Containers
AWS Proton Terraform Templates
At re:Invent 2020, AWS launched a new service, AWS Proton, aimed at helping automate and manage infrastructure provisioning and code deployments for serverless and container-based applications. At launch, AWS CloudFormation was the only option available to customers for provisioning their infrastructure through AWS Proton. Supporting HashiCorp Terraform is currently the most upvoted item on our public roadmap, so it quickly became a post-launch priority.
In 2021, AWS Proton launched support for two new features:
- The ability to register AWS Proton templates that are written in HashiCorp Configuration Language (HCL), and
- Self-managed provisioning workflows by way of a pull request to a customer-owned git repository.
This is part one of two blog posts regarding this release. In this post, we address the first feature mentioned above, authoring AWS Proton templates using Terraform.
If you want to read part two, where the second feature is discussed, go to AWS Proton Self-Managed Provisioning.
Overview of AWS Proton
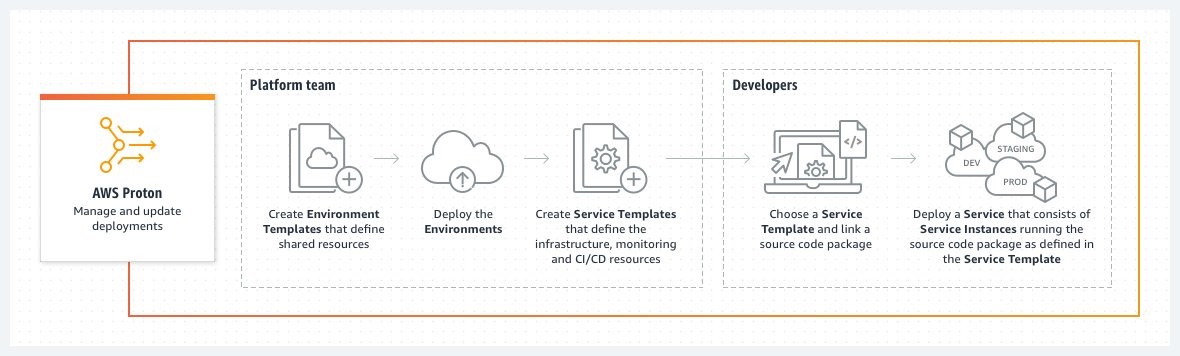
Before diving into the specifics of this feature, we’ll briefly go over AWS Proton as a product. If you are already familiar with the product, feel free to skip this section.
AWS Proton is divided into two primary experiences: template management and template deployment. Templates are an abstraction layer that empower infrastructure experts within an organization to create reusable infrastructure as code bundles. Essentially an AWS Proton template allows a single administrator to write up a generic infrastructure as a code template, such as a CloudFormation file, and extract out configurable parameters. Then developers need only provide those parameters at deployment time to get an equivalent set of infrastructure up and running.
This abstraction is further broken down into two types of resources: environments and services. An environment is a combination of a collection of shared resources that are available to the service instances running in that environment. A service is then the infrastructure required for the application being developed. Services instances get deployed into environments. This is an important concept in AWS Proton.
When creating an environment, part of what the administrator must provide to AWS Proton is some metadata to aid AWS Proton in provisioning any associated infrastructure. A key component of this metadata is either an AWS service role, an AWS Proton environment account connection, or, as of this feature release, a Git repository.
Authoring Terraform template bundles
There are two major things we need to think about when approaching authoring an AWS Proton template bundle:
- The infrastructure you want to provision (and the language you want to use to represent it), and
- What you want to abstract out as inputs to make your template reusable within AWS Proton.
In this next section, we’re going to be looking at authoring a service template that produces a Lambda function which will run inside of a VPC that was configured in an AWS Proton environment (the following chart demonstrates what we’re working on).
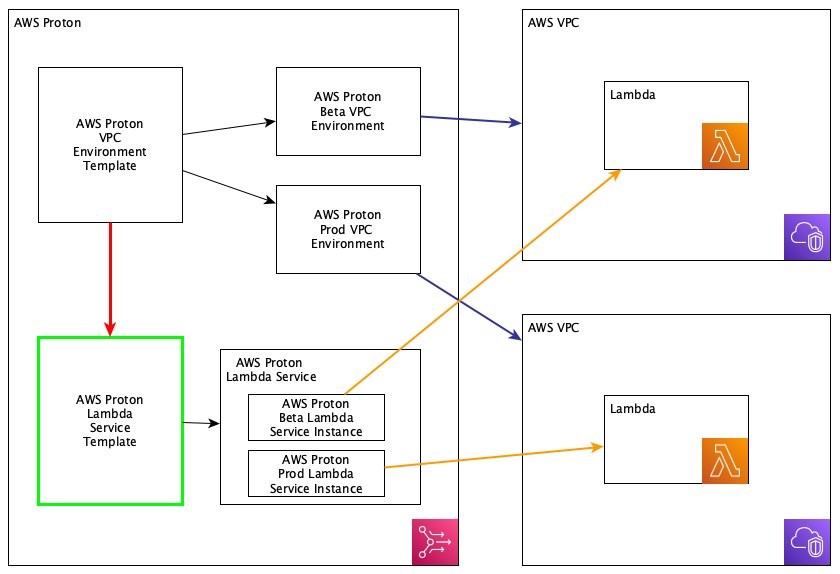
I’d like to call your attention to a few things in the previous chart. The green box (labeled AWS Proton Lambda Service Template) represents the service template we are going to be writing, which will deploy the resources into our two VPC environments. The red line (connecting VPC Template and Service Template) shows that there is a relationship between the VPC environment template and our service template. In AWS Proton, service templates can inherit outputs from the provisioning of the environment, so we’ll take a look at how that works as well.
Multiple Terraform files
Something new with this launch is the ability to have more than just one infrastructure-as-code file in your bundle. With CloudFormation, that requirement remains, but for Terraform, it is very common to have logical .tf file separations, so we wanted to ensure that this experience remained consistent when authoring Terraform templates within AWS Proton.
HCL variables
For CloudFormation, parameterization is handled via Jinja, a popular templating engine. HCL already has a very mature variable system, so we decided to use that for parameterizing AWS Proton inputs instead of reusing Jinja.
We’ll begin with an overview of the terraform configuration we are going to be using before we convert it into an AWS Proton template.
config.tf
In our first file config.tf, we are indicating that we will be using the AWS provider.
lambda.tf
In lambda.tf, we are creating the function and the role for Lambda to assume to execute the function, using source code stored in Amazon S3, and that function is running inside of our VPC.
outputs.tf
Finally, outputs.tf is outputting the application reference number (ARN) of the function we created.
Now our goal is to create a reusable AWS Proton service template for a Lambda function where it is ensured that the function will execute within a VPC and will only have a specific set of permissions for the Lambda.
We are going to start by creating a new directory elsewhere that should look like the following in terms of structure.
We introduced two new files: manifest.yaml and schema.yaml, and then we also reorganized our structure a little bit to align with the AWS Proton template bundle structure.
The purpose of the manifest is to indicate to AWS Proton which files in that directory it should concern itself with. Currently, only files ending in .tf are supported for terraform. The following shows the contents of the manifest.yaml.
Now for the more interesting bits. Let’s think about what in our lambda.tf file we want to make configurable for the person trying to deploy our template. Developers within our organization like to use a good mix of Lambda runtimes, so we, as the AWS Proton administrator or platform team, should make that configurable, and then anything related to that (that is, function location, handler, name, and so on). Additionally, we want to require that VPC information be supplied. However, if you recall our previous chart, we want that to come from the environment, not the person deploying the template.
So let’s write our AWS Proton schema.yaml, which is used to declare the inputs to our function.
You may have noticed there is no VPC information. I’m probably sounding redundant, but rest assured, we’re going to get that from the environment. The schema is just to declare the information that is required to be supplied by the developer directly at deployment time.
And finally, let’s make the necessary changes to our lambda.tf to incorporate these variable inputs.
If you look through those variables, you will see I am referencing two different variable namespaces. The first namespace, var.service_instance.inputs, should contain references to things that are familiar to you since they came from the schema. The second namespace, var.environment.outputs, is new. What I’m doing here is telling AWS Proton to retrieve outputs from the environment we deploy this service_instance into, in this case, our VPC environment, which must output a subnet and a security group.
For a full list of the available parameters to use based on template scope, visit Parameters in the AWS Proton Administrator Guide.
Note on environment template compatibility
You may be wondering how to ensure that your service template gets deployed to an environment with the necessary outputs. For that, AWS Proton has a concept of compatibility between environment templates and service templates. This is declared at service template registration time. And then at service creation time, the only environments that the instances can be deployed to are those that were instantiated using a compatible template.
And we’re done! In the next section, we’ll review registering the template within AWS Proton.
Registering your template
If you are already familiar with the process for registering AWS Proton templates, you can skip this section. This is a walkthrough for how to register templates, and the good news about Terraform templates is that once you’ve completed authoring them, the process to get them registered within AWS Proton is identical to that of CloudFormation based templates.
Prerequisites
If you’d like to work alongside this walkthrough, you will need:
- an AWS account
- an S3 bucket
Walkthrough
For our purposes here, to simplify things, I’ve already gone ahead and created an environment template that you can use over in our samples repository. Start by cloning https://github.com/aws-samples/aws-proton-terraform-sample-templates. There are a couple of templates here; the one we are interested in is located at lambda-vpc/sample-vpc-environment-template/v1. Peek around and see what it’s creating. We are relying on the Terraform Amazon VPC module to configure a VPC. One thing you should definitely take a look at is infrastructure/outputs.tf. It should look something like the following. If you take a look back at our lambda.tf file that we templatized for AWS Proton, you can see that the outputs here align with the environment outputs referenced there.
- Now run the following commands at the root of the repo:
- Then upload terraform-vpc-env.tar.gz to any location you want in your S3 bucket.
- Now sign in to your AWS Management Console and navigate over to https://console.aws.amazon.com/proton/home#/templates/environments and select the link to Create environment template and fill out the form. Make sure to select Use your own template bundle, and where it asks for an S3 location, find where you uploaded the template.
- Next, you’ll be navigated to the template details page. Within a few seconds, it should be ready to publish.
- When you see a button that says Publish v1.0, select it.
And it’s published! This can now be deployed. We’re not going to do that for now. We take a look into that in part two, AWS Proton Self-Managed Provisioning.
Fun fact! This repository is actually set up to work with another new feature within AWS Proton, which is Template Syncing. If you’d like to learn more about that, you can check out Template sync configurations in the AWS Proton Administrator Guide.
Now we’re ready to register the template we wrote in the first half of this post.
- Go to https://console.aws.amazon.com/proton/home#/templates/services and select Create service template.
This form should look pretty familiar if you followed along with the last step. A primary difference to understand when creating service templates is that a service template must declare its compatibility with a given environment template. So when you get to that point, make sure you select the environment template we just created. Fill out the rest of the form and follow the same steps to publish.
And that’s it! We just successfully wrote and registered a service template within AWS Proton.
If you’d like to learn how to get these Terraform templates deployed, head on over to the second part of this two-part blog AWS Proton Self-Managed Provisioning, or check the wiki in our sample repository.
Closing thoughts
Keeping a well-manicured cloud footprint can be very tricky. You want to find a balance between offering the developers in your organization the flexibility to build their applications to the best of their abilities while also enforcing security and reliability best practices. Additionally, you want to reduce the amount of duplicate work occurring within your organization. AWS Proton aims to make the process for achieving these goals a much more manageable task. Part of that task is also supporting the tools you know and love, and using templates authored with HCL is just the first step towards achieving that goal!
Now get templating!