AWS Big Data Blog
Category: Amazon EMR

Optimizing Flink’s join operations on Amazon EMR with Alluxio
In this post, we show you how to implement real-time data correlation using Apache Flink to join streaming order data with historical customer and product information, enabling you to make informed decisions based on comprehensive, up-to-date analytics. We also introduce an optimized solution to automatically load Hive dimension table data into Alluxio Universal Flash Storage (UFS) through the Alluxio cache layer. This enables Flink to perform temporal joins on changing data, accurately reflecting the content of a table at specific points in time.

Reduce EMR HBase upgrade downtime with the EMR read-replica prewarm feature
In this post, we show you how the read-replica prewarm feature of Amazon EMR 7.12 improves HBase cluster operations by minimizing the hard cutover constraints that make infrastructure changes challenging. This feature gives you a consistent blue-green deployment pattern that reduces risk and downtime for version upgrades and security patches.

Secure Apache Spark writes to Amazon S3 on Amazon EMR with dynamic AWS KMS encryption
When processing data at scale, many organizations use Apache Spark on Amazon EMR to run shared clusters that handle workloads across tenants, business units, or classification levels. In such multi-tenant environments, different datasets often require distinct AWS Key Management Service (AWS KMS) keys to enforce strict access controls and meet compliance requirements. At the same […]
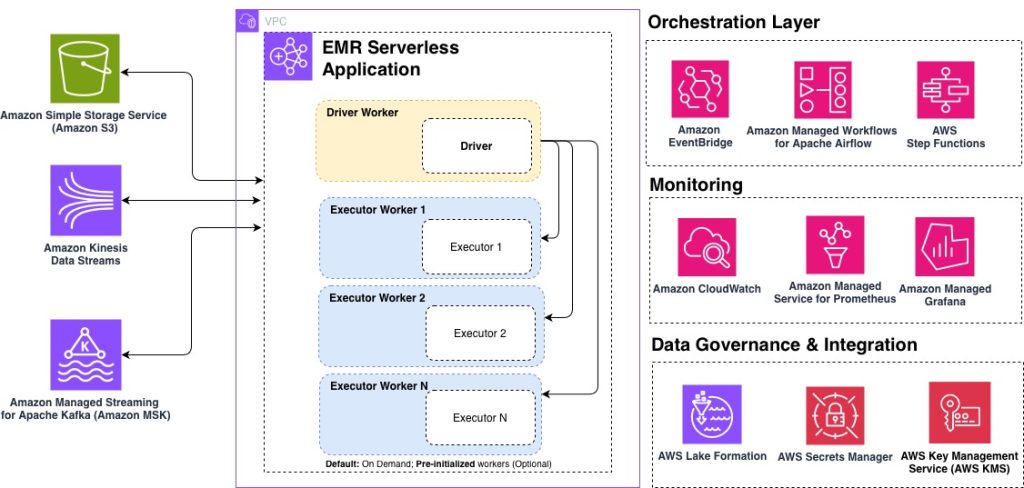
Top 10 best practices for Amazon EMR Serverless
Amazon EMR Serverless is a deployment option for Amazon EMR that you can use to run open source big data analytics frameworks such as Apache Spark and Apache Hive without having to configure, manage, or scale clusters and servers. Based on insights from hundreds of customer engagements, in this post, we share the top 10 best practices for optimizing your EMR Serverless workloads for performance, cost, and scalability. Whether you’re getting started with EMR Serverless or looking to fine-tune existing production workloads, these recommendations will help you build efficient, cost-effective data processing pipelines.

Apache Spark 4.0.1 preview now available on Amazon EMR Serverless
In this post, we explore key benefits, technical capabilities, and considerations for getting started with Spark 4.0.1 on Amazon EMR Serverless. With the emr-spark-8.0-preview release label, you can evaluate new SQL capabilities, Python API improvements, and streaming enhancements in your existing EMR Serverless environment.

Enterprise scale in-place migration to Apache Iceberg: Implementation guide
Organizations managing large-scale analytical workloads increasingly face challenges with traditional Apache Parquet-based data lakes with Hive-style partitioning, including slow queries, complex file management, and limited consistency guarantees. Apache Iceberg addresses these pain points by providing ACID transactions, seamless schema evolution, and point-in-time data recovery capabilities that transform how enterprises handle their data infrastructure. In this post, we demonstrate how you can achieve migration at scale from existing Parquet tables to Apache Iceberg tables. Using Amazon DynamoDB as a central orchestration mechanism, we show how you can implement in-place migrations that are highly configurable, repeatable, and fault-tolerant.
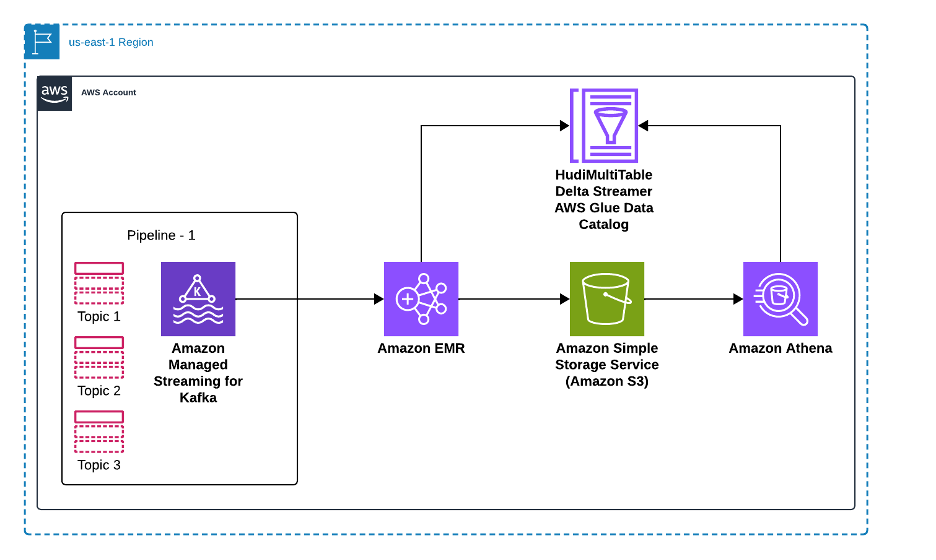
Using Amazon EMR DeltaStreamer to stream data to multiple Apache Hudi tables
In this post, we show you how to implement real-time data ingestion from multiple Kafka topics to Apache Hudi tables using Amazon EMR. This solution streamlines data ingestion by processing multiple Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics in parallel while providing data quality and scalability through change data capture (CDC) and Apache Hudi.

How Slack achieved operational excellence for Spark on Amazon EMR using generative AI
In this post, we show how Slack built a monitoring framework for Apache Spark on Amazon EMR that captures over 40 metrics, processes them through Kafka and Apache Iceberg, and uses Amazon Bedrock to deliver AI-powered tuning recommendations—achieving 30–50% cost reductions and 40–60% faster job completion times.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]

Amazon EMR Serverless eliminates local storage provisioning, reducing data processing costs by up to 20%
In this post, you’ll learn how Amazon EMR Serverless eliminates the need to configure local disk storage for Apache Spark workloads through a new serverless storage capability. We explain how this feature automatically handles shuffle operations, reduces data processing costs by up to 20%, prevents job failures from disk capacity constraints, and enables elastic scaling by decoupling storage from compute.