AWS Big Data Blog
Category: Compute

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

AI-powered performance recommendations for Amazon Redshift
In this post, you learn how to build an AI-powered solution that collects the telemetry, pre-computes performance signals, correlates them with CloudWatch, and uses Amazon Bedrock to generate prioritized recommendations.

Why tombola chose Graviton-powered RG instances for Amazon Redshift
In this post, you learn how tombola followed a strict engineering principle: no changes to production without evidence. That meant a head-to-head comparison of RA3 versus RG on their actual workload. You also see benchmark results on Amazon S3 Tables and the migration from RA3 to RG instances.

Real-time CDC from Aurora PostgreSQL to Amazon S3 Tables using Debezium and Firehose
In this post, we show you how to build a CDC pipeline that delivers query-ready Iceberg tables directly. The pipeline captures inserts, updates, and deletes from Aurora PostgreSQL and applies them as row-level operations in Amazon S3 Tables, a capability of Amazon Simple Storage Service (Amazon S3).

Meet Amazon Redshift RG – AWS Graviton-based instances with an integrated data lake query engine delivering up to 2.4x better performance at 30% lower price than RA3
On May 12, 2026, we announced the general availability of Amazon Redshift RG instances, powered by AWS Graviton processors. RG instances are up to 2.2x as fast for data warehouse workloads and up to 2.4x as fast for data lake workloads, all at 30% lower price per vCPU compared to RA3 instances. RG instances support all data lake formats supported by RA3 and eliminate Amazon Redshift Spectrum’s per-TB scanning charges. RG instances feature a custom-built integrated vectorized query engine, making them a more performant and cost-effective foundation for unified analytics. We are launching with two instance sizes: rg.xlarge and rg.4xlarge, with additional sizes coming later this year.

How to set up a network-isolated VPC for Amazon SageMaker Unified Studio
In this post, we explore scenarios where customers need more control over their network infrastructure when building their unified data and analytics strategic layer. We’ll show how you can bring your own Amazon Virtual Private Cloud (Amazon VPC) and set up Amazon SageMaker Unified Studio for strict network control.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 1
In this post, we show how organizations can provide secure, private access to multiple Amazon OpenSearch Serverless collections from both on-premises environments and distributed AWS accounts using a single centralized interface VPC endpoint and Route 53 Profiles.
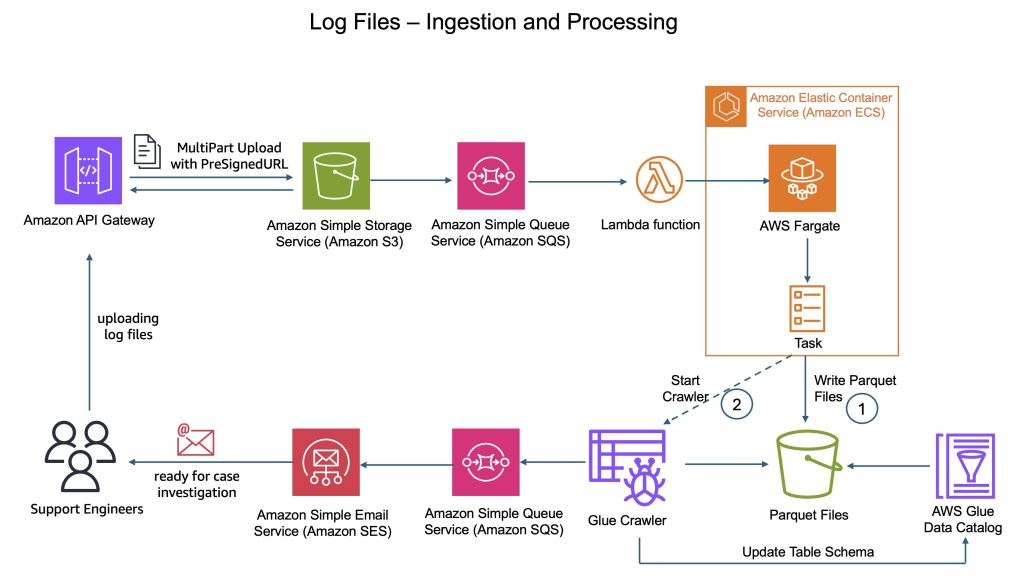
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.
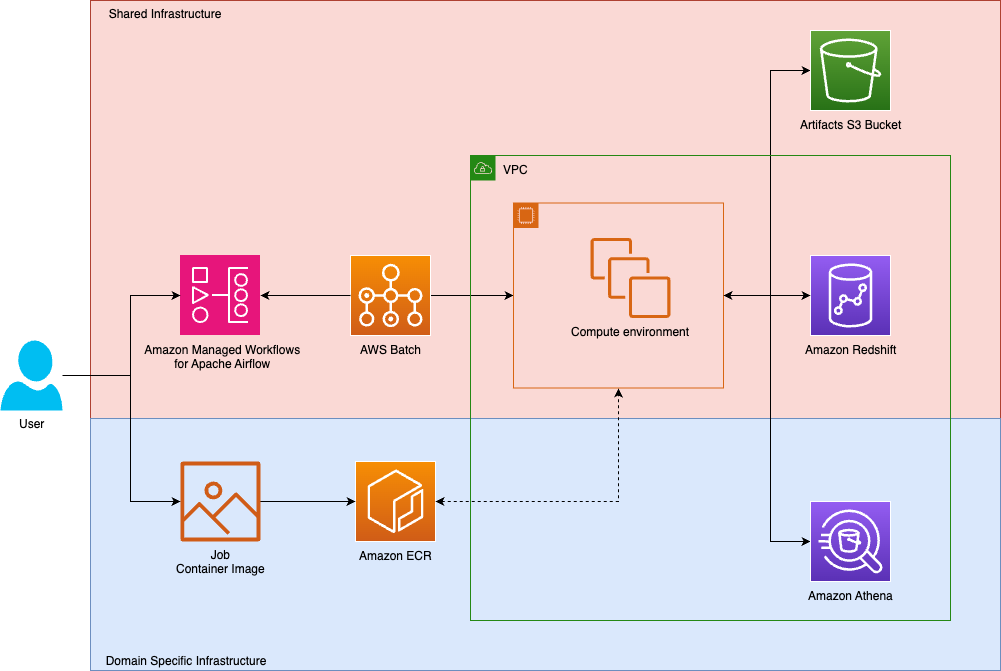
How Tipico democratized data transformations using Amazon Managed Workflows for Apache Airflow and AWS Batch
Tipico is the number one name in sports betting in Germany. Every day, we connect millions of fans to the thrill of sport, combining technology, passion, and trust to deliver fast, secure, and exciting betting, both online and in more than a thousand retail shops across Germany. We also bring this experience to Austria, where we proudly operate a strong sports betting business. In this post, we show how Tipico built a unified data transformation platform using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and AWS Batch.
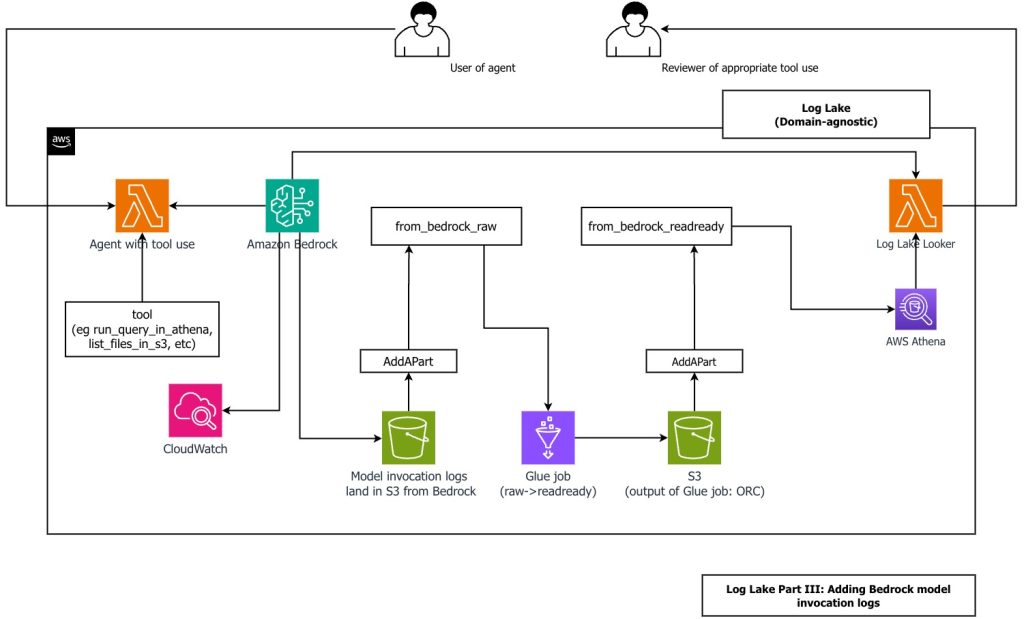
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.