Containers
Deep Dive: Amazon ECS Managed Instances provisioning and optimization
Amazon Elastic Container Service (Amazon ECS) Managed Instances is a fully managed compute option that eliminates infrastructure management overhead while providing customers access to a broad suite of Amazon Elastic Compute Cloud (Amazon EC2) capabilities, including the flexibility to select instance types, access reserved capacity, and leverage advanced security and observability configurations. By offloading operations to Amazon Web Service (AWS), ECS Managed Instances helps customers get started quickly, reduces total cost of ownership, and frees your teams to focus on building applications that drive innovation.
This blog post dives into how ECS Managed Instances automatically provisions and optimizes EC2 instances, balancing high availability with cost efficiency for your workloads.
Amazon ECS Managed Instances Capacity Provider
Within Amazon ECS, capacity providers (CPs) are the interface through which you define compute capacity for your workloads. Your ECS clusters automatically include AWS managed FARGATE and FARGATE_SPOT CPs for launching workloads on serverless compute, and you can create your own EC2 Auto Scaling group (ASG) CPs to run your workloads on EC2 instances. Amazon ECS Managed Instances is a new CP that combines the fully managed experience of AWS Fargate with the flexibility of Amazon EC2—delivering the best of both worlds. ECS rapidly provisions and scales fully managed EC2 instances in your AWS account in response to workload requirements. ECS Managed Instances CP automatically selects the most cost-optimized general-purpose instances. Customize your instance requirements by specifying attributes such as minimum/maximum vCPU and memory, desired instance types, CPU manufacturers, accelerator types, and additional instance specifications. To learn more about instance selection, see documentation.
Provisioning workflow
ECS Managed Instances continuously monitors your workloads and launches new EC2 instances just-in-time based on workload requirements. It enhances application availability by automatically distributing tasks across Availability Zones (AZs) within your configured subnets. When launching new instances, ECS first ensures proper AZ distribution before bin-packing tasks within each instance to optimize costs, achieving a balance between high availability and cost efficiency. Additionally, by placing multiple tasks on the same instance, ECS Managed instances not only optimizes infrastructure cost but also enables faster task launches, because subsequent tasks avoid instance provisioning latency and benefit from on-instance container image caching. We first cover the instance provisioning workflow before diving into the availability and infrastructure optimization aspects in more detail.
The following diagram illustrates the instance provisioning workflow. When four new tasks are launched through a Managed Instances CP, ECS first evaluates existing managed instances to determine available capacity. ECS places as many tasks as possible on currently running instances based on task sizes and available instance resources – in this case, two tasks are successfully placed on existing EC2 instances that already hosts other tasks. For the remaining two tasks that cannot be accommodated on existing instances, ECS automatically launches a new EC2 instance. This new instance is provisioned based on task resource requirements, ensuring sufficient CPU and memory for remaining tasks, and is placed in an AZ that balances task distribution across AZs. This bin-packing approach maximizes resource utilization and minimizes infrastructure costs by efficiently co-locating tasks while spreading them across multiple AZs for high availability.
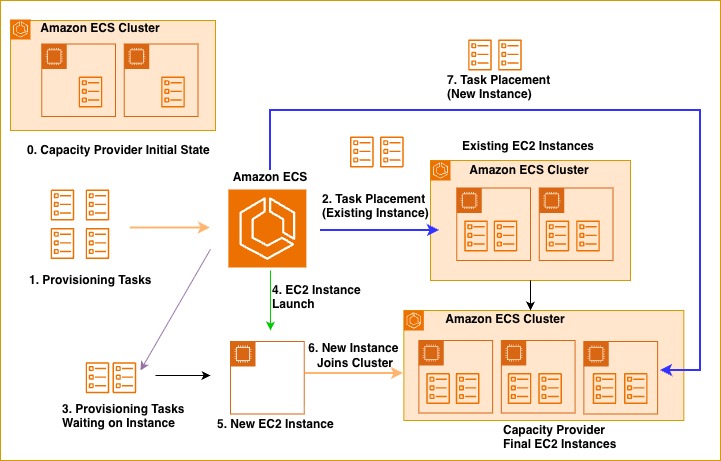
Figure 1: Run Task flow for incoming new ECS tasks in ECS Managed Instances Capacity Provider
Existing Instance Selection
ECS maintains precise resource accounting for every instance, tracking available CPU, memory, and other resources in real-time. When instances register with ECS, their available capacity equals the total EC2 instance resources minus memory reserved for the ECS Agent. ECS determines agent overhead during instance registration using heuristics based on instance type, ensuring sufficient resources are reserved for multiple concurrent tasks. As tasks launch and terminate, ECS dynamically updates the instance’s available resource capacity. For new task placement, ECS first checks if existing instances have sufficient resources. When multiple suitable instances exist, ECS prioritizes spreading tasks across AZs for maximum resilience, with AZ distribution controlled by the subnets configured on the MI CP. If optimal AZ spread isn’t possible within existing instances but capacity exists in the current AZ, ECS first prioritizes using existing capacity to reach service desired task count faster without provisioning additional instances, ensuring higher availability. ECS later rebalances workloads through continuous AZ service rebalancing to achieve optimal AZ distribution thereby further increasing the availability.
New Instance Registration
When ECS Managed Instances cannot place a new task on existing instances, the task enters a PROVISIONING state while waiting for new capacity. Rather than provisioning instances individually, ECS intelligently batches incoming tasks from multiple applications—balancing responsiveness with optimization opportunities. This allows ECS to analyze resource requirements holistically and select optimal instance types while spreading tasks across AZs. Placing tasks with varying CPU, memory, and storage requirements onto hundreds of available instance types represents an NP-complete multi-dimensional bin packing problem. ECS employs a First Fit Decreasing (FFD) algorithm that delivers near-optimal results in polynomial time, prioritizing system responsiveness over mathematical perfection while maintaining efficient resource utilization.
Infrastructure Optimizations
ECS Managed Instances launches right-sized EC2 instances based on your CP configuration and workload requirements. Over time, your EC2 instances may drift from workload requirements due to changing traffic patterns or dynamic scaling. ECS Managed Instances continuously optimizes infrastructure by draining underutilized instances and relocating tasks to more efficient capacity—either existing instances with available resources or newly provisioned right-sized instances. The following illustration shows optimization of underutilized instances in action: when two tasks stop, ECS recognizes the resource inefficiency and marks one underutilized instance as DRAINING. This reduces infrastructure from three instances to two, maintaining service availability while eliminating unnecessary compute costs.
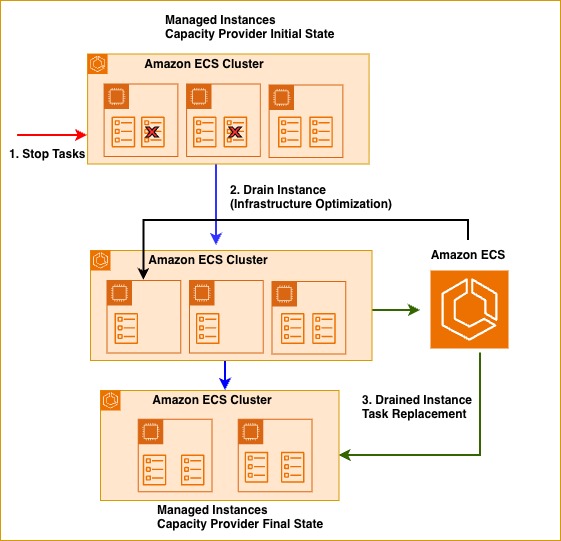
Figure 2: ECS MI capacity provider draining underutilized instances to improve resource utilization
ECS Managed Instances also automatically removes idle instances with no running tasks, ensuring you only pay for active resources. The following illustration shows when two tasks stop on an instance, ECS identifies the now-idle instances and deregisters, triggering instance termination and scaling down to single instance from two instances. The same mechanism handles previously drained instances—once they become empty after task migration, they’re automatically deregistered and terminated.
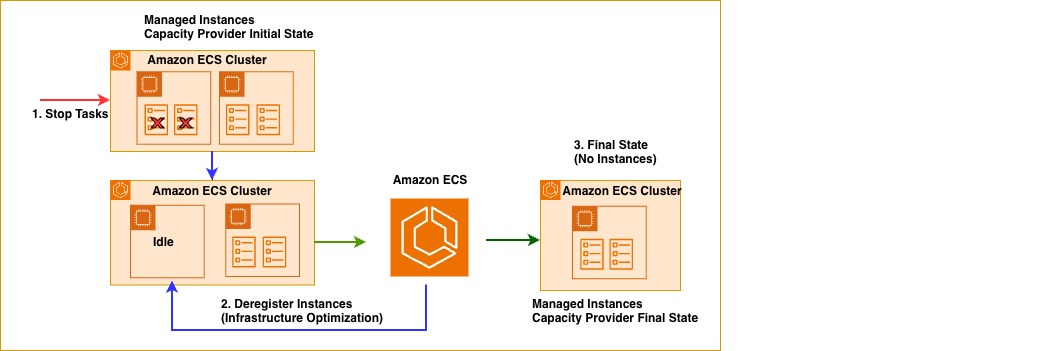
Figure 3: ECS MI capacity provider draining idle instances to improve resource utilization
Availability
ECS Managed Instances improves application availability by automatically spreading tasks of your ECS service across AZs for your configured subnets. When launching new instances, ECS first distributes your instances across all configured AZs and places tasks on them to maximize availability. Through multiple scaling operations, if an ECS service reaches a state where tasks aren’t perfectly AZ-balanced, the automatic AZ-rebalancing feature helps redistribute tasks across instances – sometimes requiring scaling in and out of instances. The ultimate benefit is that ECS ensures your service tasks are primarily AZ-balanced, then efficiently bin-packed on your instances, delivering an optimal balance of availability and cost optimization.
Demo Walk Through
In this walkthrough, we’ll create a practical demonstration of ECS Managed Instances by deploying an Amazon ECS cluster configured with a Managed Instances CP. Our setup features two distinct ECS services, each with different CPU and memory requirements. To provision ECS resources, we also provision certain Amazon Virtual Private Cloud (Amazon VPC) , IAM and EC2 resources. We will use AWS CLI and provision the initial set of resources via AWS CloudFormation. We will then use AWS CLI commands on ECS APIs to update the number of ECS tasks in the service and observe how ECS manages the EC2 instances under the hood. This whole demo will take around 40 minutes to complete.
Prerequisites
- User with CloudFormation, ECS and EC2 permissions.
- AWS CLI
Steps
- Download the CloudFormation templates from this GitHub repository
- vpc-stack.json, ecs-stack.json and nested-stack-coordinator.json. - Create a S3 bucket to put the CloudFormation templates and push the templates to the S3 bucket
- Push the CloudFormation templates to the above S3 bucket
- Create a CloudFormation stack with
nested-stack-coordinator.jsontemplate. This will create 3 CloudFormation Stacks in your account – Coodinator Stack, VPC Stack and ECS stack. The coordinator stack creates the VPC and ECS stacks. The VPC stack contains VPC resources and ECS contains ECS resources. - Here are the resources created via CloudFormation
- 1 ECS cluster with a Managed Instance Capacity Provider
- 2 ECS Services:
- ManagedInstancesService1: 1 vCPU, 5.5GB memory per task
- ManagedInstancesService2: 1 vCPU, 9.5GB memory per task
- 4 total tasks (2 per service) distributed across AZs
- 2 Managed EC2 instances in the Managed Instances Capacity Provider
Cluster and Services:
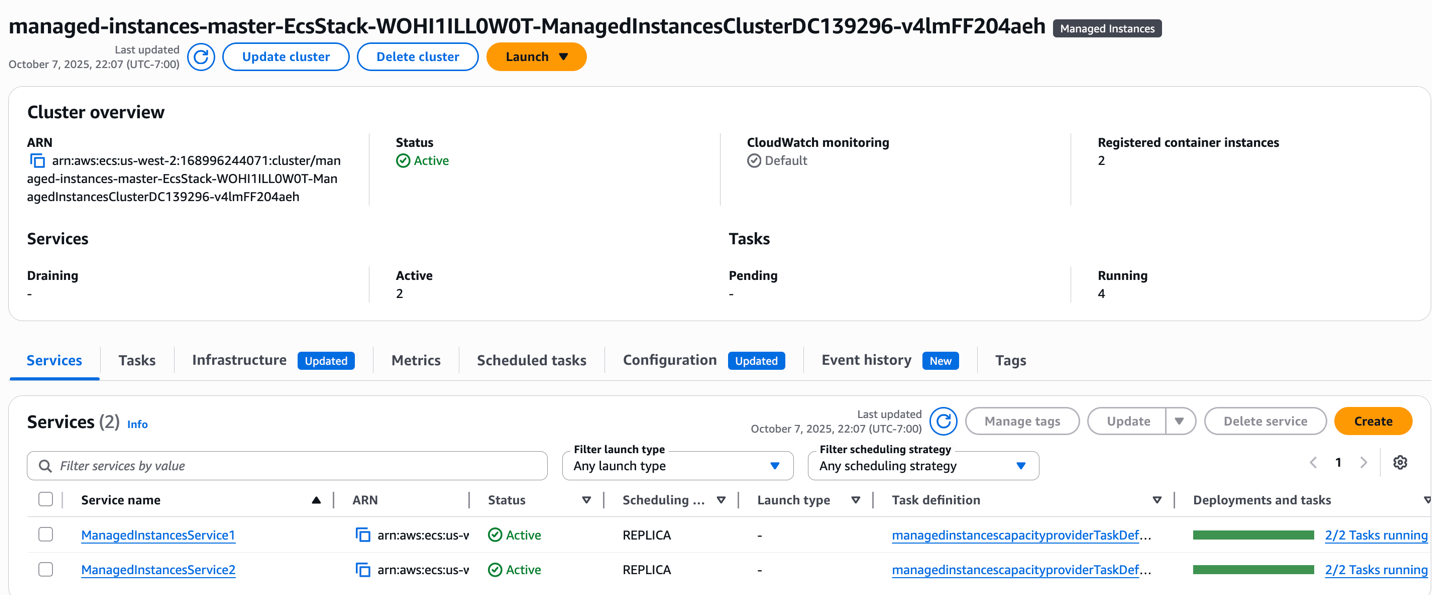
Figure 4: A single cluster with 2 ECS services running with 2 tasks per service
Service Tasks
Our application runs four service tasks distributed across two AZs (us-west-2a and us-west-2b) for high availability. If one zone experiences issues, the application continues running from the other zone, eliminating single points of failure and ensuring consistent service availability.
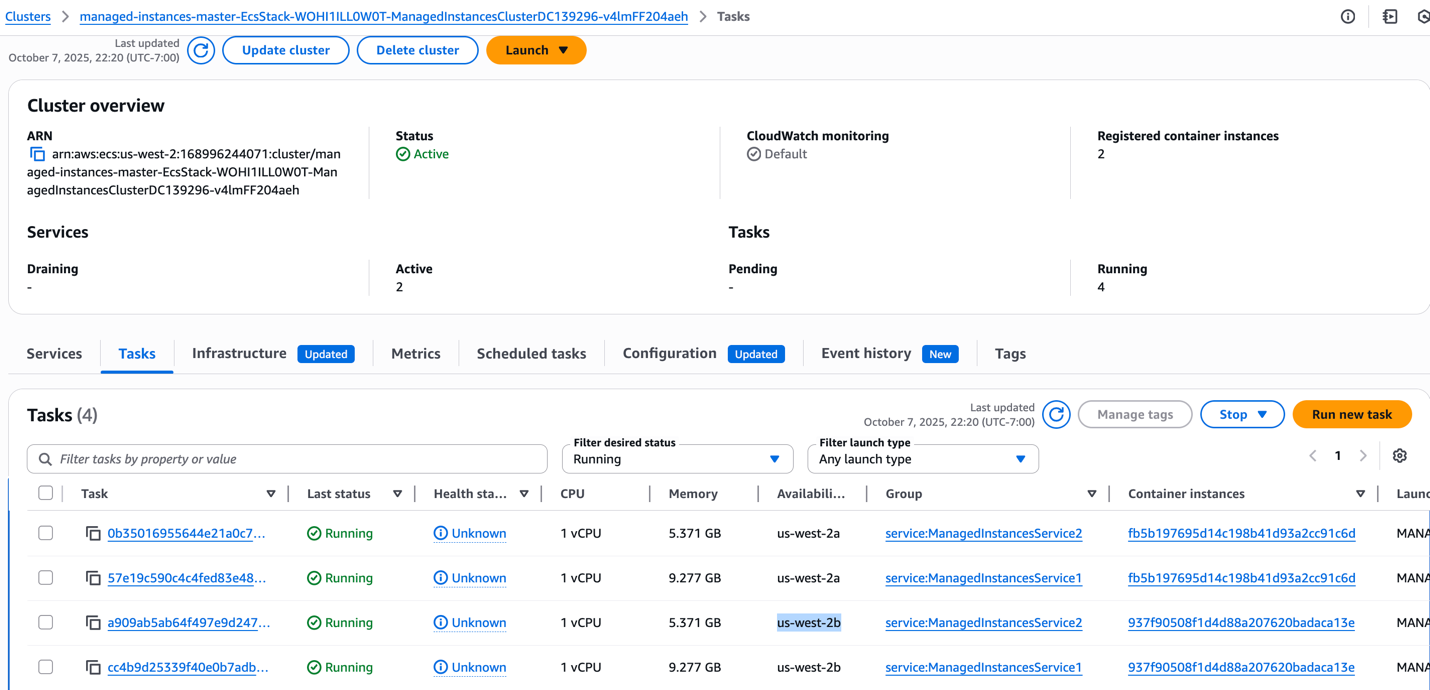
Figure 5: 4 service tasks for 2 ECS services with different task resource configurations per service
Amazon ECS Managed Instances CP
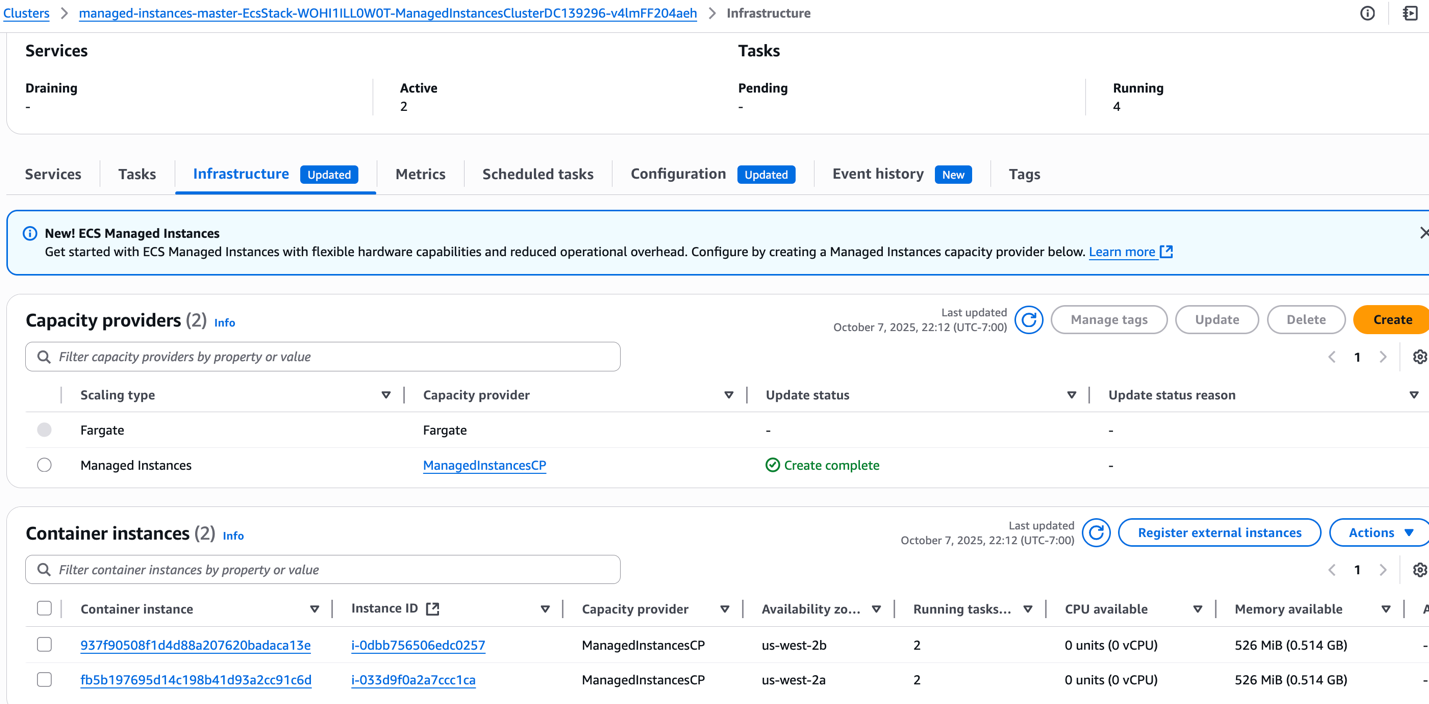
Figure 6: Managed Instance capacity provider running with 2 instances across 2 AZs with optimal resource utilization
The Managed Instances CP analyzed exact resource requirements: 15GB total memory (9.5GB + 5.5GB) and 2 vCPUs per instance. ECS provisioned an optimal r5a.large instances (2 vCPUs, 16GB memory) in two AZs, ensuring high availability while maximizing resource efficiency. Each instance now runs both service tasks with efficient utilization—15GB of 16GB memory used and both vCPUs actively used. The result is intelligent capacity management that eliminates manual guesswork, reduces costs through efficient resource allocation, and maintains the performance our applications need.
- Next, we’ll demonstrate ECS Managed Instances intelligent resource management by setting the desired count to 0 for ManagedInstancesService1. This action stops 2 tasks (9.5GB memory, 1 vCPU each) currently running across our 2 r5a.large instances. With ManagedInstancesService1 tasks removed, each instance now runs only the remaining ManagedInstancesService2 tasks (5.5GB memory, 1 vCPU each). This creates a resource utilization scenario where our r5a.large instances (16GB, 2 vCPUs) are running single 5.5GB task, leaving unused capacity.
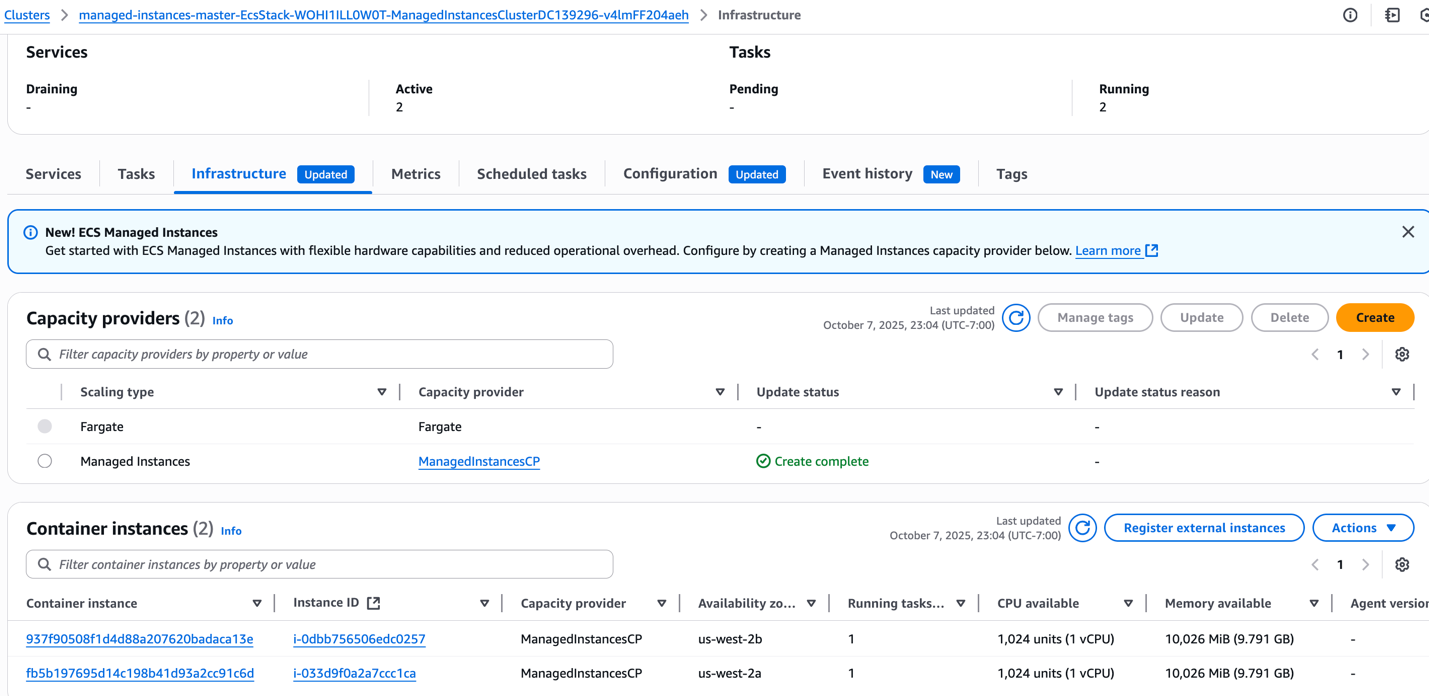
Figure 7: Managed Instance capacity provider instances become underutilized after stopping tasks of a service
- ECS Managed Instances CP quickly detects this resource inefficiency and takes action by draining one of the underutilized instances. While both instances are now suboptimal for the current workload, the system doesn’t drain them simultaneously as it would risk service availability. Instead, ECS follows an availability-first approach, draining instances incrementally. By maintaining sufficient active capacity during the optimization process, it ensures there’s always capacity available for new task placement or unexpected scaling events.
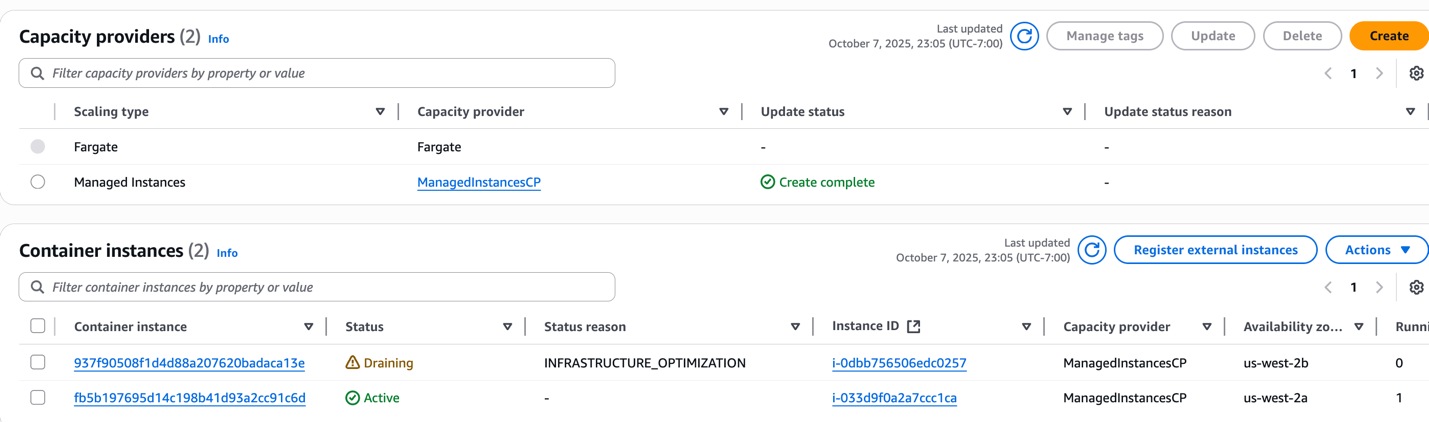
Figure 8: Managed Instance capacity provider draining underutilized instances
- Once draining completes, the displaced task moves to the remaining instance in us-west-2a, which has sufficient available resources. ECS Managed Instances prioritizes existing capacity over new provisioning for faster service stabilization. Both ManagedInstancesService2 tasks now run on a single instance, maximizing resource utilization while leaving the drained instance empty. ECS automatically deregisters and terminates the empty instance, reducing our infrastructure from two instances to one. This demonstrates continuous right-sizing based on actual demand. ECS addresses AZ distribution in later optimization steps, balancing efficiency with high availability.
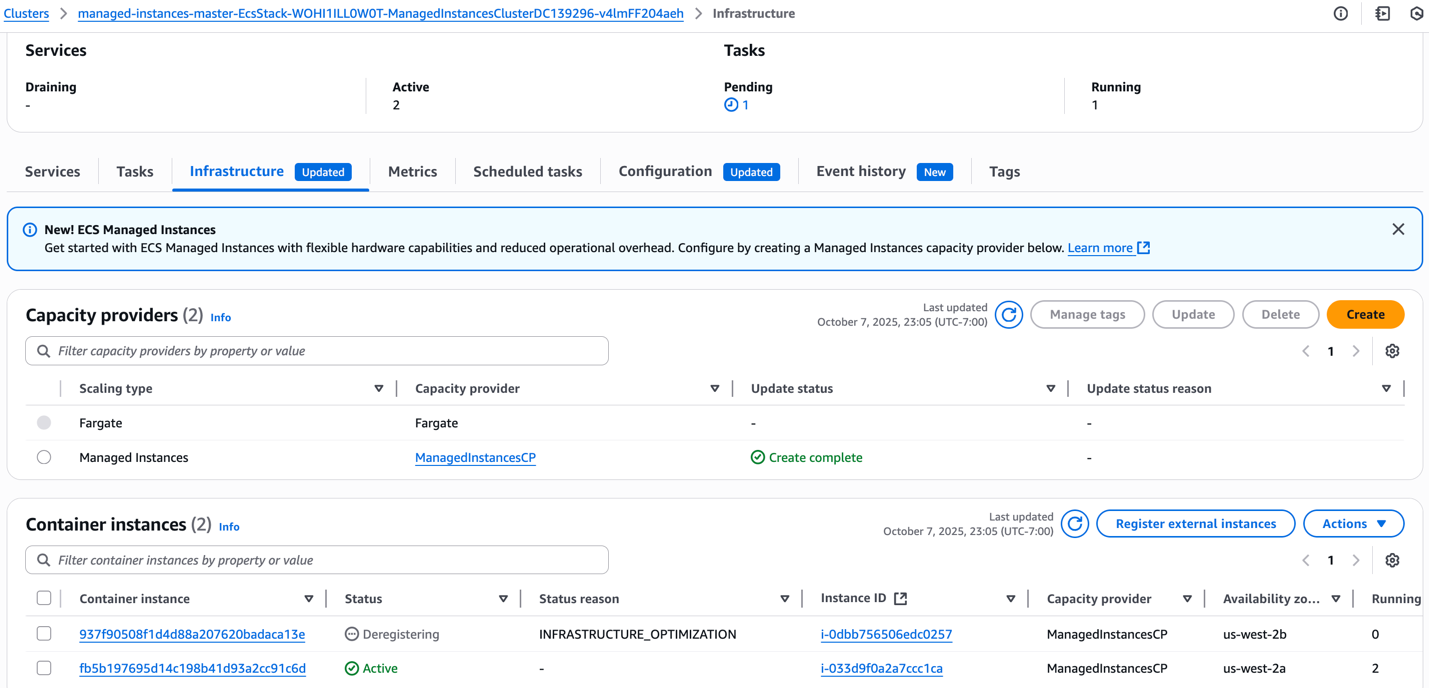
Figure 9: Managed Instance capacity provider deregistering idle instances with no tasks
- After the cluster stabilizes, ECS automatically rebalances workloads across AZs by starting a replacement task in a new AZ while stopping the existing one. This provisions a right-sized r7a.medium instance (1 vCPU, 8GB) in the second AZ for the 5.5GB task, while making the original r5a.large instance suboptimal for running just one task. ECS Managed Instances CP detects this inefficiency and drains the underutilized instance, demonstrating continuous optimization that balances cost efficiency with high availability across AZs.
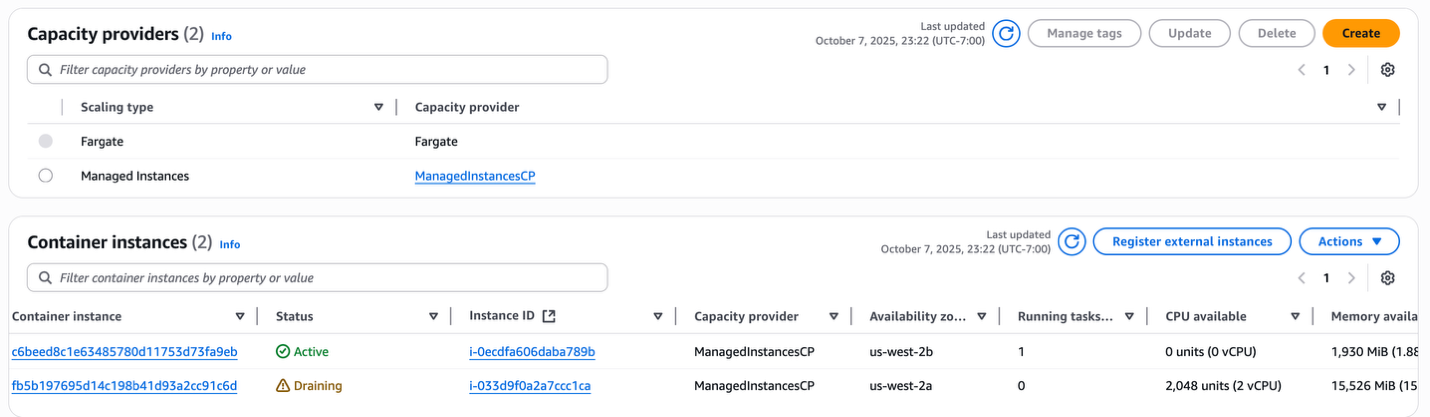
Figure 10: Managed Instance capacity provider AZ rebalancing and continuous optimizations
- Finally, the Managed Instance CP gets to an optimal state of running 2 r7a.medium instances (1 vCPU, 8GB) with 1 task each (1 vcpu, 5.5 GB) spread out across 2 AZs.
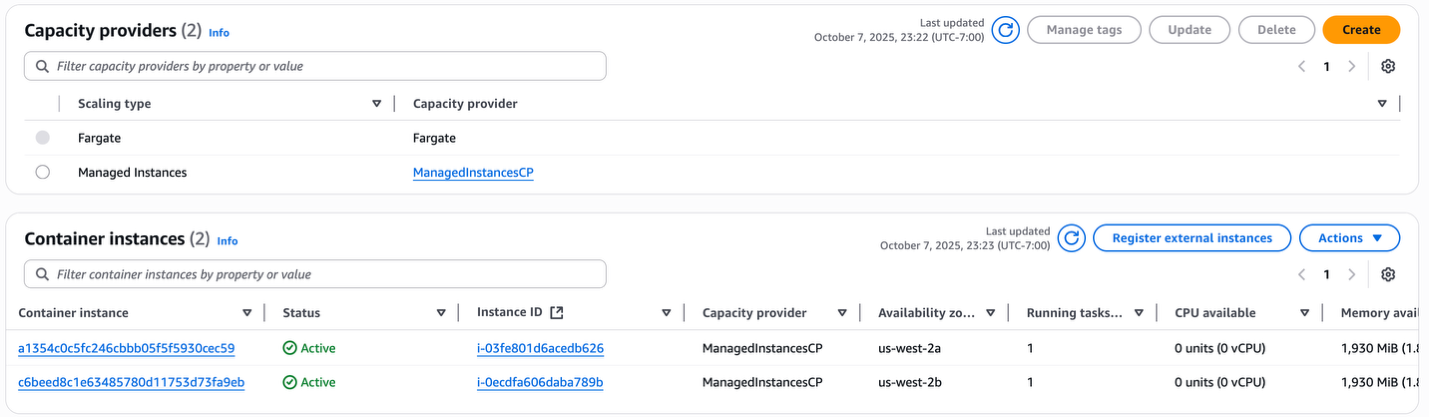
Figure 11: Managed Instance capacity provider running with optimal capacity after infrastructure optimizations
Long Running Workloads
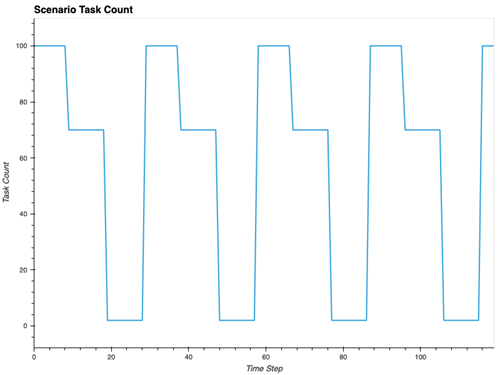
Figure 12: Long Running test with predictable scaling of tasks
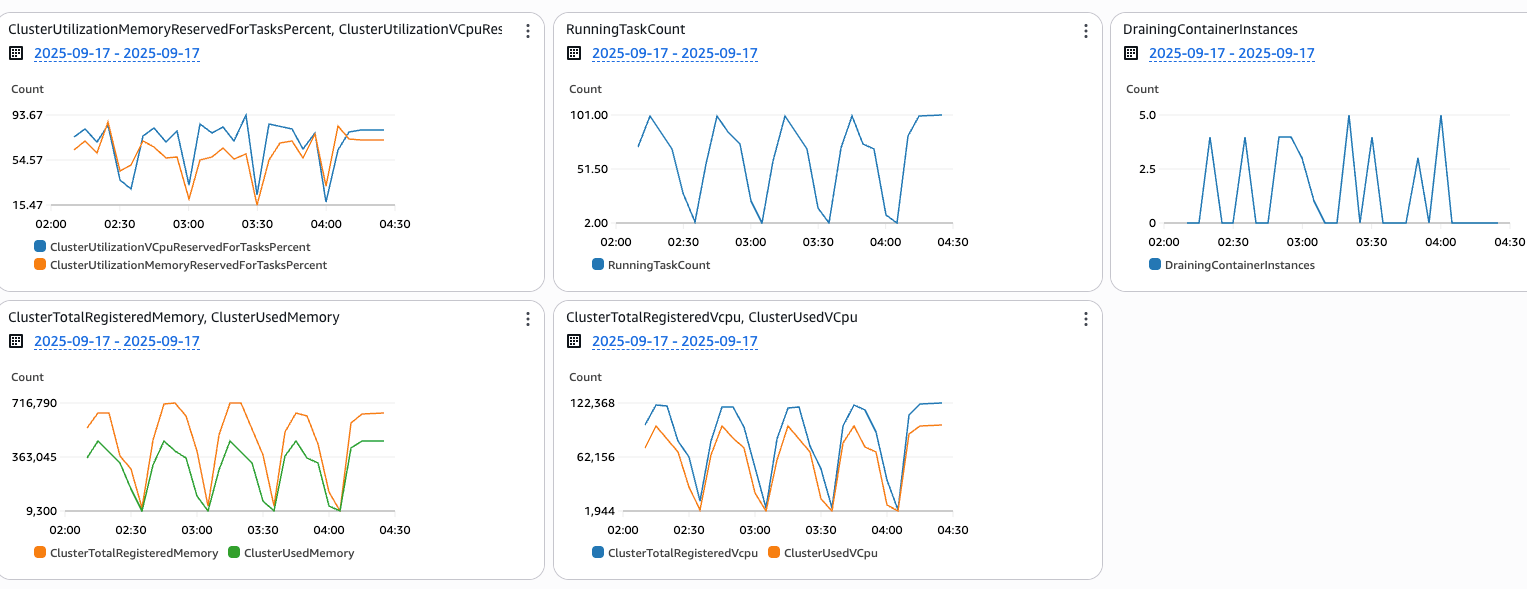
Figure 13: Capacity Provider Metrics for cyclical scaling pattern
ECS Managed Instances CP matches resources to actual demand. In another testing scenario (Figure 12), two ECS services cycle through workload changes—scaling from 100 total tasks to 70, then to just 2 tasks every 30 minutes over 2 hours. Data capture at 1-minute intervals provides detailed visibility into the CP’s response to these workload changes.
The key insight is that ECS Managed Instances maintains strong alignment between resource allocation and actual demand, with both vCPU and memory utilization metrics mirroring the cyclical task patterns exactly. The DrainingContainerInstances metric reveals the continuous background optimization at work. Rather than waiting for manual intervention, ECS Managed Instances continuously monitors resource efficiency across the cluster, and when tasks scale down, it immediately begins draining underutilized instances while gracefully moving remaining workloads to optimize cluster density. This automated process ensures no resources remain idle longer than necessary.
Cleaning up
After completing this walkthrough, you must clean up all deployed resources to prevent ongoing charges and maintain a tidy AWS environment. This step prevents unexpected charges and keeps your AWS environment tidy by eliminating unused resources.
- Delete CloudFormation stack
- Delete CloudFormation templates and S3 bucket
Conclusion
In this post, we explored the infrastructure provisioning and optimization workflows of Amazon ECS Managed Instances. While the initial release implements AWS operational best practices to balance high availability with cost efficiency, we understand that different workloads require distinct trade-offs among the cost, performance, and availability dimensions. Looking ahead, we plan to further enhance the provisioning and optimization workflows, while introducing customer controls, for example, configurable periods for optimization workflows, capacity headroom or target utilization levels, custom placement strategies, and disruption budgets.
For future updates, please refer to the ECS roadmap on Github. As always, we welcome your feedback to help shape the future of Amazon ECS. To get started, please refer to our documentation.
About the authors
 Abhishek Nautiyal is a Sr. Product Manager Technical who works on all aspects of compute infrastructure and container orchestration for Amazon ECS and AWS Fargate.
Abhishek Nautiyal is a Sr. Product Manager Technical who works on all aspects of compute infrastructure and container orchestration for Amazon ECS and AWS Fargate.
 Amit Gupta is a Principal Software Engineer at Amazon ECS. His current focus is ECS control plane focusing on availability, resiliency and compute infrastructure management for ECS applications.
Amit Gupta is a Principal Software Engineer at Amazon ECS. His current focus is ECS control plane focusing on availability, resiliency and compute infrastructure management for ECS applications.