Containers
Capturing logs at scale with Fluent Bit and Amazon EKS
Earlier this year, AWS support engineers noticed an uptick in customers experiencing Kubernetes API server slowness with their Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Seasoned Kubernetes users know that a slow Kubernetes API server is often indicative of a large, overloaded cluster or a malfunctioning controller. Once support engineers ruled out cluster size as a culprit, the AWS Support team turned to analyze API server requests. They found that log aggregators, both Fluentd and Fluent Bit, when operated at scale, overwhelm the API servers.
Kubernetes failure stories is littered with instances of Kubernetes clusters becoming unstable when controllers malfunction and flood the API server. The Kubernetes API Server services REST operations and provides the frontend to the cluster’s shared state through which all other components interact, including users using kubectl. If one of those components sends too many requests, the API servers can become slow, or worse, unresponsive. Log aggregators frequently query the API servers to fetch pod metadata; that’s how Fluentd and Fluent Bit discern which log files belong to which pods.
In most clusters, using Fluentd or Fluent Bit for log aggregation needs little optimization. This changes when you’re dealing with larger clusters with thousands of pods and nodes. We recently published our findings from studying the impact of Fluentd and Fluent Bit in clusters with thousands of pods. This post demonstrates a recent enhancement to Fluent Bit that is designed to reduce the volume API calls it makes to the Kubernetes API servers.
The Use_Kubelet option
Fluent Bit queries the kube-apiserver to fetch pod metadata to match log files with pods. As the number of pods increases in a cluster, the number of log files that Fluent Bit DaemonSets have to process increases as well, which leads to a surge of API requests being sent to the kube-apiserver. Eventually, the API server gets flooded with requests and becomes unresponsive, bringing operations in that cluster to a halt.
Last year, the Fluent Bit community proposed alleviating performance issues faced by customers that run clusters with more than 5000 pods. The suggestion was to retrieve pod metadata from a node’s kubelet instead of kube-apiserver. Earlier this year, Fluent Bit added a new filter: Use_Kubelet. When this filter is set to true, Fluent Bit DaemonSets query the kubelet of the node they are operating to fetch metadata. When enabled, this filter reduces the load on kube-apiserver, and improves cluster’s scalability.
The kubelet’s secure API endpoint allows Fluent Bit to retrieve that pod ID, labels, and annotations without putting a strain on the kube-apiserver. In our lab testing, we were able to use this filter to run a cluster with 30,000 pods. Without this filter enabled, a Kubernetes cluster with 30,000 pods and Fluent Bit for log aggregation has roughly a 45 second API response latency.
Configure Fluent Bit to query kubelet
Implementing this change is straightforward. First, you’ll have to configure the ClusterRole used by Fluent Bit to allow access to the nodes and ndoes/proxy resources.
Here’s a sample manifest to create a service account, ClusterRole, and ClusterRoleBinding for Fluent Bit:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentbitds
namespace: fluentbit-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: fluentbit
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
- nodes
- nodes/proxy
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: fluentbit
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluentbit
subjects:
- kind: ServiceAccount
name: fluentbitds
namespace: fluentbit-systemNext, enable hostNetwork so that Fluent Bit pods can query kubelet’s endpoint. Here’s a sample manifest that creates a Fluent Bit DaemonSet.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentbit
namespace: fluentbit-system
labels:
app.kubernetes.io/name: fluentbit
spec:
selector:
matchLabels:
name: fluentbit
template:
metadata:
labels:
name: fluentbit
spec:
serviceAccountName: fluentbitds
containers:
- name: fluent-bit
imagePullPolicy: Always
image: fluent/fluent-bit:latest
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluentbit-config
mountPath: /fluent-bit/etc/
resources:
limits:
memory: 1500Mi
requests:
cpu: 500m
memory: 500Mi
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluentbit-config
configMap:
name: fluentbit-configFinally, set Kubelet_Port to 10250 and Use_Kubelet to true in the Fluent Bit ConfigMap:
...
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
DB /var/log/flb_kube.db
Parser docker
Docker_Mode On
Mem_Buf_Limit 50MB
Skip_Long_Lines On
Refresh_Interval 10
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc.cluster.local:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Merge_Log On
Buffer_Size 0
Use_Kubelet true
Kubelet_Port 10250Verify
When you enable EKS control plane logs, you can use CloudWatch Log Insights to analyze kube-apiserver events. The following query shows requests served by kube-apiserver by querying kube-apiserver-audit logs:
fields userAgent, requestURI, @timestamp, @message, requestURI, verb
| filter @logStream like /kube-apiserver-audit/
| stats count(userAgent) as cnt by userAgent, verb
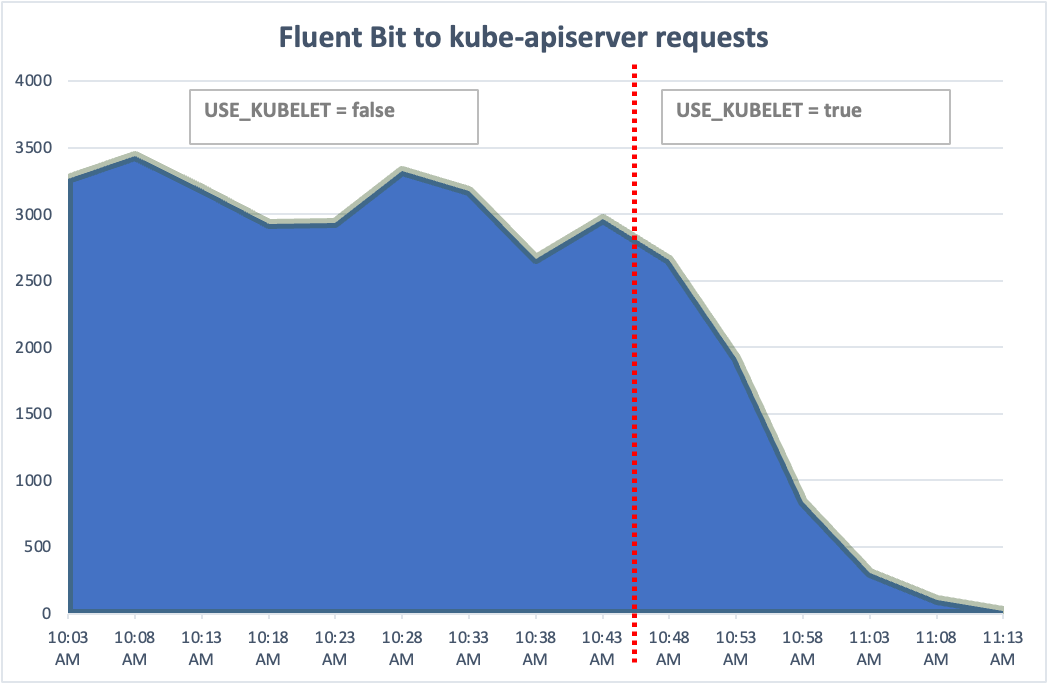
| sort cnt descBefore enabling the Use_Kubelet filter, Fluent Bit made 2500 to 3500 requests every hour in the 30,000 pods cluster we used for testing. After enabling the filter, the number of requests dropped to zero.
Conclusion
Fluent Bit’s Use_Kubelet feature allows it to retrieve pod metadata from the kubelet on the host. Amazon EKS customers can use Fluent Bit to capture logs in clusters that run tens of thousands of pods with this feature enabled without overloading the Kubernetes API server. We recommend enabling the feature even if you aren’t running a large Kubernetes cluster.