Containers
Enhance Kubernetes high availability with Amazon Application Recovery Controller and Karpenter integration
Kubernetes provides a robust set of features designed to improve an application’s resiliency. Anti-affinity rules and pod topology spread constraints help distribute replicas across different Availability Zones (fault domains) and worker nodes, so the failure of either doesn’t compromise an application’s overall availability. Liveness and readiness probes detect when applications become unhealthy, triggering pod restarts or deregistering unhealthy pods from endpoint slices so they no longer receive traffic. Additional features like pod disruption budgets (PDBs) make sure a minimum amount of capacity is available during deployments and rollouts, and pre-stop hooks and termination grace periods enable graceful application shutdowns. However, despite these capabilities, there are instances where Kubernetes’s built-in resilience features aren’t enough. Consider gray failures where API latency is steadily increasing, or when there are intermittent errors in specific Availability Zones. In these cases, the traditional approach of diagnosing and troubleshooting issues can be time-consuming and might not provide the immediate relief that mission-critical, tier 1 applications require.
In this post, we explain the benefits of using Amazon Application Recovery Controller (ARC) for improving application resiliency and why we built a built a Kubernetes controller to integrate Karpenter with ARC’s zonal shift.
Business impact of zone-level issues
For organizations running tier 1 applications, even minor degradations in service quality can have significant business impacts. Customer experience can degrade when applications experience increased latency or intermittent failures, potentially leading to revenue loss or reputational damage. Rather than spend valuable time diagnosing complex infrastructure issues, many organizations running mission-critical applications on Kubernetes might prefer to shift traffic away from problematic zones to maintain and restore service availability.
Benefits of Amazon Application Recovery Controller
ARC was specifically designed to address these transient zonal issues. ARC monitors for specific signals that indicate when an Availability Zone’s health is degrading and responds by quickly shifting traffic away from the affected zone. This approach minimizes the impact to end-users while giving operations teams additional time to investigate and resolve underlying issues.
ARC integrates seamlessly with several AWS services, including AWS load balancers, Auto Scaling groups, and Amazon Elastic Kubernetes Service (Amazon EKS). During a zonal autoshift, ARC performs several actions. First, it cordons worker nodes in the affected Availability Zone, preventing the Kubernetes scheduler from scheduling new pods on those nodes. Second, it identifies all pods running on instances in the impaired Availability Zone and removes their endpoints from their corresponding EndpointSlices. If the pod’s IP addresses are registered with an AWS load balancer, they are also deregistered. This causes traffic to be redirected to pods running in healthy Availability Zones. Finally, ARC temporarily reconfigures automatic scaling groups and managed node groups to avoid provisioning new capacity in the impaired zone. Together, these measures effectively prevent a service disruption by diverting traffic away from the replicas in the degraded Availability Zone.
Karpenter integration gap
Over the past few years, many organizations have adopted Karpenter for automatically scaling their EKS clusters due to its flexibility and speed as compared to the Kubernetes cluster autoscaler. Whereas the cluster autoscaler requires predefined node groups with specific instance types and capabilities, Karpenter dynamically provisions capacity based on the actual requirements of pending pods. This approach provides better resource utilization and faster scaling.However, a gap exists in ARC’s current service integrations. When ARC detects issues in an Availability Zone and initiates a zonal shift, it doesn’t communicate this information to Karpenter. Additionally, Karpenter doesn’t have a mechanism to automatically reconfigure node pools or cordon nodes in the impaired zone. Consequently, Karpenter might attempt to provision capacity across all zones in a node pool’s configuration, including the impaired zone, as long as it meets pod scheduling and resource requirements. This behavior can lead to delays in provisioning capacity when it’s most needed and result in pods being scheduled on infrastructure in the impaired zone.
Bridging ARC and Karpenter
To address this integration gap, we’ve developed a Kubernetes controller that listens for events generated when AWS triggers a zonal autoshift or when a manual zonal shift is initiated. Each event includes the ID of the impaired zone, which our controller uses to dynamically reconfigure Karpenter node pools to avoid the affected zone.
When the controller is notified of a zonal shift or autoshift, it examines each node pool’s configuration. If a node pool explicitly includes the impaired zone in its topology.kubernetes.io/zone requirement, the controller stores the zone ID in the node pool’s annotations using the key zonal-autoshift.eks.amazonaws.com/away-zones and removes it from the topology requirement. Temporarily storing the impaired zone as an annotation allows the controller to quickly restore the node pool’s original settings, and removing the impaired Availability Zone from the topology.kubernetes.io key prevents new capacity from being provisioned in the affected zone.
For node pools that don’t specify zone requirements, the controller introspects the environment to identify the cluster’s available zones. It does this by examining the cluster’s subnet tags. After the cluster’s available zones have been identified, it adds them, except the impaired zone, to the node pool’s topology.kubernetes.io/zone requirement.
The following code is an example of how a node pool appears after our controller processes a zonal shift for us-west-2c:
Solution overview
The system architecture for our controller consists of three major components:
- An Amazon EventBridge rule that watches for events related to zonal autoshift events, such as
Autoshift In ProgressorAutoshift Completed. - An Amazon Simple Queue Service (Amazon SQS) queue for temporarily storing autoshift events and messages.
- A controller that periodically polls the queue for messages and reconfigures Karpenter node pools. We always run at least two replicas of the controller pod in different Availability Zones in the event there is an issue in one of the cluster’s Availability Zones.
The following diagram illustrates the solution architecture.
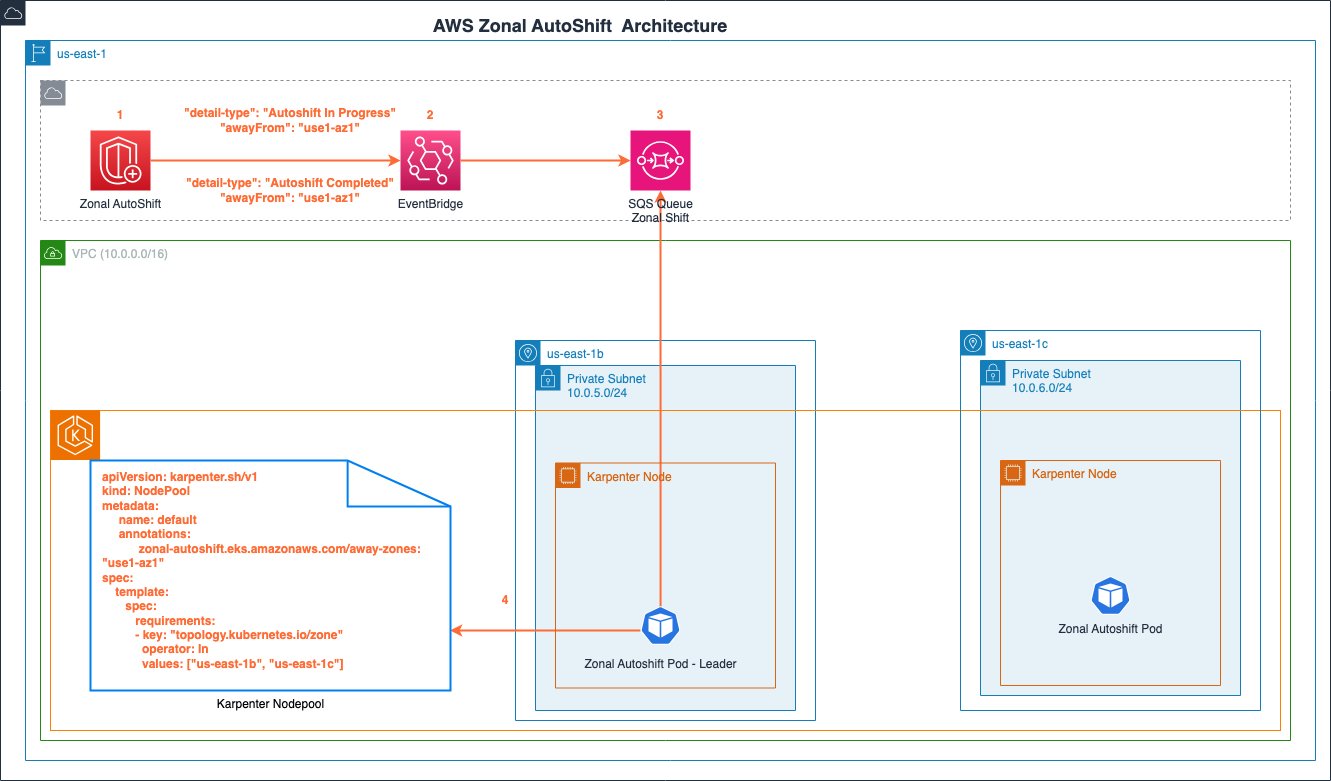
Key behavioral differences
It’s important to understand how our solution differs from ARC’s behavior with managed node groups. ARC integrates with managed node groups by cordoning nodes in the impaired zone and shifting traffic away from them. This allows existing pods to continue running, but reduces your application’s carrying capacity (the amount of traffic it can handle). It can also delay reaction by the Horizontal Pod Autoscaler (HPA). For example, if HPA scales an application to run 10 replicas but 5 are running in the impaired zone and no longer receive traffic, the autoscaler might not react immediately. The upside of this approach is that you don’t lose the compute capacity that has already been provisioned. When service to the impaired zone is restored, the workers are uncordoned and traffic begins flowing to those pods once again.The default setting in the controller automatically removes the impaired zone from their respective node pools. This causes nodes in the impaired zone to be terminated and forces pods running on those nodes to be rescheduled onto nodes in other Availability Zones. This behavior makes sure running replicas are actively serving traffic while providing clearer signals to automatic scaling mechanisms like HPA.
For this approach to work properly, you must be careful when configuring your pod’s scheduling requirements. Your deployments must have flexible enough constraints to allow pods to be scheduled across different zones. For example, if you use topologySpreadConstraints, you need to set the maxSkew policy to ScheduleAnyway. Overly restrictive anti-affinity rules or topology constraints will invariably prevent pods from being rescheduled during a zonal shift or autoshift.
If you prefer, you can configure the controller to mimic the behavior of managed node groups by adding the --enable-do-not-disrupt flag to the controllers arguments.
Recovery and restoration
When the zonal impairment resolves, ARC sends a completion event indicating that the zonal autoshift has ended. Upon receiving this message, the controller automatically reverts all changes made to node pool configurations, restoring the original zone distribution and removing the stored annotations. This automated recovery process makes sure clusters return to their normal operating state without manual intervention.
Running experiments with AWS Fault Injection Service
When designing a system for high availability, it’s critical to periodically test its ability to withstand different types of failures. A good way to do this is by injecting faults into the environment and observing how the system responds. If failures occur during these experiments, you can use the lessons you learn from them to incrementally improve the system’s resilience, for example by implementing backoffs and retries, circuit breaking, or distributing replicas across different Availability Zones. Testing will also help you meet your Recovery Time Objective (RTO) and Recovery Point Objective (RPO) commitments, validate your processes and procedures, and prepare your teams to respond quickly and appropriately during a service interrupting event. This idea of injecting faults and using the learnings from experiments to improve system resilience is often referred to as chaos engineering and is an essential element of mission-critical systems design.
In April 2025, AWS Fault Injection Service (AWS FIS), a chaos engineering service, introduced a new recovery action that can be used to trigger a zonal autoshift. This allows those who have enabled zonal autoshift on their EKS clusters to simulate an outage in an Availability Zone, for example using the AWS FIS AZ Availability: Power Interruption scenario, and induce an autoshift. During the autoshift, you can observe how your applications respond as node pools are reconfigured and traffic is shifted away from the impaired zone. It should also reveal if you have dependencies on resources in the impaired zone. For additional information about the integration between AWS FIS and zonal autoshift, see New AWS Fault Injection Service recovery action for zonal autoshift.
If you decide to use this controller, we encourage you to trigger a zonal shift manually or an autoshift as part of an AWS FIS experiment to test the resiliency of your applications and controller’s ability to reconfigure Karpenter node pools during a zonal impairment.
Conclusion
Although Kubernetes provides robust application resilience features, zone-level failures and gray failures require additional coordination between AWS services and Kubernetes controllers. Our zonal autoshift integration for Karpenter bridges this gap, making sure capacity provisioning decisions align with ARC’s traffic management actions. This integration maintains high availability while taking advantage of Karpenter’s efficient, requirement-based capacity provisioning.By combining ARC’s intelligent failure detection with Karpenter’s flexible autoscaling, organizations can achieve more resilient applications without sacrificing operational efficiency or increasing costs.
The controller is an open source reference implementation of a Kubernetes controller and operator that integrates Karpenter with ARC. It is not officially supported by AWS. If you choose to use it, you do so at your own risk. It should be treated as a stop-gap until Karpenter natively integrates with ARC’s zonal shift and autoshift.
We welcome the community’s feedback and ideas for enhancing the controller’s capabilities and encourage you to give it a try if you’re using Karpenter and have thought about enabling ARC zonal shift or autoshift on Amazon EKS.
About the authors
 Jeremy Cowan is a Specialist Solutions Architect for containers at AWS, although his family thinks he sells “cloud space”. Prior to joining AWS, Jeremy worked for several large software vendors, including VMware, Microsoft, and IBM. When he’s not working, you can usually find on a trail in the wilderness, far away from technology.
Jeremy Cowan is a Specialist Solutions Architect for containers at AWS, although his family thinks he sells “cloud space”. Prior to joining AWS, Jeremy worked for several large software vendors, including VMware, Microsoft, and IBM. When he’s not working, you can usually find on a trail in the wilderness, far away from technology.
 Ajay Desai is a Senior Technical Account Manager (TAM) at AWS with over 17 years of experience in the IT industry. He is passionate about containers, cost optimization, and operational excellence, focusing on helping customers design and maintain secure, reliable, efficient, and scalable solutions.
Ajay Desai is a Senior Technical Account Manager (TAM) at AWS with over 17 years of experience in the IT industry. He is passionate about containers, cost optimization, and operational excellence, focusing on helping customers design and maintain secure, reliable, efficient, and scalable solutions.