AWS Big Data Blog
Amazon MSK now provides up to 29% more throughput and up to 24% lower costs with AWS Graviton3 support
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data.
Today, we’re excited to bring the benefits of Graviton3 to Kafka workloads, with Amazon MSK now offering M7g instances for new MSK provisioned clusters. AWS Graviton processors are custom Arm-based processors built by AWS to deliver the best price-performance for your cloud workloads. For example, when running an MSK provisioned cluster using M7g.4xlarge instances, you can achieve up to 27% reduction in CPU usage and up to 29% higher write and read throughput compared to M5.4xlarge instances. These performance improvements, along with M7g’s lower prices, provide up to 24% in compute cost savings over M5 instances.
In February 2023, AWS launched new Graviton3-based M7g instances. M7g instances are equipped with DDR5 memory, which provides up to 50% higher memory bandwidth than the DDR4 memory used in previous generations. M7g instances also deliver up to 25% higher storage throughput and up to 88% increase in network throughput compared to similar sized M5 instances to deliver price-performance benefits for Kafka workloads. You can read more about M7g features in New Graviton3-Based General Purpose (m7g) and Memory-Optimized (r7g) Amazon EC2 Instances.
The following table lists the specs for the M7g instances on Amazon MSK:
| Name | vCPUs | Memory | Network Bandwidth | Storage Bandwidth |
| M7g.large | 2 | 8 GiB | up to 12.5 Gbps | up to 10 Gbps |
| M7g.xlarge | 4 | 16 GiB | up to 12.5 Gbps | up to 10 Gbps |
| M7g.2xlarge | 8 | 32 GiB | up to 15 Gbps | up to 10 Gbps |
| M7g.4xlarge | 16 | 64 GiB | up to 15 Gbps | up to 10 Gbps |
| M7g.8xlarge | 32 | 128 GiB | 15 Gbps | 10 Gbps |
| M7g.12xlarge | 48 | 192 GiB | 22.5 Gbps | 15 Gbps |
| M7g.16xlarge | 64 | 256 GiB | 30 Gbps | 20 Gbps |
M7g instances on Amazon MSK
Organizations are adopting Amazon MSK to capture and analyze data in real time, run machine learning (ML) workflows, and build event-driven architectures. Amazon MSK enables you to reduce operational overhead and run your applications with higher availability and durability. It also offers a consistent reduction in price-performance with capabilities such as Tiered Storage. With compute making up a large portion of Kafka costs, customers wanted a way to optimize them further and see Graviton instances providing them the quickest path. Amazon MSK has fully tested and validated M7g on Kafka versions 2.8.2, 3.3.2, and above, making it easy to run critical workloads and benefit from Graviton3 cost savings.
You can get started by provisioning new clusters with the Graviton3-based M7g instances as the broker type using the AWS Management Console, APIs via the AWS SDK, and the AWS Command Line Interface (AWS CLI). M7g instances support all Amazon MSK and Kafka features, making it straightforward for you to run all your existing Kafka workloads with minimal changes. Amazon MSK supports Graviton3-based M7g instances from large through 16xlarge sizes to run all Kafka workloads.
Let’s take the M7g instances on MSK provisioned clusters for a test drive and see how it compares with Amazon MSK M5 instances.
M7g instances in action
Customers run a wide variety of workloads on Amazon MSK; some are latency sensitive, and some are throughput bound. In this post, we focus on M7g performance impact on throughput-bound workloads. M7g comes with an increase in network and storage throughput, providing a higher throughput per broker compared to an M5-based cluster.
To understand the implications, let’s look at how Kafka uses available throughput for writing or reading data. Every broker in the MSK cluster comes with a bounded storage and network throughput entitlement. Predominantly, writes in Kafka consume both storage and network throughput, whereas reads consume mostly network throughput. This is because a Kafka consumer is typically reading real-time data from a page cache and occasionally goes to disk to process old data. Therefore, the overall throughput gains also change based on the workload’s write to read throughput ratios.
Let’s look at the throughput gains based on an example. Our setup includes an MSK cluster with M7g.4xlarge instances and another with M5.4xlarge instances, with three nodes in three different Availability Zones. We also enabled TLS encryption, AWS Identity and Access Management (IAM) authentication, and a replication factor of 3 across both M7g and M5 MSK clusters. We also applied Amazon MSK best practices for broker configurations, including num.network.threads = 8 and num.io.threads = 16. On the client side for writes, we optimized the batch size with appropriate linger.ms and batch.size configurations. For the workload, we assumed 6 topics each with 64 partitions (384 per broker). For ingestion, we generated load with an average message size of 512 bytes and with one consumer group per topic. The amount of load sent to the clusters was identical.
As we ingest more data into the MSK cluster, the M7g.4xlarge instance supports higher throughput per broker, as shown in the following graph. After an hour of consistent writes, M7g.4xlarge brokers support up to 54 MB/s of write throughput vs. 40 MB/s with M5-based brokers, which represents a 29% increase.
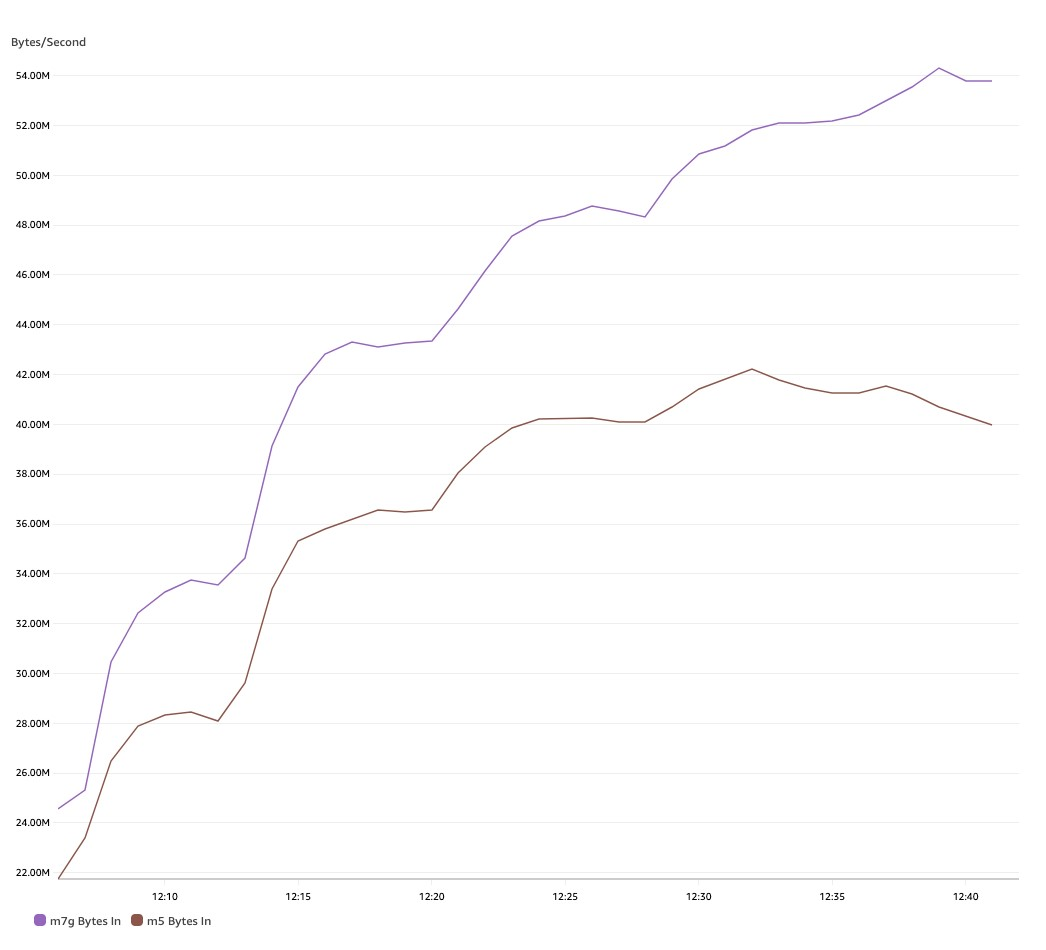
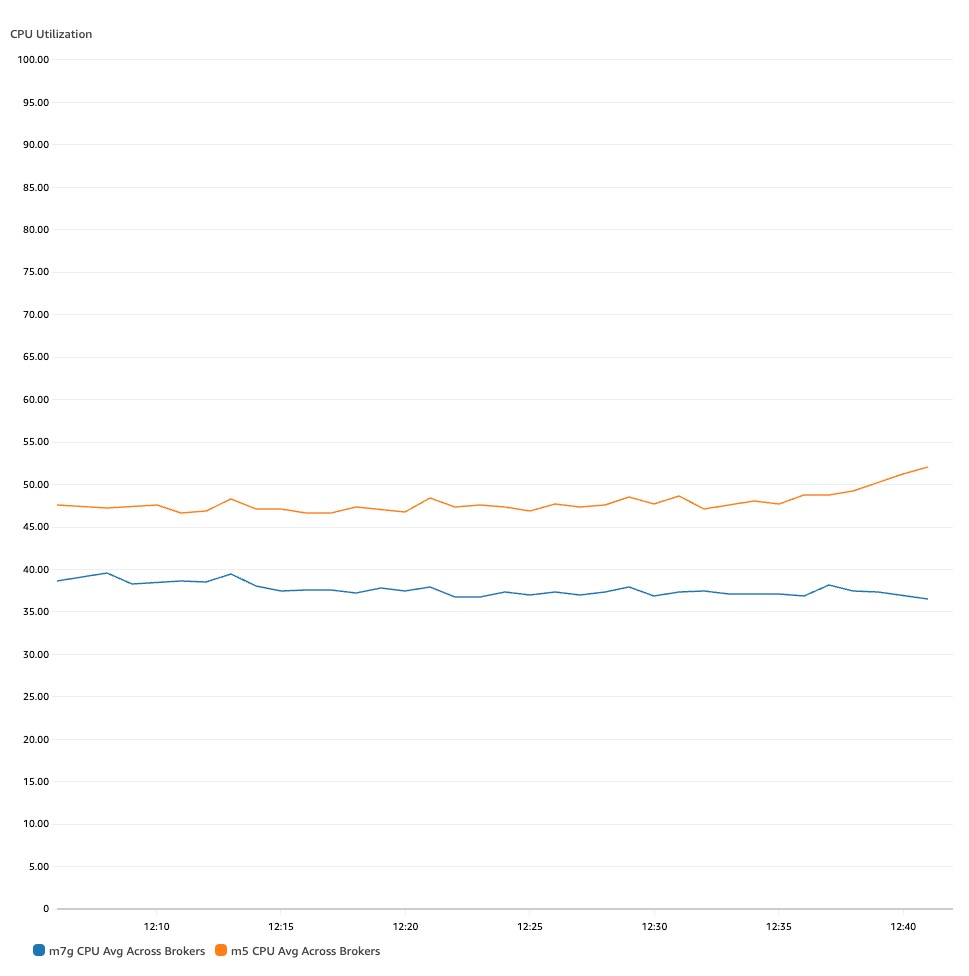
We also see another important observation: M7g-based brokers consume much fewer CPU resources than M5s, even though they support 29% higher throughput. As seen in the following chart, CPU utilization of an M7g-based broker is on average 40%, whereas on an M5-based broker, it’s 47%.
As covered previously, customers may see different performance improvements based on the number of consumer group, batch sizes, and instance size. We recommend referring to MSK Sizing and Pricing to calculate M7g performance gains for your use case or creating a cluster based on M7g instances and benchmark the gains on your own.
Lower costs, with lesser operational burden, and higher resiliency
Since its launch, Amazon MSK has made it cost-effective to run your Kafka workloads, while still improving overall resiliency. Since day 1, you have been able to run brokers in multiple Availability Zones without worrying about additional networking costs. In October 2022, we launched Tiered Storage, which provides virtually unlimited storage at up to 50% lower costs. When you use Tiered Storage, you not only save on overall storage cost but also improve the overall availability and elasticity of your cluster.
Continuing down this path, we are now reducing compute costs for customers while still providing performance improvements. With M7g instances, Amazon MSK provides 24% savings on compute costs compared to similar sized M5 instances. When you move to Amazon MSK, you can not only lower your operational overhead using features such as Amazon MSK Connect, Amazon MSK Replicator, and automatic Kafka version upgrades, but also improve over resiliency and reduce your infrastructure costs.
Pricing and Regions
M7g instances on Amazon MSK are available today in the Asia Pacific (Tokyo), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), Europe (Stockholm), Europe (Spain), Europe (Ireland), US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon) Regions.
Refer to Amazon MSK pricing to learn about Graviton3-based instances with Amazon MSK pricing and AWS Regions where they are currently available.
Summary
In this post, we discussed the performance gains achieved while using Graviton-based M7g instances. These instances can provide significant improvement in read and write throughput compared to similar sized M5 instances for Amazon MSK workloads. To get started, create a new cluster with M7g brokers using the AWS Management Console, and refer to the Amazon MSK Developer Guide for more information.
About the Authors
 Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
 Umesh Chaudhari is a Streaming Solutions Architect at AWS. He works with AWS customers to design and build real-time data processing systems. He has 13 years of working experience in software engineering including architecting, designing, and developing data analytics systems.
Umesh Chaudhari is a Streaming Solutions Architect at AWS. He works with AWS customers to design and build real-time data processing systems. He has 13 years of working experience in software engineering including architecting, designing, and developing data analytics systems.
 Lanre Afod is a Solutions Architect focused with Global Financial Services at AWS, passionate about helping customers with deploying secure, scalable, high available, and resilient architectures within the AWS Cloud.
Lanre Afod is a Solutions Architect focused with Global Financial Services at AWS, passionate about helping customers with deploying secure, scalable, high available, and resilient architectures within the AWS Cloud.