Containers
Extending GPU Fractionalization and Orchestration to the edge with NVIDIA Run:ai and Amazon EKS
As organizations of all sizes have rapidly embraced the opportunity to pair foundation models (FMs) with AI agents to streamline complex workflows and processes, the demand for artificial intelligence and machine learning capabilities across distributed locations has never been stronger. For example, some organizations need to run custom, in-house language models within a specific geographic boundary to meet data residency requirements, while others require processing data locally to serve latency-sensitive edge inference requests. These distributed processing needs often require running AI/ML workloads in local metro Points of Presence (PoPs), customer premises, and beyond – especially when an AWS Region is not close enough to meet performance or compliance requirements. Managing these distributed workloads introduces another challenge: the need for efficient and topology-aware GPU resource management becomes critical, particularly at the distributed edge, where capacity is often limited and requires optimal allocation.
Building on these emerging needs for distributed AI/ML capabilities and efficient GPU resource management, Amazon Web Services (AWS) and NVIDIA have been working together to explore solutions native to the environments that customers most frequently use for model training and inference, such as Amazon Elastic Kubernetes Service.
In a previous blog post, we showcased how NVIDIA Run:ai addresses key challenges in GPU resource management, including static allocation limitations, resource competition, and inefficient sharing in GPU clusters. The blog post detailed the implementation of NVIDIA Run:ai on Amazon EKS, which featured dynamic GPU fractions, node-level scheduling, and priority-based sharing. Since then, we have released NVIDIA Run:ai in AWS Marketplace, allowing customers to deploy the Run:ai control plane to their Amazon EKS clusters without having to manage the deployment of individual Helm Charts.
Building on this collaboration, today we are extending this flexibility to the entire AWS cloud continuum, enabling you to optimize GPU resources wherever your workloads need to run – in an AWS Region , on-premises , or at the edge. That is why we are excited to announce native Run:ai support for Amazon EKS in AWS Local Zones (including Dedicated Local Zones), Amazon EKS on AWS Outposts, and Amazon EKS Hybrid Nodes. As part of this launch, you can now extend Run:ai environments to support a cluster of GPUs separated by hundreds (if not thousands) of miles across these AWS Hybrid and Edge services. This architectural pattern enables you to create powerful high availability and disaster recovery strategies while maximizing cost efficiency and complying with local data residency requirements.
Extensive and performant global cloud infrastructure
AWS offers a consistent continuum of cloud services from AWS Regions to the farthest edge, providing the ideal foundation for this edge-focused GPU optimization strategy. With Local Zones in 35 metropolitan areas delivering single-digit millisecond latency (including Dedicated Local Zones built specifically for regulatory and digital sovereignty needs), Outposts extending infrastructure and services to on-premises locations for local inference and EKS Hybrid Nodes enabling the use of your existing on-premises and edge infrastructure as nodes in the EKS clusters, organizations can deploy GPU-enabled workloads wherever their business demands. This distributed infrastructure framework enables customers to maintain consistent GPU resource management practices across their entire computing landscape. Whether running real-time inference at the edge for telecommunications applications, processing sensitive healthcare data on-premises, or managing financial services workloads in specific jurisdictions, organizations can utilize the same APIs, management console, and security controls across all deployments. Amazon EKS is a perfect example of this consistent experience in action. As you can see in the AWS Management Console below, you can seamlessly extend Amazon EKS clusters from an AWS Region to AWS Outposts, AWS Local Zones, or EKS Hybrid Nodes – all with consistent APIs and security controls. Through a common container orchestration layer, you can focus on building differentiated application experiences rather than managing the underlying Kubernetes infrastructure itself.
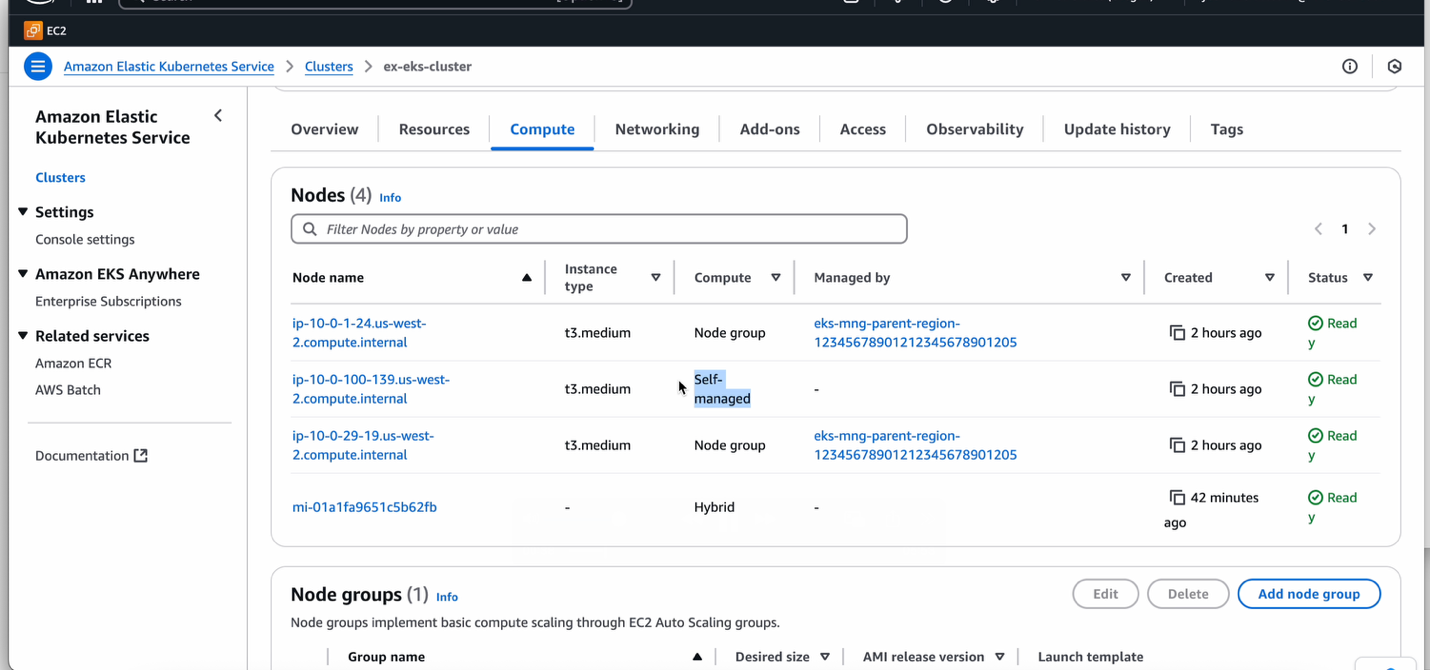
Figure 1: Amazon Elastic Kubernetes Service console with four nodes across an AWS Region, AWS Local Zone and EKS Hybrid Node.
Challenges in bringing AI workloads to the edge
When extending GPU workloads to edge environments, organizations face distinct challenges in training and inference scenarios.
Training
When implementing distributed training, teams need to address several key considerations. First, they must optimize how workloads are distributed in a hybrid architecture, taking into account both network topology and latency patterns. Next, they need to establish secure and efficient connections between their on-premises and GPU clusters in AWS Regions while keeping communication overhead to a minimum. Finally, teams must carefully weigh performance requirements against costs when deploying their GPU compute capacity across distributed environments.
Inference
For inference deployments, organizations must ensure consistent performance across distributed endpoints while maintaining high availability and automatic failover. Teams need to minimize end-to-end response times while efficiently handling multiple concurrent requests across distributed servers. Additionally, they must implement systems that dynamically allocate compute resources based on varying inference loads and model requirements. These challenges are particularly acute in scenarios where real-time processing is crucial, such as in autonomous systems, industrial IoT applications, or healthcare diagnostics at the edge, where even minor latency issues or resource allocation inefficiencies can significantly impact business or mission outcomes.
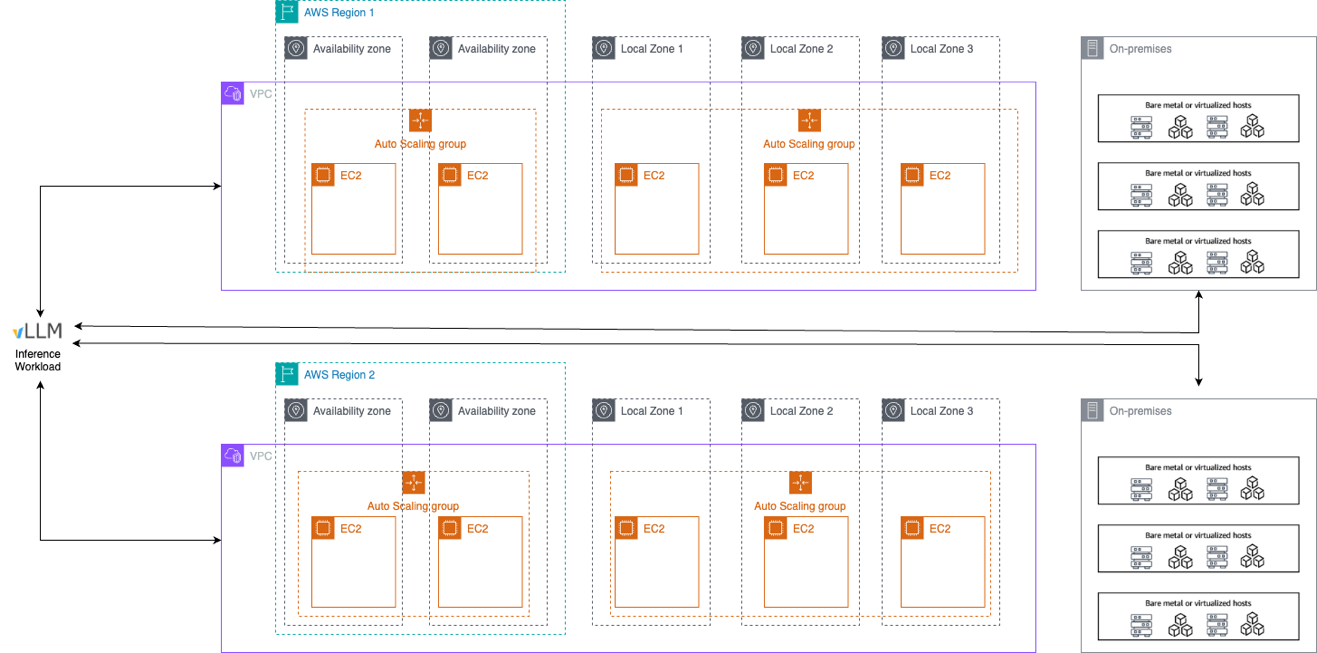
Figure 2: Sample vLLM inference workload with 16 different deployment options: 6 virtualized hosts on-premises, 6 AWS Local Zones and 4 Availability Zones
Run:ai support for AWS Hybrid and Edge services
Through Run:ai’s expanded support for AWS hybrid and edge environments, customers can now bring
comprehensive GPU management capabilities to AWS Local Zones (including Dedicated Local Zones) or on-premises with AWS Outposts or Amazon EKS Hybrid Nodes. These capabilities include broad GPU support across NVIDIA architectures, dynamic GPU fractionalization, and advanced node-level scheduling. Organizations can now leverage the same powerful features that transformed GPU utilization in AWS Regions for their distributed infrastructure, including priority-based sharing, configurable time slices, and guaranteed quota systems, which have proven to improve GPU utilization from 25% to over 75%.
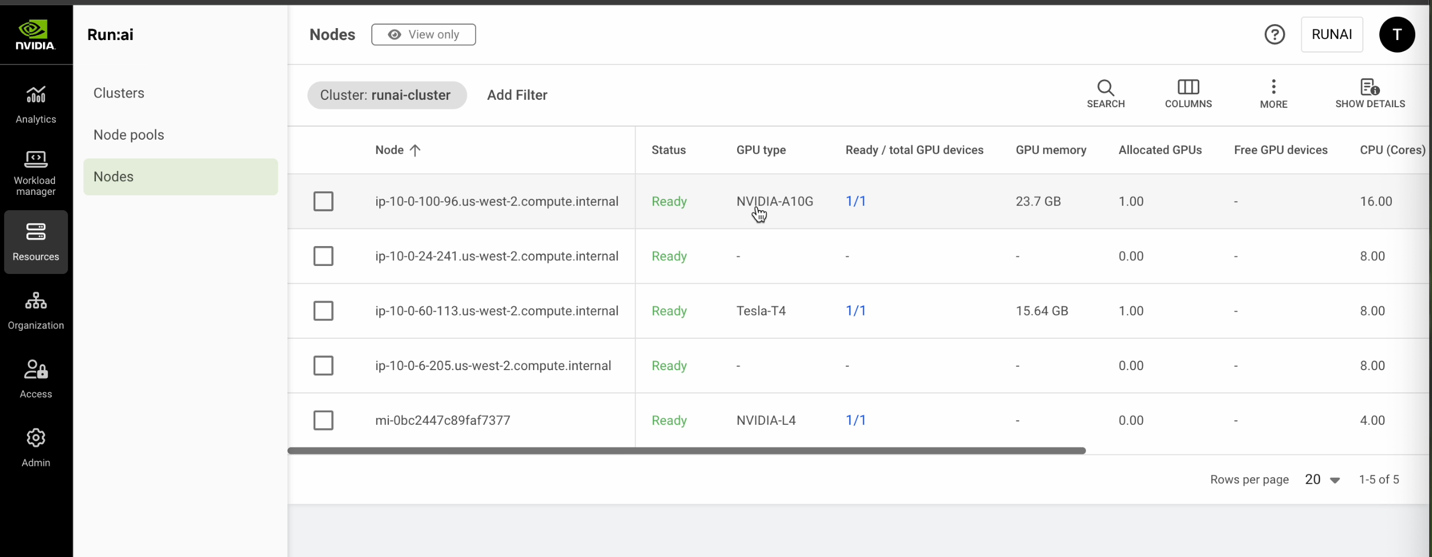
Figure 3: Sample Run:ai console showcasing available nodes within cluster named “runai-cluster”
As an example, you can now deploy an example cluster, runai-cluster, with the following characteristics:
Managed node group: ip-10-0-24-241.us-west-2.compute.internal and ip-10-0-6-205.us-west-2.compute.internal are used to deploy the Run:ai control plane (in the runai-backend namespace). The other critical components include AWS Load Balancer Controller to expose the web console, EBS CSI Driver to allow creation of the PostgreSQL data store, and Knative to support management of inference workloads.
Self-managed node groups: ip-10-0-100-96.us-west-2.compute.internal is a g5.4xlarge instance running in an AWS Local Zone and ip-10-60-113.us-west-2.compute.internal is a g4dn.12xlarge instance running in an Outpost. To view supported GPUs and minimum CPU/memory for Run:ai worker nodes, visit the Run:ai cluster system requirement docs.
Hybrid node: mi-0bc2447c89faf7377 runs on a customer-provided NVIDIA L4 GPU in an on-premises environment connected back to the AWS Region via private connectivity. To simulate this environment in AWS Regions, customers can follow the Amazon EKS Hybrid Nodes workshop module to deploy an equivalent GPU (g6.2xlarge instance) on Amazon EC2 in a peered VPC, for example.
As part of this launch, we will release an automated blueprint to deploy the self-hosted Run:ai control plane to an EKS cluster, with the automated creation of a project and node pool (using the Run:ai node-pool API) for each of the Local Zones, Outpost, and EKS hybrid nodes that you deploy. When deploying Run:ai in your hybrid EKS environment, please note the following:
For Amazon EKS Hybrid Nodes, you must have private connectivity from your on-premises environment to a parent AWS Region, among other core requirements listed in our Amazon EKS user guide. As an example, we recommend that you have reliable network connectivity of at least 100 Mbps and a maximum of 200ms round-trip latency for the connectivity between your hybrid nodes and the EKS control plane.
For AWS Local Zones, you can opt in via the AWS Management Console or the AWS CLI. More information is available in the AWS Local Zones User Guide. Additionally, you can view available GPU-accelerated EC2 instance types on a per-zone basis by running the following:
For Outposts racks, reach out to your AWS account team, visit the AWS Outposts racks product page and user guide, or talk with an Outposts expert to explore your use case. You can also explore sample inference workloads on-premises through one of our latest workshops : Building generative AI applications with on-premises and edge data.
Best practices for Run:ai at the edge
When utilizing Run:ai to manage GPUs across edge environments, several best practices help ensure optimal performance and reliability. The following guidelines help organizations maximize the benefits of Run:ai’s GPU optimization capabilities while maintaining operational efficiency across distributed infrastructure:
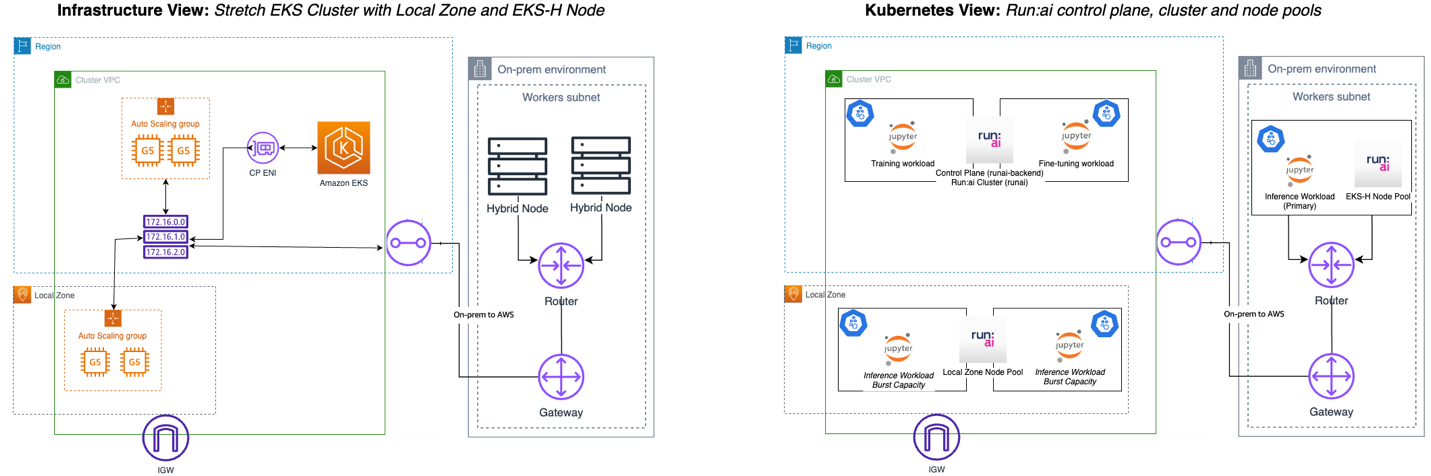
Figure 4: Sample architecture diagram for Run:ai on Amazon EKS hybrid node
- Resource management and scheduling: Create separate node pools for each topology type (AWS Local Zones, Outposts racks, and EKS Hybrid Nodes) to enable granular control over workload placement and resource allocation. This separation enables you to implement topology-specific policies and schedule workloads based on your latency and data residency requirements, while maintaining clear resource boundaries through Run:ai’s quota management system.
- Workload prioritization and GPU sharing: Configure priority-based sharing and time slices appropriate for your edge-specific use cases, such as prioritizing real-time inference workloads over training tasks during peak business hours. Utilize Run:ai’s fractional GPU capabilities with workload-specific memory request and limit values to prevent resource contention and maximize utilization at each edge location.
- Monitoring and governance: Implement comprehensive monitoring through Run:ai’s analytics dashboard to track GPU utilization patterns across all your edge locations, enabling data-driven decisions about resource allocation and scaling. If you have data sovereignty requirements, you can deploy the self-hosted control plane within the edge itself (rather than the parent Region) to maintain strict control over workload placement and data residency.
Conclusion
In this blog post, we demonstrated how Run:ai’s GPU optimization capabilities can be extended across AWS hybrid and edge environments, from Local Zones to Outposts racks and EKS Hybrid Nodes. By implementing Run:ai’s fractional GPU technology on-premises and at the edge, organizations can address critical challenges in distributed training and inference while maintaining consistent governance across their entire infrastructure footprint. The solution’s ability to support dynamic GPU fractions, node-level scheduling, and priority-based sharing proves particularly valuable in edge scenarios where resource optimization and latency requirements are paramount.
To learn more, you can visit the NVIDIA Run:ai product documentation or get hands-on with a sample deployment blueprint available on RunAI Samples.
About the authors
 Robert Belson is a Developer Advocate in the AWS Worldwide Telecom Business Unit, specializing in AWS Edge Computing. He focuses on working with the developer community and large enterprise customers to solve their business challenges using automation, hybrid networking and the edge cloud.
Robert Belson is a Developer Advocate in the AWS Worldwide Telecom Business Unit, specializing in AWS Edge Computing. He focuses on working with the developer community and large enterprise customers to solve their business challenges using automation, hybrid networking and the edge cloud.
 Rob Magno is a solutions architect at NVIDIA with a background in virtualization, networking, Docker and Kubernetes. He enjoys the challenge of architecting complex AI/ML environments that ensure data scientists have the necessary tools and underlying hardware resources to drive business results for enterprises. He has a master’s degree in biomedical engineering and focused his studies on analyzing OCT scans
Rob Magno is a solutions architect at NVIDIA with a background in virtualization, networking, Docker and Kubernetes. He enjoys the challenge of architecting complex AI/ML environments that ensure data scientists have the necessary tools and underlying hardware resources to drive business results for enterprises. He has a master’s degree in biomedical engineering and focused his studies on analyzing OCT scans