AWS Big Data Blog
How Tophatter improved stability and lowered costs by migrating to Amazon Redshift RA3
This is a guest post co-written by Julien DeFrance of Tophatter and Jordan Myers of Etleap. Tophatter is a mobile discovery marketplace that hosts live auctions for products spanning every major category. Etleap, an AWS Advanced Tier Data & Analytics partner, is an extract, transform, load, and transform (ETLT) service built for AWS.
As a company grows, it continually seeks out solutions that help its teams achieve better performance and scale of their data analytics, especially when business growth has eclipsed current capabilities. Migrating to a new architecture is often a key component of this. However, a migration path that is painless, flexible, and supported is not always available.
In this post, we walk through how Tophatter—a virtual auction house where buyers and sellers interact, chat, and transact in diverse categories—recently migrated from DS2 to RA3 nodes in Amazon Redshift. We highlight the steps they took, how they improved stability and lowered costs, and the lessons other companies can follow.
Tophatter’s data storage and ETL architecture
Tophatter stores the majority of their product data in MySQL databases, while sending some webhook and web events to Amazon Simple Storage Service (Amazon S3). Additionally, some of their vendors drop data directly into dedicated S3 buckets. Etleap integrates with these sources. Every hour (according to the schedule configured by Tophatter), Etleap extracts all the new data that has been added or changed in the source, transforms the new data according to the pipeline rules defined by the user in the UI, and loads the resulting data into Amazon Redshift.
Tophatter relies on Mode Analytics and Looker for data analysis, and uses Etleap’s model feature based on Amazon Redshift materialized views to persist the results of frequently used business intelligence (BI) queries. Tophatter configures the update schedule of the model to happen at defined times or when certain source tables have been updated with new data.
Ultimately, these critical data pipelines fuel Tophatter dashboards that both internal analysts and users interact with.
The following diagram illustrates how Tophatter uses Etleap’s AWS-native extract, transform, and load (ETL) tool to ingest data from their operational databases, applications, and Amazon S3 into Amazon Redshift.

Company growth leads to data latency
Before the migration, Tophatter’s team operated 4 DS2 Reserved Instance (RI) nodes (ds2.xlarge) in Amazon Redshift, which use HDD drives as opposed to relatively faster SSDs.
As their user base expanded and online auction activity increased exponentially, Tophatter’s ETL needs grew. In response, Etleap seamlessly scaled to support their increased volume of ingestion pipelines and materialized data models. But Tophatter’s Amazon Redshift cluster—which they managed internally—wasn’t as easy to scale. When Amazon Redshift usage increased, Tophatter had to resize the cluster manually or reduce the frequency of certain analytics queries or models. Finding the optimal cluster size often required multiple iterations.
Due to the time-sensitive nature of data needed for live online auctions, Tophatter used automated monitoring to notify on-call engineers when data pipeline latency had exceeded the desired threshold. Latencies and errors began to pop up more frequently—at least once or twice a week. These events caused distress for the on-call engineers. When the issue couldn’t be resolved internally, they notified Etleap support, who typically recommended either canceling or reducing the frequency of certain long-running model queries.
While the issue was still being resolved, the latencies resulted in downstream issues for the analytics team, such as certain tables being out of sync with others, resulting in incorrect query results.
Migrating to Amazon Redshift RA3
To improve stability and reduce engineering maintenance, Tophatter decided to migrate from DS2 to RA3 nodes. Amazon Redshift RA3 with managed storage is the latest generation node type and would allow Tophatter to scale compute and storage independently.
With DS2 nodes, there was pressure to offload or archive historical data to other storage because of fixed storage limits. RA3 nodes with managed storage are an excellent fit for analytics workloads that require high storage capacity, such as operational analytics, where the subset of data that’s most important continually evolves over time.
Moving to the RA3 instance type would also enable Tophatter to capitalize on the latest features of Amazon Redshift, such as AQUA (Advanced Query Accelerator), Data Sharing, Amazon Redshift ML, and cross-VPC support.
RA3 migration upgrade program
Tophatter understood the benefits of migrating to RA3, but worried that their 3-year DS2 Reserved Instances commitment would present a roadblock. They still had 2 years remaining in their agreement and were unsure if an option was available that would allow them to change course.
They found out about the AWS RA3 upgrade program from the AWS account team, which helps customers convert their DS2 Reserved Instance commitments into RA3 without breaking the commitment agreement. This path enables you to seamlessly migrate from your legacy Amazon Redshift clusters to one of three RA3 node types: ra3.xlplus, ra3.4xlarge, or ra3.16xlarge.
Tophatter’s engagement with the program consisted of five steps:
- Engage with the AWS account team.
- Receive pricing information from the AWS account team.
- Schedule the migration.
- Purchase RA3 Reserved Instances.
- Submit a case to cancel their DS2 Reserved Instances.
Tophatter had the opportunity to evaluate three options for their RA3 migration:
- Elastic resize – This is the most efficient way to change the instance type and update the nodes in your Amazon Redshift cluster. The cluster endpoint doesn’t change and the downtime during resize is minimal.
- Snapshot and restore method – Choose the snapshot and restore method if elastic resize is unavailable (from a mismatch between slice and node count). Or, use this method to minimize the amount of time it takes to write to your production database.
- Classic resize – Choose the classic resize method if it’s the only option available. For single-node DS2 clusters, only a classic resize can be performed to convert the cluster into a multi-node cluster.
Achieving operational goals
Tophatter worked closely with their AWS account team for the migration and chose elastic resize due to the minimal downtime that option presented as well as prior experience using it. They completed the migration in under 2 hours, which included the requisite pre- and post-testing. As a pre-migration step, they took a snapshot of the cluster and were prepared to restore it if something went wrong.
After migrating to a 2 node ra3.4xlarge cluster, the Tophatter team realized numerous benefits:
- Storage with up to 256 TB of Amazon Redshift managed storage for their cluster
- Dramatically reduced latency of ingestion and data modeling
- Control of the compute and storage capacities and costs, independently
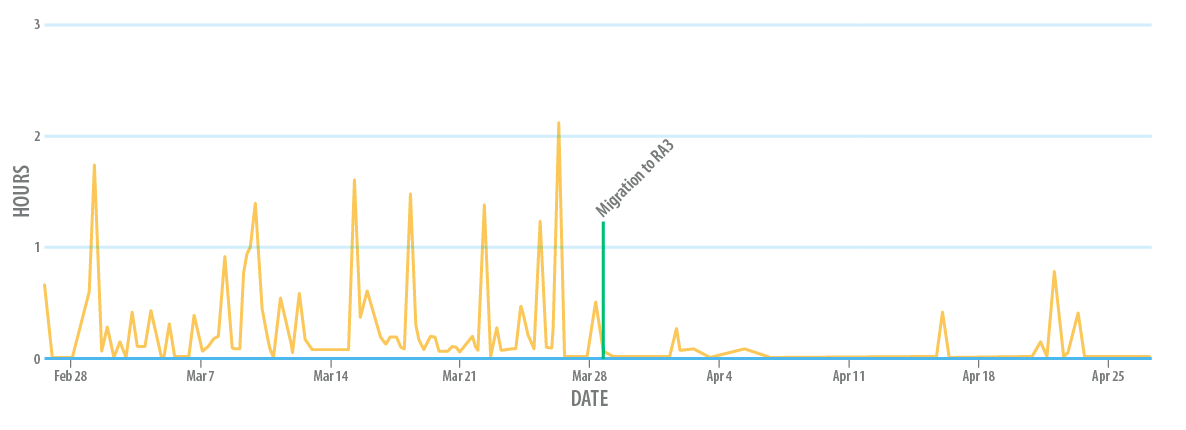
- Better system stability, with latency incidents requiring on-call engineer responses dropping to near zero
The following graph illustrates the average latency of a typical ingestion pipeline before and after the migration from DS2 to RA3.
Conclusion
When Tophatter set out to migrate their DS2 instances to RA3, they were unaware of the AWS RA3 upgrade program and its benefits. They were happy to learn that the program avoided the administrative overhead of getting approvals ahead of time for various specific configurations, and let them try several options in order to find a stable configuration.
Tophatter migrated from DS2 to RA3 without breaking their current commitment and enhanced their analytics to be agile and versatile. Now, Tophatter is aiming to realize greater scaling benefits to support its exponential growth by exploring new RA3 features such as:
- Amazon Redshift Data Sharing – Provides instant, granular, high-performance data access without data copies or movement
- Amazon Redshift ML – Allows you to create, train, and apply machine learning models using SQL commands in Amazon Redshift
- AQUA – Provides a new distributed and hardware accelerated cache that brings compute to the storage layer for Amazon Redshift and delivers up to 10 times faster query performance than other enterprise cloud data warehouses
- Cross-VPC support for Amazon Redshift – With an Amazon Redshift-managed VPC endpoint, you can privately access your Amazon Redshift data warehouse within your VPC from your client applications in another VPC within the same AWS account, another AWS account, or running on-premises without using public IPs or requiring encrypted traffic to traverse the internet
We hope Tophatter’s migration journey can help other AWS customers reap the benefits from the AWS RA3 upgrade program from DS2 or DC2 cluster families to RA3. We believe this enables better performance and cost benefits while unlocking valuable new Amazon Redshift features.
About the Authors
 Julien DeFrance is a Principal Software Engineer at Tophatter based out of San Francisco. With a strong focus on backend and cloud infrastructure, he is part of the Logistics Engineering Squad, building and supporting integrations with third parties such as sellers, ERP systems, and carriers, architecting and implementing solutions to help optimize cost efficiency and service quality. Julien holds two AWS Certifications (Cloud Practitioner, Solutions Architect – Associate).
Julien DeFrance is a Principal Software Engineer at Tophatter based out of San Francisco. With a strong focus on backend and cloud infrastructure, he is part of the Logistics Engineering Squad, building and supporting integrations with third parties such as sellers, ERP systems, and carriers, architecting and implementing solutions to help optimize cost efficiency and service quality. Julien holds two AWS Certifications (Cloud Practitioner, Solutions Architect – Associate).
 Jordan Myers is an engineer at Etleap with 5 years of experience in programming ETL software. In addition to programming, he provides deep-level technical customer support and writes technical documentation
Jordan Myers is an engineer at Etleap with 5 years of experience in programming ETL software. In addition to programming, he provides deep-level technical customer support and writes technical documentation
 Jobin George is a Big Data Solutions Architect with more than a decade of experience designing and implementing large-scale big data and analytics solutions. He provides technical guidance, design advice, and thought leadership to some of the key AWS customers and big data partners.
Jobin George is a Big Data Solutions Architect with more than a decade of experience designing and implementing large-scale big data and analytics solutions. He provides technical guidance, design advice, and thought leadership to some of the key AWS customers and big data partners.
 Maneesh Sharma is a Senior Database Engineer with Amazon Redshift. He works and collaborates with various Amazon Redshift Partners to drive better integration. In his spare time, he likes running, playing ping pong, and exploring new travel destinations.
Maneesh Sharma is a Senior Database Engineer with Amazon Redshift. He works and collaborates with various Amazon Redshift Partners to drive better integration. In his spare time, he likes running, playing ping pong, and exploring new travel destinations.