AWS Big Data Blog
Category: Amazon EMR

Build petabyte-scale synthetic test data with Amazon EMR on EC2
As data volumes grow from terabytes to petabytes, the architecture for generating synthetic data must evolve to meet increasing demands for scale, performance, and data quality. In this post, we show how you can build a scalable synthetic data generation solution using Amazon EMR, Apache Spark, and the Faker library.

Streamlined monitoring and debugging for Amazon EMR on EC2
In this post, we walk you through five key enhancements: Amazon CloudWatch Logs integration, step-level Amazon Simple Storage Service (Amazon S3) logging controls, expanded console UIs for YARN and Tez, Amazon EMR step to YARN application ID mapping, and enhanced custom metrics with updated documentation.

Detect and resolve HBase inconsistencies faster with AI on Amazon EMR
In this post, we show you how to build an AI-powered troubleshooting solution using Amazon OpenSearch Service vector search and intelligent analysis. This solution reduces HBase inconsistency resolution from hours to minutes and root cause identification from days to hours through natural language queries over operational data. This democratizes HBase troubleshooting capabilities across teams and reducing dependency on specialized expertise.

How to use streamlined permissions for Amazon S3 Tables and Iceberg materialized views
In this post, we walk through how to set up and manage S3 Tables in the AWS Glue Data Catalog, create and query Iceberg materialized views, and configure access controls that work across your analytics stack with IAM-based authorization.

Implementing Kerberos authentication for Apache Spark jobs on Amazon EMR on EKS to access a Kerberos-enabled Hive Metastore
In this post, we show how to configure Kerberos authentication for Spark jobs on Amazon EMR on EKS, authenticating against a Kerberos-enabled HMS so you can run both Amazon EMR on EC2 and Amazon EMR on EKS workloads against a single, secure HMS deployment.

Building a scalable, transactional data lake using dbt, Amazon EMR, and Apache Iceberg
Growing data volume, variety, and velocity has made it crucial for businesses to implement architectures that efficiently manage and analyze data, while maintaining data integrity and consistency. In this post, we show you a solution that combines Apache Iceberg, Data Build Tool (dbt), and Amazon EMR to create a scalable, ACID-compliant transactional data lake. You can use this data lake to process transactions and analyze data simultaneously while maintaining data accuracy and real-time insights for better decision-making.

Reducing costs for shuffle-heavy Apache Spark workloads with serverless storage for Amazon EMR Serverless
In this post, we explore the cost improvements we observed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper look at how serverless storage helps reduce costs for shuffle-heavy Spark workloads, and we outline practical guidance on identifying the types of queries that can benefit most from enabling serverless storage in your EMR Serverless Spark jobs.

Optimize HBase reads with bucket caching on Amazon EMR
In this post, we demonstrate how to improve HBase read performance by implementing bucket caching on Amazon EMR. Our tests reduced latency by 57.9% and improved throughput by 138.8%. This solution is particularly valuable for large-scale HBase deployments on Amazon S3 that need to optimize read performance while managing costs.

How Razorpay achieved 11% performance improvement and 21% cost reduction with Amazon EMR
In this post, we explore how Razorpay, India’s leading FinTech company, transformed their data platform by migrating from a third-party solution to Amazon EMR, unlocking improved performance and significant cost savings. We’ll walk through the architectural decisions that guided this migration, the implementation strategy, and the measurable benefits Razorpay achieved.
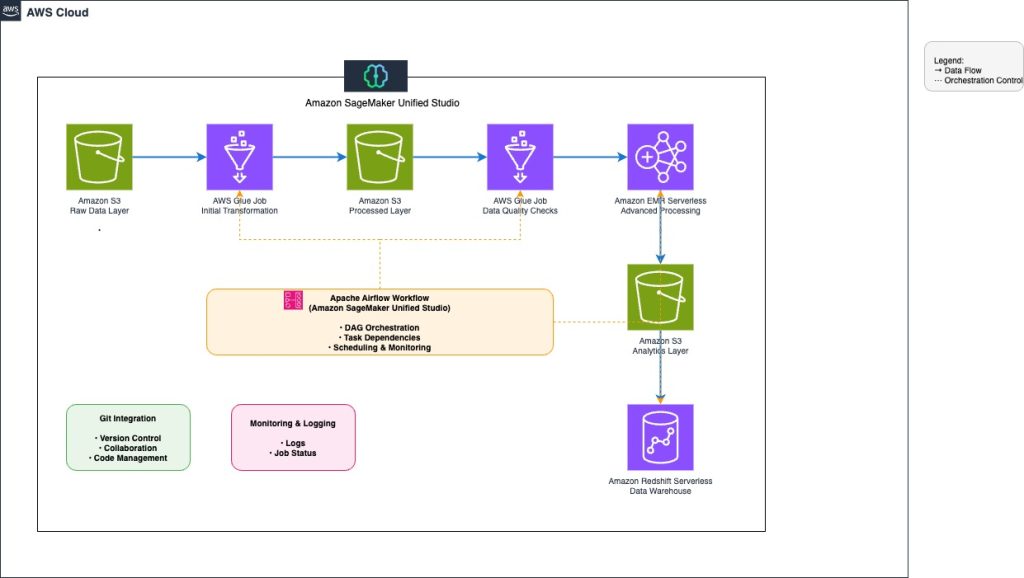
Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows
This post explores how to build and manage a comprehensive extract, transform, and load (ETL) pipeline using SageMaker Unified Studio workflows through a code-based approach. We demonstrate how to use a single, integrated interface to handle all aspects of data processing, from preparation to orchestration, by using AWS services including Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This solution streamlines the data pipeline through a single UI.