access and work with their data. Through Amazon SageMaker Unified Studio, a single and unified environment, you can use a wide range of tools and features to support your data and AI development needs, including […]

Transform your data to Amazon S3 Tables with Amazon Athena
This post demonstrates how Amazon Athena CREATE TABLE AS SELECT (CTAS) simplifies the data transformation process through a practical example: migrating an existing Parquet dataset into Amazon S3 Tables.

Build an analytics pipeline that is resilient to Avro schema changes using Amazon Athena
This post demonstrates how to build a solution by combining Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue Data Catalog for schema management, and Amazon Athena for one-time querying. We’ll focus specifically on handling Avro-formatted data in partitioned S3 buckets, where schemas can change frequently while providing consistent query capabilities across all data regardless of schema versions.

How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.

Introducing managed query results for Amazon Athena
We’re thrilled to introduce managed query results, a new Athena feature that automatically stores, secures, and manages the lifecycle of query result data for you at no additional cost. In this post, we demonstrate how to get started with managed query results and, by removing the undifferentiated effort spent on query result management, how Athena helps you get insights from your data in fewer steps than before.

Build a secure serverless streaming pipeline with Amazon MSK Serverless, Amazon EMR Serverless and IAM
The post demonstrates a comprehensive, end-to-end solution for processing data from MSK Serverless using an EMR Serverless Spark Streaming job, secured with IAM authentication. Additionally, it demonstrates how to query the processed data using Amazon Athena, providing a seamless and integrated workflow for data processing and analysis. This solution enables near real-time querying of the latest data processed from MSK Serverless and EMR Serverless using Athena, providing instant insights and analytics.

How BMW Group built a serverless terabyte-scale data transformation architecture with dbt and Amazon Athena
At the BMW Group, our Cloud Efficiency Analytics (CLEA) team has developed a FinOps solution to optimize costs across over 10,000 cloud accounts This post explores our journey, from the initial challenges to our current architecture, and details the steps we took to achieve a highly efficient, serverless data transformation setup.