Containers
AWS Proton Self-Managed Provisioning
This is part two of two blog posts regarding this release: in this post, we address a second feature that recently launched, which is connecting AWS Proton with a self-managed provisioning workflow. To read part one, where we cover how to author AWS Proton Templates using HashiCorp Configuration Language (HCL) and Terraform, see AWS Proton Terraform templates. Also if you are not familiar with AWS Proton I recommend reading part one, where we give a bit of an overview of the product as a whole.
AWS-managed provisioning with CloudFormation
Prior to this release, AWS Proton supported a single AWS-managed provisioning option. With AWS-managed provisioning, the administrator hands over credentials for a supported provisioning tool (AWS CloudFormation and AWS Identity and Access Management (IAM) Service Roles at the moment), and then AWS Proton handles the rest. This option is great if you want AWS Proton to handle all the work associated with provisioning and don’t have any customizations you wish to apply.
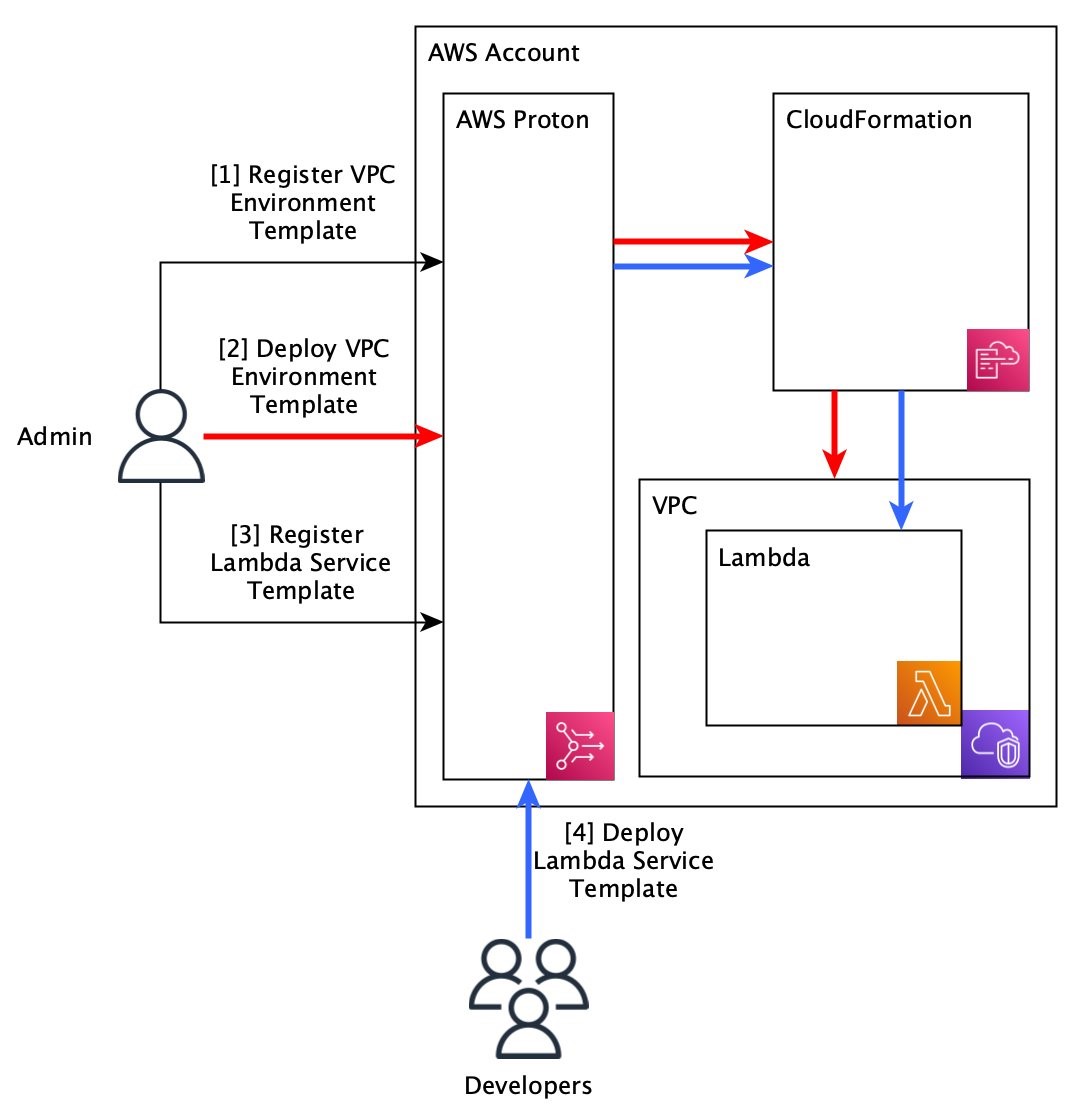
Roles and responsibilities within AWS-managed provisioning
Within AWS Proton, we’ve identified two roles that will interact with the service.
The first role is the administrator, or the user who authors AWS Proton templates. This role is generally responsible for establishing best practices and ensuring infrastructure across the organization aligns with those practices. They should also own and maintain AWS Proton environments.
The other role is that of the developer, or the user responsible for building applications within their organization. To simplify the developer’s experience and allow them to focus on application design, AWS Proton aims to eliminate the need for developers to interact with anything related to the infrastructure provisioning.
Self-managed provisioning with Terraform
As described above, AWS Proton now supports a self-managed provisioning option, where AWS Proton compiles your template and then submits it as a pull request to a Git repository that you configure. From that point on, it is your responsibility to execute that template (that is, run the terraform apply command on it) and then notify AWS Proton of the outcome.
The self-managed provisioning option includes the following steps:
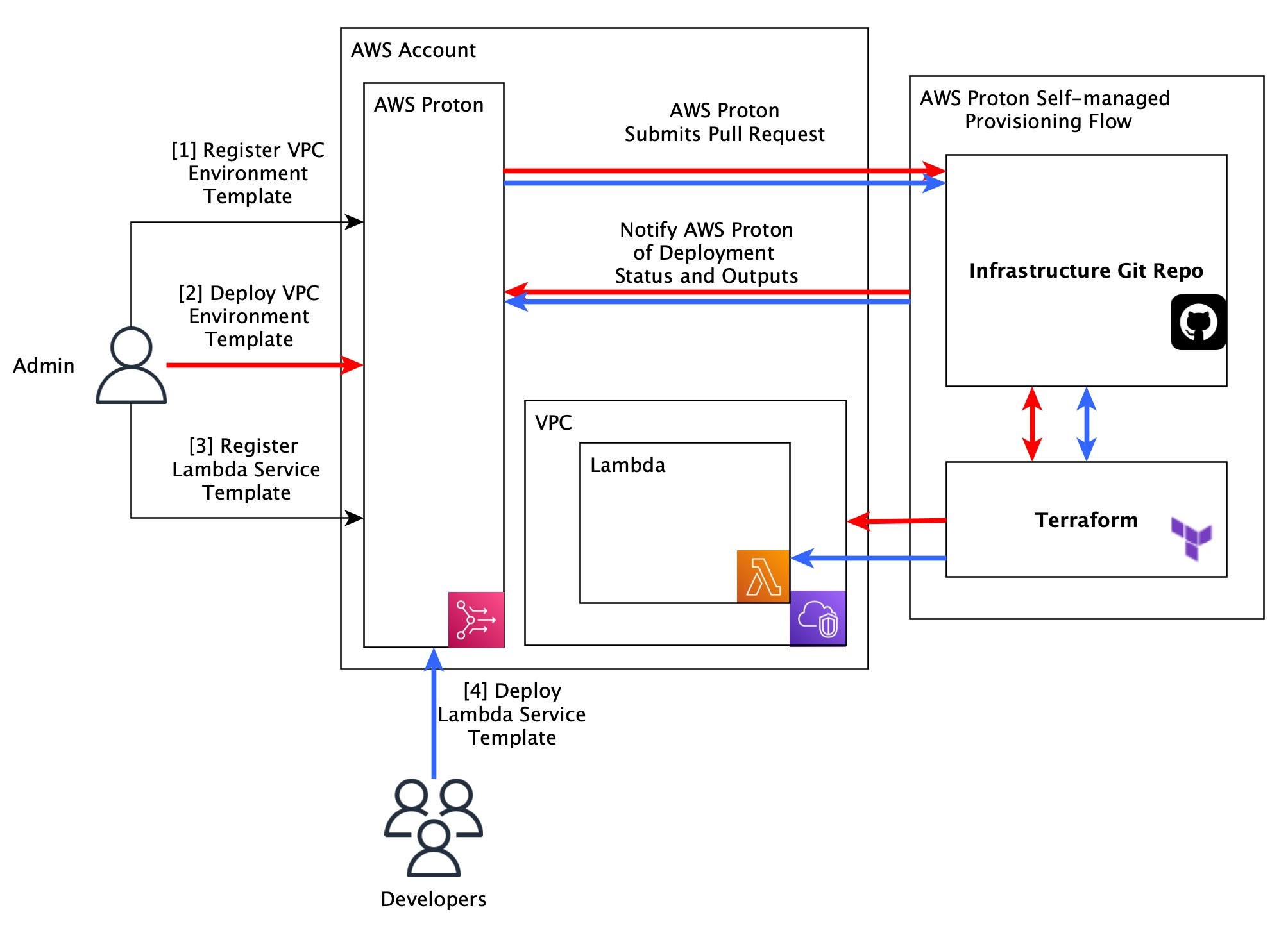
With this option, there are a few more steps involved in provisioning the infrastructure; however, if done correctly, most of the steps can be configured as part of an initial setup step.
Roles and responsibilities within self-managed provisioning
In a world of self-managed provisioning, administrators are likely the users responsible for managing the self-managed provisioning workflow. At minimum, they need to do the initial setup, but depending on organizational policies, they might have to continually approve the AWS Proton pull requests to ensure safe deployments.
Having the administrators manage that process keeps infrastructure management out of the developers’ hands. Ideally, the self-managed provisioning flow will be completely automated by the time Developer Services interacts with it, and they will simply await completion of their deployments within the AWS Proton experience.
This next chart offers a closer look at the involvement of various actors in the creation of an AWS Proton environment (shown by the red lines in the self-managed provisioning chart above):
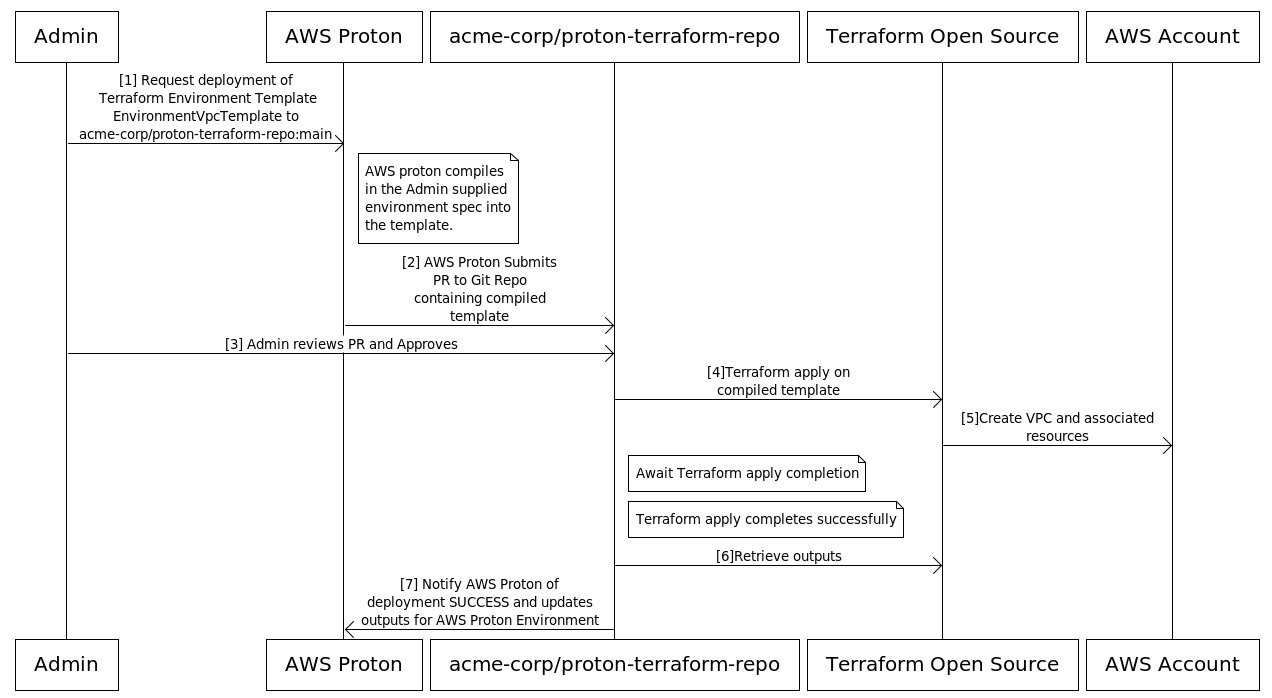
As mentioned previously, developers don’t need to create environments. Now let’s take a look at service creation (shown by the blue lines in the self-managed provisioning chart above).
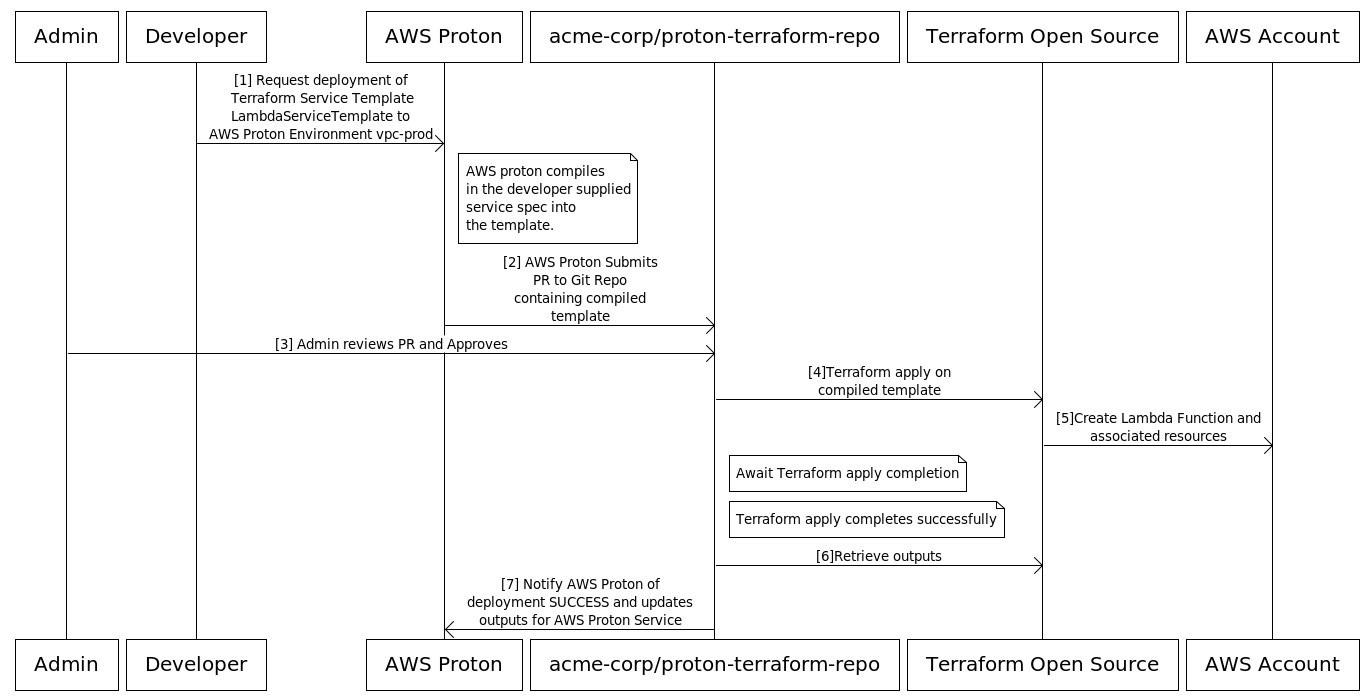
At the time of writing this post, Terraform is the only supported option for self-managed provisioning within AWS Proton.
Pull request format
Arguably the most important concept to understand is the directory structure that AWS Proton will use to manage your Git repository. Understanding this is central to building automation to execute Terraform in response to a merged pull request.
As mentioned in part one, an important concept within AWS Proton is the relationship between environments and services. Again, services are deployed into environments. This remains true for the structure of the repositories that are used alongside the self-managed provisioning scheme.
When creating an environment, you provide a repository and branch where you would like the pull requests to be submitted. Then AWS Proton creates the pull request, and the compiled Terraform is placed into a directory with the same name as that of the environment. When creating a service, AWS Proton will derive the repository and branch from the target environment and place the service in that environment’s directory within a sub-directory named for the service. The chart below illustrates that relationship:
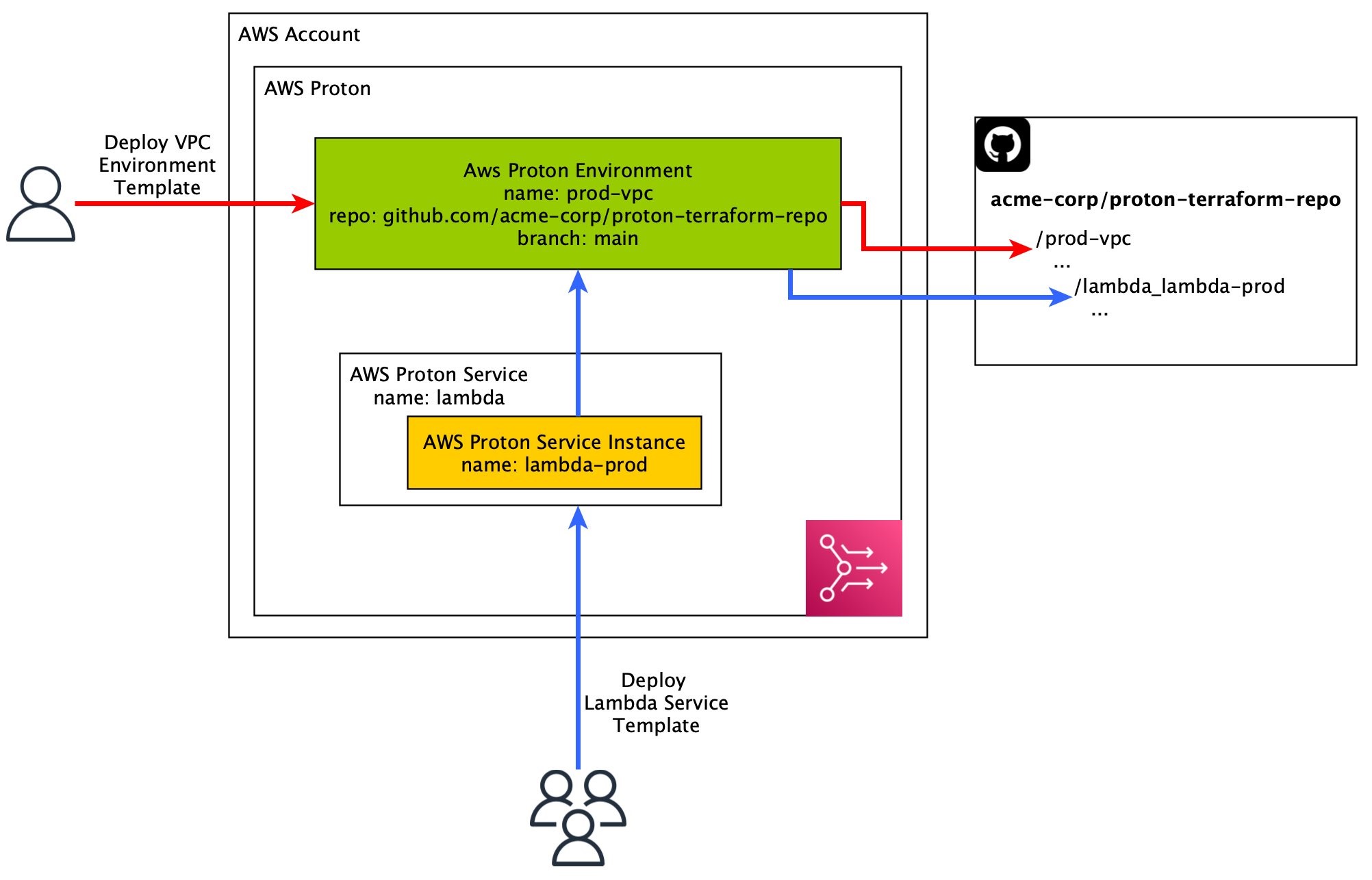
Let’s take a closer look.
Say you have the following resources:
- A Git repository called acme-corp/proton-terraform-repo
- For the purposes of our example, we will state that this repository is hosted on GitHub
- An environment template called EnvironmentVpcTemplate
- This template contains three files: config.tf, vpc.tf, and outputs.tf
- A service template called LambdaServiceTemplate
- This template contains three files: config.tf, lambda.tf, and outputs.tf
Now say you want to create an environment from EnvironmentVpcTemplate, called vpc-prod, which will be deployed to acme-corp/proton-terraform-repo:main. After the initial deployment, the repository will look something like the following:
You can see a directory corresponding to the name of your environment, along with the files from the corresponding environment templates (plus some additional files, which we’ll get in to later).
Now let’s say you want to use LambdaServiceTemplate to create a service called lambda-prod and then deploy that service to vpc-prod. You would go through the typical deployment steps and eventually your repository would look like the following:
The bolded lines indicate a newly added directory under the vpc-prod/lambda-prod directory that contains the Lambda service’s compiled Terraform code.
Let’s address how this actually ends up working in practice: AWS Proton will create a new branch for each pull request and push to that branch. Then the pull request will be a merge request from that branch into the branch you created when you configured the environment. Once you’ve merged the pull request, you can feel free to delete the branch created by AWS Proton.
Variable injection
A key aspect of AWS Proton Templates is that they are reusable across varying applications through an input variable system. For Terraform, that is handled using Terraform’s built-in variable language. For example, for an environment, you might reference inputs such as var.environment.inputs.vpc_name (for a complete list of usable parameters, see the AWS Proton Parameters documentation).
To provide values for these variables, AWS proton will generate two files: a variables.tf file and proton.auto.tfvars.json. The file ending in variables.tf is where the definitions for the variables are provided, and proton.auto.tfvars.json is the actual assignment of values to those variables. Generally speaking, these files should not require any input or action from you; they should just work when you run Terraform.
deployment-metadata.json
There is one last file to be aware of: .proton/deployment-metadata.json. AWS Proton will create this for every resource and include it in the pull request alongside the rest of the compiled template. This file is very important because it is the primary way in which AWS Proton can communicate with your automation. The following is an example of what that file might look like:
We will cover the specific uses of some of the fields later on, specifically deploymentId and resourceMetadata.arn. Some of the fields are largely informational and not necessarily required as part of the actual provisioning flow, including anything relating to the template. They can be useful, though, if you want to easily retrieve information about the underlying template that AWS Proton uses to create the pull request.
Your first self-managed provisioning workflow
The rest of this post will focus on providing you with the necessary understanding for setting up your self-managed provisioning workflow. This information is intended to get you in the necessary mindset for self-managed provisioning—the beauty and power of the self-managed feature is in the enormous degree of flexibility it allows you.
If you want to see a full example of automation set up for executing Terraform, check out our sample repository, which contains a fully working GitHub Actions workflow for responding to AWS Proton pull requests.
The following chart demonstrates the flow of tasks that should be completed throughout the lifecycle of a self-managed provisioning workflow:

Now we’ll go step by step to understand what each task means and what you can to do to accomplish them. The first two steps happen within AWS Proton, so you don’t need to worry about those.
Determine which resource is being modified
Recall the deployment-metadata.json we discussed in the previous section. It contains information regarding the specific AWS Proton resource that is getting modified. All you need is a JSON parser, and you can grab deploymentId and resourceMetadata.arn from the deployment-metadata.json file that was modified in the pull request. AWS Proton will modify only one instance of those files per pull request. The sample automation leverages jq, a popular command line tool for parsing JSON. An example, the following command shows how to leverage jq to retrieve the ARN of the resource from the deployment-metadata.json file.
$ jq -r '.resourceMetadata.arn' .proton/deployment-metadata.json
If the resource is a service instance, you might also need to retrieve information about the environment. The deployment-metadata.json file will tell you which environment it is being deployed to so you can locate that information. The file will look like the following:
Retrieve credentials for the resource
The final bit of configuration required to run Terraform will be the AWS credentials you use to actually execute Terraform (that is, the account you want to provision the resources in) and any other credentials you might require. In following the existing AWS Proton patterns, we recommend that you configure credentials per environment, though the choice is really up to you. One way to accomplish this is to maintain a mapping in your repository from the AWS Proton environment name to the required credentials, such as the following:
Now when a pull request is triggered and you determine the environment being deployed into, the automation will simply retrieve the corresponding credentials by assuming the role.
Run Terraform
At this point, the automation has successfully retrieved all the information required to provision the template. Next, Terraform needs to be initialized inside the directory of the resource to be provisioned. In the example above, if vpc-prod is getting updated, the automation will need to change the directory into the vpc-prod/ directory and then run terraform init.
One thing to consider at this point is how you will handle the Terraform state information. It’s typically recommended that you store your state file in a remote location, such as the Amazon Simple Storage Service (S3). An additional protection mechanism offered by Terraform is state locking, which prevents concurrent runs on the same state file. Regardless of what you decide, you will want to consider how that is configured.
Once Terraform is initialized, all you have to do is run terraform apply and your infrastructure will be provisioned!
Notify AWS Proton of deployment result and infrastructure outputs
This is the final step in your automation. AWS Proton keeps the latest status of your infrastructure provisioning, as well as any output data, so that you can get an overview of your application deployment health from the details page. With an AWS-Managed provisioning option such as CloudFormation, AWS Proton can track the progress of your deployment directly because AWS Proton is the one that triggered the deployment. However, with the self-managed option, AWS Proton has no way of no knowing how to get the information, so you must notify the service of any status changes. This is done via a single API call to AWS Proton: NotifyResourceDeploymentStatusChange.
Handling deletes
The final step in the lifecycle of your infrastructure management is what to do when you no longer need it. In this case, AWS Proton will submit a final pull request with a modification to the deployment-metadata.json file where the isResourceDeleted flag will now be set to true. You can use this flag in your automation flow to run a terraform destroy instead of a terraform apply when it is set to true.
Again, if you’d like to see an example, take a look at our sample repository. We have an in-depth walk-through for setting up a possible Terraform automation via GitHub Actions. GitHub Actions is by no means a requirement; we chose it for the convenience of implementation, but you should feel free to use whatever CI/CD system you are most comfortable with.
Closing thoughts
The way in which different organizations provision cloud infrastructure can vary so much. Some people like CloudFormation, whereas some prefer Terraform. Within Terraform are Terraform Open Source and Terraform Cloud. And within Terraform Open Source, there are a large number of tooling options for actually configuring and running it. Some organizations require human approvals before a change can be deployed, whereas others build robust approval automation. With self-managed provisioning in AWS Proton, you get the benefit of the template management system, which allows stricter control over the infrastructure being deployed, while still having the freedom to provision that infrastructure exactly as you like it.