AWS Big Data Blog
Category: Amazon Redshift

A systematic approach to benchmarking SQL processing engines on AWS
Selecting the right SQL processing solution for large-scale data analytics is a critical decision for organizations. As data volumes grow exponentially, the technology landscape has evolved to offer diverse options for processing and analyzing this information efficiently. This post presents a systematic framework for evaluating and benchmarking SQL processing engines on AWS, using Apache JMeter to conduct practical performance testing at scale.

Meet Amazon Redshift RG – AWS Graviton-based instances with an integrated data lake query engine delivering up to 2.4x better performance at 30% lower price than RA3
On May 12, 2026, we announced the general availability of Amazon Redshift RG instances, powered by AWS Graviton processors. RG instances are up to 2.2x as fast for data warehouse workloads and up to 2.4x as fast for data lake workloads, all at 30% lower price per vCPU compared to RA3 instances. RG instances support all data lake formats supported by RA3 and eliminate Amazon Redshift Spectrum’s per-TB scanning charges. RG instances feature a custom-built integrated vectorized query engine, making them a more performant and cost-effective foundation for unified analytics. We are launching with two instance sizes: rg.xlarge and rg.4xlarge, with additional sizes coming later this year.

Optimize Amazon S3 Tables queries with Amazon Redshift
This is the third post in our S3 Tables and Amazon Redshift series. The first post covered getting started with querying Apache Iceberg tables, and the second post walked through enterprise-scale governance and access controls. In this post, you address those performance and usability gaps with three different approaches.

How to use streamlined permissions for Amazon S3 Tables and Iceberg materialized views
In this post, we walk through how to set up and manage S3 Tables in the AWS Glue Data Catalog, create and query Iceberg materialized views, and configure access controls that work across your analytics stack with IAM-based authorization.

Securely connecting on-premises data systems to Amazon Redshift with IAM Roles Anywhere
In this post, you will learn how to use AWS IAM Roles Anywhere with Amazon Redshift for secure, private connections. This removes the need to expose traffic to the public internet or manage long-lived access keys.

Getting started with Apache Iceberg write support in Amazon Redshift – Part 2
Amazon Redshift now supports DELETE, UPDATE, and MERGE operations for Apache Iceberg tables stored in Amazon S3 and Amazon S3 table buckets. With these operations, you can modify data at the row level, implement upsert patterns, and manage the data lifecycle while maintaining transactional consistency using familiar SQL syntax. You can run complex transformations in Amazon Redshift and write results to Apache Iceberg tables that other analytics engines like Amazon EMR or Amazon Athena can immediately query. In this post, you work with datasets to demonstrate these capabilities in a data synchronization scenario.

Proactive monitoring for Amazon Redshift Serverless using AWS Lambda and Slack alerts
In this post, we show you how to build a serverless, low-cost monitoring solution for Amazon Redshift Serverless that proactively detects performance anomalies and sends actionable alerts directly to your selected Slack channels.

Modernize business intelligence workloads using Amazon Quick
In this post, we provide implementation guidance for building integrated analytics solutions that combine the generative BI features of Amazon Quick with Amazon Redshift and Amazon Athena SQL analytics capabilities.
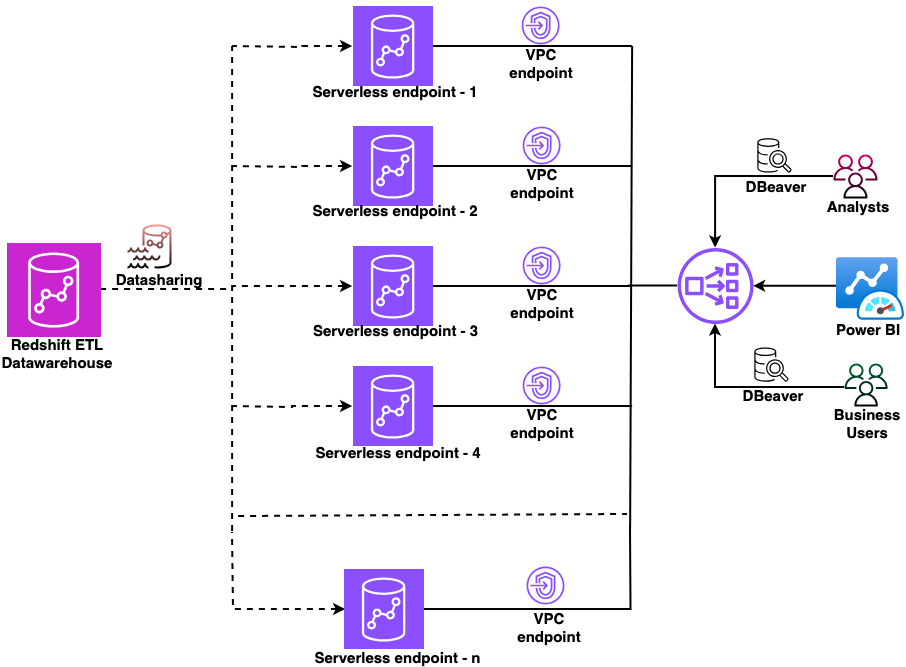
Secure multi-warehouse Amazon Redshift access behind a Network Load Balancer using Microsoft Entra ID
In this post, we show you how to configure a native identity provider (IdP) federation for Amazon Redshift Serverless using Network Load Balancer. You will learn how to enable secure connections from tools like DBeaver and Power BI while maintaining your enterprise security standards.
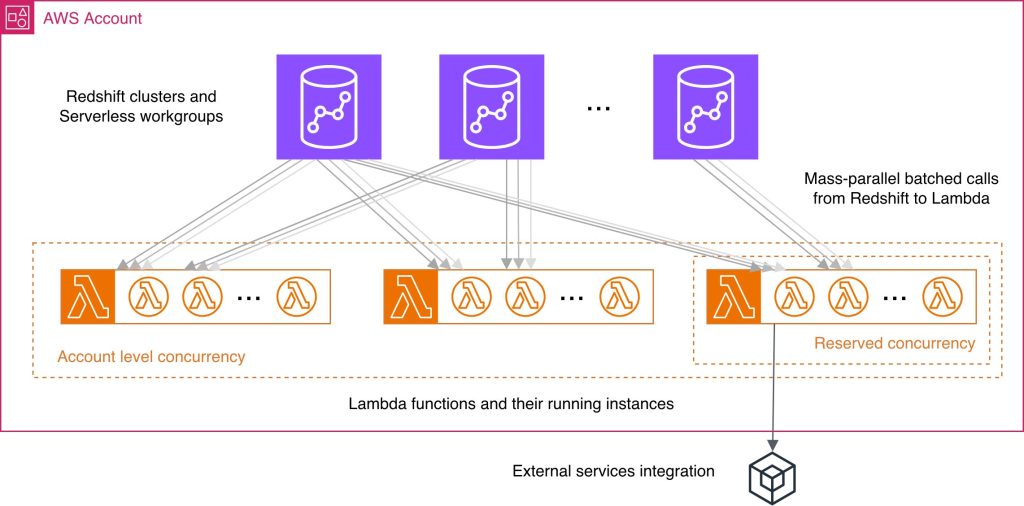
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.