AWS Big Data Blog
Category: Amazon SageMaker Data & AI Governance

Build governance dashboards for Amazon SageMaker Catalog with Amazon Quick
In a previous post, we showed you how to query Amazon SageMaker Catalog metadata using SQL by using the metadata export feature. This post builds on that foundation by demonstrating how to create governance dashboards with Amazon Quick.

Accelerate SQL development with SageMaker Data Agent in Query Editor
In this post, you learn how to use Data Agent in Query Editor to explore data, build multi-step analyses, recover from errors, and summarize results using a public education dataset.

How Amazon is moving to integrate catalogs to improve data discovery with Amazon SageMaker
Enterprises face challenges when teams create data assets outside of central data catalogs. It adds overhead for discovery, and limits collaboration. Amazon’s Business Data Technologies (BDT) team has built an enterprise data catalog Andes for sharing datasets under well-defined policies. However, teams created catalog of local datasets and other non-tabular assets such as dashboards and metrics, outside Andes. This made it difficult to discover all assets in a consolidated way. In this post, we share how Amazon.com is working to integrate catalogs by extending enterprise data catalog Andes with Amazon SageMaker.

Analyzing your data catalog: Query SageMaker Catalog metadata with SQL
In this post, we demonstrate how to use the metadata export capability in Amazon SageMaker Catalog and perform analytics such as historical changes, monitor asset growth and track metadata improvements.

Navigating multi-account deployments in Amazon SageMaker Unified Studio: a governance-first approach
In this post, we explore SageMaker Unified Studio multi-account deployments in depth: what they entail, why they matter, and how to implement them effectively. We examine architecture patterns, evaluate trade-offs across security boundaries, operational overhead, and team autonomy. We also provide practical guidance to help you design a deployment that balances centralized control with distributed ownership across your organization.

Automating data classification in Amazon SageMaker Catalog using an AI agent
If you’re struggling with manual data classification in your organization, the new Amazon SageMaker Catalog AI agent can automate this process for you. Most large organizations face challenges with the manual tagging of data assets, which doesn’t scale and is unreliable. In some cases, business terms aren’t applied consistently across teams. Different groups name and tag data assets based on local conventions. This creates a fragmented catalog where discovery becomes unreliable and governance teams spend more time normalizing metadata than governing. In this post, we show you how to implement this automated classification to help reduce the manual tagging effort and improve metadata consistency across your organization.

Implement a data mesh pattern in Amazon SageMaker Catalog without changing applications
In this post, we walk through simulating a scenario based on data producer and data consumer that exists before Amazon SageMaker Catalog adoption. We use a sample dataset to simulate existing data and an existing application using an AWS Lambda function, then implement a data mesh pattern using Amazon SageMaker Catalog while keeping your current data repositories and consumer applications unchanged.
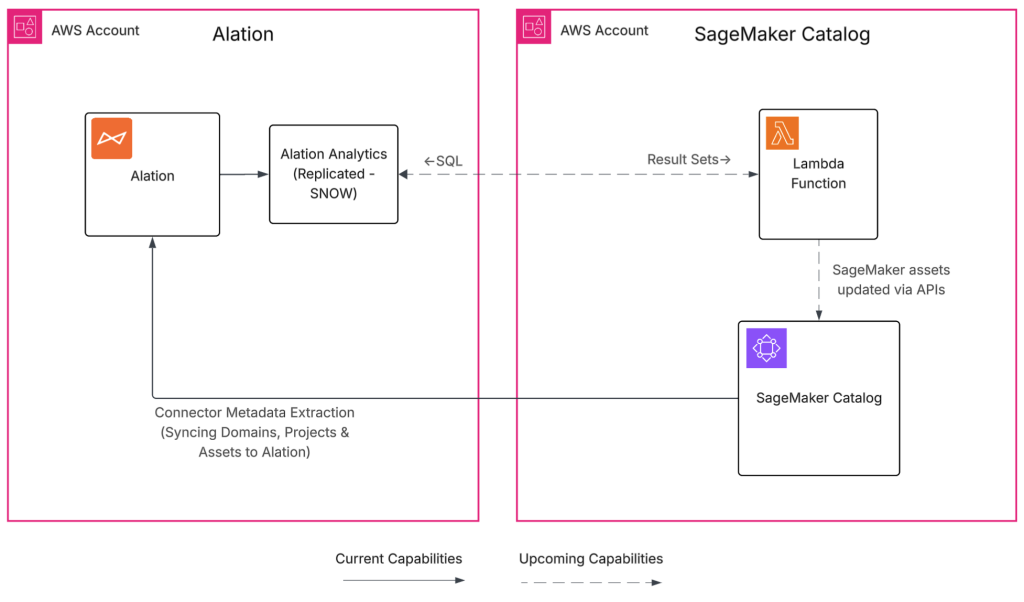
Build a trusted foundation for data and AI using Alation and Amazon SageMaker Unified Studio
The Alation and SageMaker Unified Studio integration helps organizations bridge the gap between fast analytics and ML development and the governance requirements most enterprises face. By cataloging metadata from SageMaker Unified Studio in Alation, you gain a governed, discoverable view of how assets are created and used. In this post, we demonstrate who benefits from this integration, how it works, the specific metadata it synchronizes, and provide a complete deployment guide for your environment.
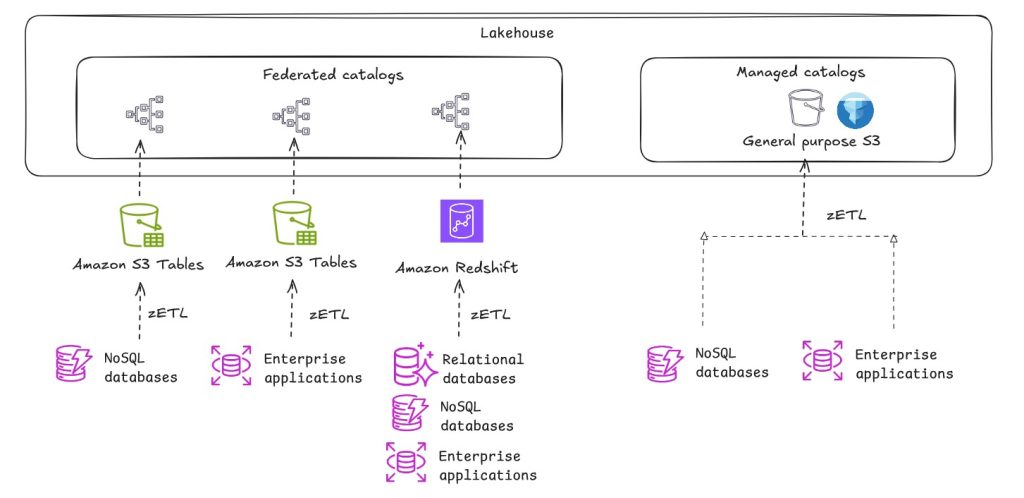
Navigating architectural choices for a lakehouse using Amazon SageMaker
Over time, several distinct lakehouse approaches have emerged. In this post, we show you how to evaluate and choose the right lakehouse pattern for your needs. A lakehouse architecture isn’t about choosing between a data lake and a data warehouse. Instead, it’s an approach to interoperability where both frameworks coexist and serve different purposes within a unified data architecture. By understanding fundamental storage patterns, implementing effective catalog strategies, and using native storage capabilities, you can build scalable, high-performance data architectures that support both your current analytics needs and future innovation.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]