AWS Big Data Blog
Category: Amazon Redshift

Build a data pipeline from Google Search Console to Amazon Redshift using AWS Glue
In this post, we explore how AWS Glue extract, transform, and load (ETL) capabilities connect Google applications and Amazon Redshift, helping you unlock deeper insights and drive data-informed decisions through automated data pipeline management. We walk you through the process of using AWS Glue to integrate data from Google Search Console and write it to Amazon Redshift.

Verisk cuts processing time and storage costs with Amazon Redshift and lakehouse
Verisk, a catastrophe modeling SaaS provider serving insurance and reinsurance companies worldwide, cut processing time from hours to minutes-level aggregations while reducing storage costs by implementing a lakehouse architecture with Amazon Redshift and Apache Iceberg. If you’re managing billions of catastrophe modeling records across hurricanes, earthquakes, and wildfires, this approach eliminates the traditional compute-versus-cost trade-off by separating storage from processing power. In this post, we examine Verisk’s lakehouse implementation, focusing on four architectural decisions that delivered measurable improvements.

How Zalando innovates their Fast-Serving layer by migrating to Amazon Redshift
In this post, we show how Zalando migrated their fast-serving layer data warehouse to Amazon Redshift to achieve better price-performance and scalability.
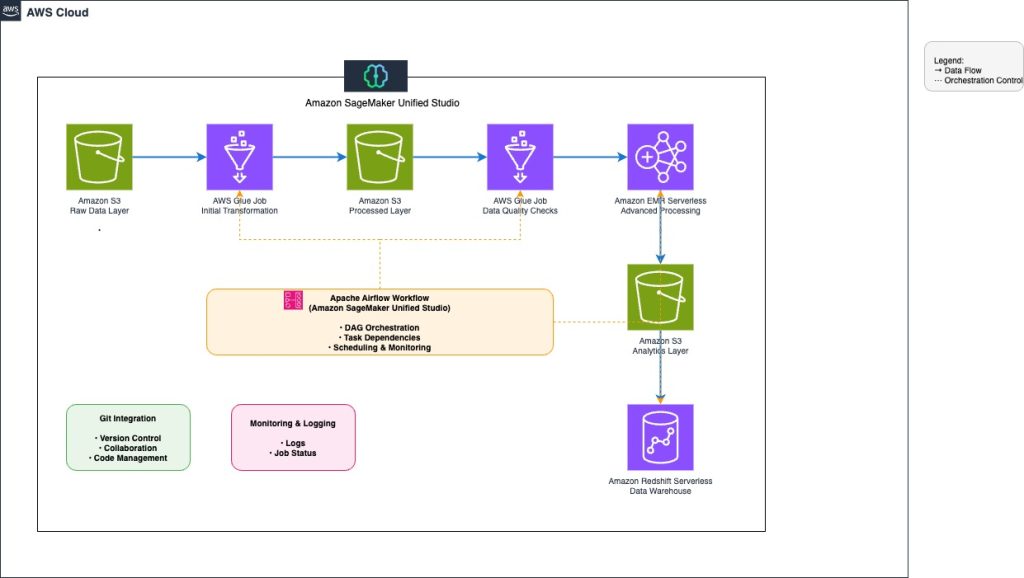
Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows
This post explores how to build and manage a comprehensive extract, transform, and load (ETL) pipeline using SageMaker Unified Studio workflows through a code-based approach. We demonstrate how to use a single, integrated interface to handle all aspects of data processing, from preparation to orchestration, by using AWS services including Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This solution streamlines the data pipeline through a single UI.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.

Streamline your Amazon Redshift maintenance event notifications with Amazon Simple Notification Service
In this post, we take you through customization options for managing the schedule of your Amazon Redshift maintenance events, along with Amazon Redshift maintenance tracks for optimizing cluster performance. We also walk you through how to set up Amazon Redshift event notifications using Amazon SNS.

Modernize your data warehouse by migrating Oracle Database to Amazon Redshift with Oracle GoldenGate
In this post, we show how to migrate an Oracle data warehouse to Amazon Redshift using Oracle GoldenGate and DMS Schema Conversion, a feature of AWS Database Migration Service (AWS DMS). This approach facilitates minimal business disruption through continuous replication.

Unlock granular resource control with queue-based QMR in Amazon Redshift Serverless
With Amazon Redshift Serverless queue-based Query Monitoring Rules (QMR), administrators can define workload-aware thresholds and automated actions at the queue level—a significant improvement over previous workgroup-level monitoring. You can create dedicated queues for distinct workloads such as BI reporting, ad hoc analysis, or data engineering, then apply queue-specific rules to automatically abort, log, or restrict queries that exceed execution-time or resource-consumption limits. By isolating workloads and enforcing targeted controls, this approach protects mission-critical queries, improves performance predictability, and prevents resource monopolization—all while maintaining the flexibility of a serverless experience. In this post, we discuss how you can implement your workloads with query queues in Redshift Serverless.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]

Simplify multi-warehouse data governance with Amazon Redshift federated permissions
Amazon Redshift federated permissions simplify permissions management across multiple Redshift warehouses. In this post, we show you how to define data permissions one time and automatically enforce them across warehouses in your AWS account, removing the need to re-create security policies in each warehouse.