Containers
Run Spark-RAPIDS ML workloads with GPUs on Amazon EMR on EKS
Introduction
Apache Spark revolutionized big data processing with its distributed computing capabilities, which enabled efficient data processing at scale. It offers the flexibility to run on traditional Central Processing Unit (CPUs) as well as specialized Graphic Processing Units (GPUs), which provides distinct advantages for various workloads. As the demand for faster and more efficient machine learning (ML) workloads grows, specialized hardware acceleration becomes crucial. This is where NVIDIA GPUs and Compute Unified Device Architecture (CUDA) come into the picture.
To further enhance the capabilities of NVIDIA GPUs within the Spark ecosystem, NVIDIA developed Spark-RAPIDS. Spark-RAPIDS is an extension library that uses RAPIDS libraries built on CUDA, to enable high-performance data processing and ML training on GPUs. By combining the distributed computing framework of Spark with the parallel processing power of GPUs, Spark-RAPIDS significantly improves the speed and efficiency of analytics and ML workloads.
Amazon EMR on EKS Integration
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With Amazon EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast and cost-effectively. Amazon EMR runtime provides up to 5.37 times better performance and 76.8% cost savings, when compared to using open-source Apache Spark on Amazon EKS. Starting from Amazon EMR on EKS 6.9, customers can use the power of the NVIDIA Spark-RAPIDS Accelerator without the need for creating and maintaining custom images. Previously, this process involved engineering efforts, testing, and rebuilding the custom image for every new release, bug fix, or security update. With the new release, Amazon EMR on EKS introduces a pre-built NVIDIA RAPIDS Accelerator for Spark image. Users can now seamlessly utilize the RAPIDS Accelerator on Amazon EKS clusters with GPU-supported instance types (G and P type instances) by specifying the Spark-RAPIDS release label when running Spark jobs using the StartJobRun API , Amazon EMR Spark Operator, and spark-submit. (Note: Instance type for the primary instance group can be either GPU or non-GPU types but the ARM instance types are not supported at this time). This eliminates the hassle of custom images and allows users to benefit from a high-performance, optimized Amazon EMR runtime with the Spark-RAPIDS accelerator.
In this post, we explore the capabilities of the NVIDIA Spark-RAPIDS Accelerator and its impact on the ML workflow using Apache Spark. With Spark-RAPIDS, data scientists and ML engineers can streamline their work by seamlessly integrating Extract, Transform and Load (ETL) and machine learning training into a single Spark script. This eliminates the need for extensive collaboration with data engineers and simplifies the overall ML development process. By using the power of NVIDIA GPUs, Spark-RAPIDS significantly enhances the efficiency and performance of data processing and training tasks.
Amazon EKS deployment architecture
To effectively deploy Amazon EMR on EKS with Spark-RAPIDS, we’ll follow the recommended architecture provided by Data on EKS (DoEKS). This architecture ensures optimal performance and scalability for Spark workloads on Amazon EKS. The first step involves creating a Virtual Private Cloud (VPC) and subnets. For production workloads in situations where large Amazon EKS clusters are deployed, the DoEKS blueprints adds a secondary IP range to avoid IP exhaustion issues. Next, we set up an Amazon EKS cluster with three node groups: the core node group, the Spark driver node group, and the GPU node group. The core node group is responsible for hosting system-critical add-ons like the Cluster Autoscaler, Karpenter, CoreDNS, and also the Spark job-runner. The Spark driver node group hosts the Spark driver pods and they run on Ubuntu EKS AMI with m5.xlarge instances to execute the Spark driver pods. The GPU node group, utilizing g5.2xlarge instances, host and run the Spark executors for data processing and model training. The Spark driver and Spark executors are hosted on separate node groups, as a best practice, because the Spark driver coordinates all the activities in a job and needs to be up throughout the job lifespan. In cases where SPOT instances are utilized, the Spark driver should be hosted on ON_DEMAND instances while the Spark executors can be scheduled on SPOT instances. In this particular use case where we utilize SPOT GPU instances, this approach also helps to reduce the cost of deploying GPU instances. Finally, the NVIDIA GPU Operator, which we’ll describe in greater detail in this post, is deployed to manage the provisioning and utilization of GPUs within the cluster.
Throughout this post, we’ll work with a widely used dataset known as the Fannie Mae Single Loan Performance dataset. This dataset contains a subset of Fannie Mae’s single-family, conventional fixed-rate mortgages with any identity data removed. Full description of the data can be found here. The script used here is based on a notebook example by NVIDIA. We’ll be running ETL to generate two datasets for training and testing. The ETL process creates a delinquency dataframe from performance and joins this dataframe with a cleaned property acquisition dataframe. The final cleaned data is randomly split into a training data set and a testing data set. Using GPUs, we use XGBoost Classifier with the XGBoost4J-Spark library to create a classifier model with the training data. XGBoost (i.e., Extreme Gradient Boosting) and is used for supervised learning with training data with multiple features to create a target variable . The XGBoost4j-Spark library fits XGBoost to the Apache Spark’s MLlib framework that allows us to construct a MLlib pipeline that can preprocess data to fit a XGBoost model, train it, and serve predictions in a distributed computing environment. Each XGBoost worker is wrapped by a Spark task and the training dataset and each XGBoost worker live inside the Spark executors. See the article here for a description.

The resulting model can then use the test dataframe to output a new dataframe that contains the margin, probability, and prediction labels for each feature vector. This example demonstrates the capabilities of Apache Spark, NVIDIA GPUs with CUDA, and the Spark-RAPIDS accelerator in ML data processing and training workflows and showcases how Spark-RAPIDS can significantly enhance the efficiency and performance of ML workloads.
NVIDIA GPU Operator
The NVIDIA GPU Operator is a Kubernetes operator that streamlines the management and provisioning of NVIDIA GPU resources within Amazon EKS clusters. With its automated installation and configuration capabilities, it handles critical components such as NVIDIA drivers, the Kubernetes device plugin for GPUs, and the NVIDIA Container Toolkit. This eliminates the need for manual driver installations and enables users to effortlessly allocate and use GPUs for accelerated computing tasks. Additionally, the GPU Operator also facilitates monitoring of GPU performance and health using Data Center GPU Manager (DCGM), which provides valuable insights into GPU utilization and enables proactive maintenance and optimization.
The following image illustrates the comparison between a manual installation setup and the NVIDIA GPU Operator setup in an Amazon EKS cluster.

NVIDIA RAPIDS Accelerator for Apache Spark
Amazon EMR on EKS provides a Docker image with the NVIDIA RAPIDS Accelerator by specifying the appropriate release label, such as emr-6.10.0-spark-rapids-latest . When using the XGBoost library in our solution, additional libraries need to be added to the Docker image. To achieve this, we included a Dockerfile script that can be used to create a custom Docker image and uploaded to Amazon Elastic Container Registry (Amazon ECR), Dockerhub, or any repository accessible to the Amazon EKS cluster.
Solution overview
The overall solution architecture is illustrated in the following diagram and showcases the various components and their interactions within the Amazon EKS cluster for Spark-RAPIDS deployment. When a Spark job is submitted, the Job-Runner pod is scheduled in the Core nodegroup and it manages the Spark job process. The Spark driver is then scheduled in the Spark driver nodegroup, the Spark driver pod then in turn creates Spark executors pods in the Spark GPU executor nodegroup. Customized Docker images are pulled from Amazon ECR as the driver and executor pods spin up. Based on the job submission configuration and the number and size of the Spark pods scheduled, the Cluster Autoscaler scales out the required Amazon Elastic Compute Cloud (Amazon EC2) nodes. NVIDIA GPU operators and operands are deployed in the same namespace (i.e., gpu-operator in this example) to provide the drivers and plugins required to use GPUs with Spark. However, GPU operands are deployed only in the GPU worker nodes identified by the label feature.node.kubernetes.io/pci-10de.present=true, where 0x10de is the Peripheral Component Interconnect (PCI) vendor ID assigned to NVIDIA.

Deploying the solution
The solution involves the creation and configuration of various AWS resources to create an infrastructure ready for running EMR Spark-RAPIDS ML workloads. We provided a Terraform blueprint that automatically deploys and configures a fully working solution for you. The blueprint does the following:
- A new sample VPC is created, along with two Private Subnets and two Public Subnets.
- An Internet gateway is set up for Public Subnets, and a Network Address Translation (NAT) Gateway is established for Private Subnets.
- An Amazon EKS Cluster with a public endpoint (used only for demonstration purposes):
- Core: hosts system-level add-ons
- spark driver: hosts spark driver pods
- GPU Spot: hosts spark executor pods
- Ubuntu EKS AMI is used for Spark Driver and Spark executor GPU Node groups
- NVIDIA GPU Operator helm add-on is deployed.
- For scaling and observability, additional add-ons are deployed:
- Amazon EMR on EKS has been configured for multi-tenancy to cater to two distinct teams as an example; more teams can be created:
- emr-ml-team-a and
- emr-ml-team-b
Each team runs their ML workloads in their respective dedicated namespaces with their own Amazon EMR virtual cluster, AWS Identity and Access Management (AWS IAM) roles, and Amazon CloudWatch log groups. This simplifies and facilitates control and access to their respective resources and customized resource needs.
Before we start, you can deploy this solution using AWS Cloud9 or from your own laptop or Mac. Using AWS Cloud9 often leads to a cleaner setup. But, to keep things simple, this guide shows you how to deploy from your personal computer. Now, let’s look at what you need to get started.
Prerequisites
Before you create the test environment using Terraform, you must have the following prerequisites:
- An AWS account with valid AWS credentials with assumed AWS Identity and Access Management ( AWS IAM) role
- The AWS Command Line Interface (AWS CLI) installed
- Terraform 1.0.1
- kubectl installed
After deploying the prerequisites and the infrastructure, follow the steps mentioned below to deploy the solution.
Walkthrough
Deploy infrastructure
Step 1: Clone the GitHub repository
Step 2: Deploy the blueprint
Navigate to the emr-spark-rapids blueprint directory and run the install.sh script. This script runs the terraform init and terraform apply commands with the -target option. This makes sure everything is set up in the right order.
Note: By default, this solution is configured to use the us-west-2 Region. If you intend to deploy this blueprint in a different Region, make sure to update the variables.tf file with the appropriate Region settings.
After setting up the Amazon EKS cluster and the necessary resources, the next step is to prepare a customized Docker image for running the XGBoost job on GPUs.
Step 3: Customizing the Spark-RAPIDS Docker image
To customize the EMR Spark-RAPIDS Docker image according to your specific requirements, you have the flexibility to create a customized version. In this example, we have tailored the EMR Spark-RAPIDS Docker image to include the necessary Python libraries for running XGBoost on PySpark. You can build the customized image using the provided Dockerfile. To get a quick start, you can skip the customization step and directly use the XGBoost supported image available here.
Step 4: Download the input test data
This dataset is sourced from Fannie Mae’s Single-Family Loan Performance Data. All rights are held by Fannie Mae.
- Go to the Fannie Mae website
- Choose the Single-Family Loan Performance Data
- Register as a new user if you are using the website for the first time
- Use the credentials to login
- Select HP
- Choose the Download Data and choose Single-Family Loan Performance Data
- You’ll find a tabular list of Acquisition and Performance files sorted based on year and quarter. Choose the file to download. You can download three years (2020, 2021 and 2022 [4 files for each year and one for each quarter]) worth of data used in our example job. eg: 2017Q1.zip
- Unzip the download file to extract the csv file to your local machine. eg: 2017Q1.csv
- Copy only the CSV files to an Amazon Simple Storage Service (Amazon S3) bucket under
${S3_BUCKET}/${EMR_VIRTUAL_CLUSTER_ID}/spark-rapids-emr/input/fannie-mae-single-family-loan-performance/. The example below uses three years of data (one file for each quarter and 12 files in total). Note:${S3_BUCKET}and${EMR_VIRTUAL_CLUSTER_ID}values can be extracted from Terraform outputs from Step 2.
Launching the XGBoost Spark job
In the previous steps, we completed several tasks to prepare for running the XGBoost Spark job with the Fannie Mae dataset. These tasks include creating a custom EMR Spark RAPIDS Docker image with the necessary libraries, downloading and uploading the dataset to an Amazon S3 bucket, and setting up the required inputs. As described earlier, we’re using XGBoost in a Spark MLlib pipeline to create a delinquency model trained on the Fannie Mae Single Loan Performance dataset. The key point of this example, however, is to demonstrate how you can leverage NVIDIA GPUs to perform faster and more efficient ML training and transformation tasks in distributed computing environment.
To launch the XGBoost Spark job, we use a execute_spark_rapids_xgboost.sh script that prompts for specific inputs. These inputs can be obtained from the Terraform outputs. The following steps describe this approach:
Here’s an example of the inputs you need to provide:
Note: The first execution might take longer as it needs to download the image for the Amazon EMR Job Pod, Driver, and Executor pods. Each pod may take up to 8 minutes to download the Docker image. Subsequent runs should be faster (usually under 30 seconds), thanks to image caching as Kubernetes support the IfNotPresent image cache feature.
Verify the job execution
Once the job has been started, you can verify the status of the pods by running the following:
- Authenticate with the Amazon EKS cluster and create a kubeconfig file locally:
- Verify the running pods’ status in the emr-ml-team-a namespace:
- If you want to see a running log of the job, then you can run the following command:
- To check the status of the job you can either run an AWS CLI command or check the AWS console:

- To verify the logs, you can view them in Amazon CloudWatch or in Amazon S3. In Amazon CloudWatch, open the console and navigate to Log Groups. Find a log group with the name
/emr-on-eks-logs/emr-spark-rapids/emr-ml-team-aand open the latest log stream ending with-driver/stdoutand-driver/stderr.

In Amazon S3, go to your bucket and locate: <bucket name>/logs/spark/<EMR virtual cluster ID>/jobs/<Job ID>/containers/<spark container App ID>/. The following example shows the Spark driver logs.

- In the stdout logs, you should find output similar to the following which shows the Dataset size, ETL time, Training time, and Accuracy, and more.
To see when GPU are used
In the stderr logs, you can find out when GPUs are used by checking for WARN logs showing GPU overrides:
To verify the output dataset and model files in the Amazon S3 bucket:
Navigate to
Open both the stdout.gz and stderr.gz files. The stdout.gz file shows the output printed by the script. Look for the highlighted areas that display timings for ETL tasks, training activities, transformation, and evaluation activities.
You can also verify the output dataset and model files stored in the Amazon S3 bucket:
Output data:
Output model:
The presented diagram illustrates the end-to-end ML pipeline for the Fannie Mae dataset, as demonstrated in the executed example.
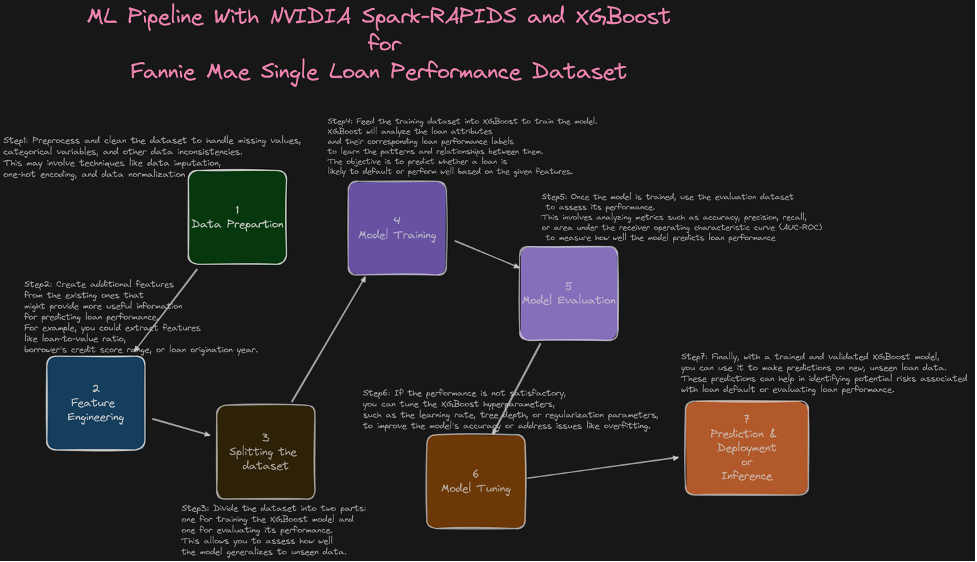
To verify the Spark History Server DAGs:
Open the Amazon EMR console, select Virtual Clusters, select the <EMR_VIRTUAL_CLUSTER_ID>, and choose Spark user interface from the latest job execution. This opens the Spark web user interface, which contains the Spark event logs and allows you to explore the Directed Acyclic Graph (DAGs).
By following these steps, you can easily verify the execution of the XGBoost Spark job, examine the logs, and explore the generated output and model files in Amazon S3 bucket.
GPU Monitoring with DCGM Exporter, Prometheus, and Grafana
Observability plays a critical role in managing and optimizing hardware resources like GPUs, especially in ML workloads that rely heavily on GPU utilization. Real-time monitoring, trend analysis, and anomaly detection are essential for performance tuning, troubleshooting, and efficient resource utilization. The NVIDIA GPU Operator simplifies GPU observability by automating the deployment of necessary components for running GPU workloads on Kubernetes. One such component is the Data Center GPU Manager (DCGM) Exporter, an open-source project that exports GPU metrics in a format compatible with Prometheus, is a popular open-source monitoring solution. These metrics include GPU temperature, memory usage, GPU utilization, and more. With the DCGM Exporter, you can monitor these metrics on a per-GPU basis, gaining granular visibility into your GPU resources.
Pre-installed by the terraform blueprint, DCGM automatically collects GPU metrics and sends them to both Prometheus and Amazon Managed Prometheus (AMP). To verify the GPU metrics, you can use Grafana by running the following command:
Login to Grafana using admin as the username, and retrieve the password from Secrets Manager using the following AWS CLI command:
Once logged in, add the AMP datasource to Grafana and import the Open Source GPU monitoring dashboard. You can then explore the metrics and visualize them using the Grafana dashboard, as shown in the following screenshot.


Cleaning up
To avoid incurring future charges, it is recommended to delete all the resources created by this post. You can use the cleanup.sh script, which helps to delete the resources in a specific order with the correct dependencies.
Conclusion
In this post, we showed you the capabilities of the NVIDIA Spark-RAPIDS Accelerator for running ML workloads with Spark on EMR on EKS using GPU instances. By seamlessly integrating ETL and machine learning training into a single Spark script, data scientists and ML engineers streamlined their work and simplified the overall ML development process. Using the power of NVIDIA GPUs and the parallel processing capabilities of Spark-RAPIDS, we witnessed significant improvements in data processing efficiency and performance. Throughout the post, we followed the recommended solution architecture provided by Data on EKS blueprint, deploying an optimized Amazon EKS cluster with core, Spark driver, and GPU node groups. The NVIDIA GPU Operator played a vital role in managing and provisioning GPU resources within the cluster, while the NVIDIA RAPIDS Accelerator provided high-performance data processing and ML training capabilities. We also explored additional features such as observability and cost optimization through tools like DCGM Exporter, Prometheus and Grafana.
By following the steps outlined in the post, users can effectively deploy and manage their ML workloads on Amazon EMR on EKS with Spark-RAPIDS. The combination of Amazon EMR on EKS with Apache Spark, NVIDIA GPUs, and Spark-RAPIDS offers a powerful solution for accelerating ML data processing and training workflows. Users can expect improved performance, simplified development processes, and valuable insights into GPU utilization and performance.