AWS Big Data Blog
Amazon EMR on EKS widens the performance gap: Run Apache Spark workloads 5.37 times faster and at 4.3 times lower cost
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast and cost-effectively. Also, you can run other types of business applications, such as web applications and machine learning (ML) TensorFlow workloads, on the same EKS cluster. EMR on EKS simplifies your infrastructure management, maximizes resource utilization, and reduces your cost.
We have been continually improving the Spark performance in each Amazon EMR release to further shorten job runtime and optimize users’ spending on their Amazon EMR big data workloads. As of the Amazon EMR 6.5 release in January 2022, the optimized Spark runtime was 3.5 times faster than OSS Spark v3.1.2 with up to 61% lower costs. Amazon EMR 6.10 is now 1.59 times faster than Amazon EMR 6.5, which has resulted in 5.37 times better performance than OSS Spark v3.3.1 with 76.8% cost savings.
In this post, we describe the benchmark setup and results on top of the EMR on EKS environment. We also share a Spark benchmark solution that suits all Amazon EMR deployment options, so you can replicate the process in your environment for your own performance test cases. The solution uses the TPC-DS dataset and unmodified data schema and table relationships, but derives queries from TPC-DS to support the SparkSQL test cases. It is not comparable to other published TPC-DS benchmark results.
Benchmark setup
To compare with the EMR on EKS 6.5 test result detailed in the post Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads, this benchmark for the latest release (Amazon EMR 6.10) uses the same approach: a TPC-DS benchmark framework and the same size of TPC-DS input dataset from an Amazon Simple Storage Service (Amazon S3) location. For the source data, we chose the 3 TB scale factor, which contains 17.7 billion records, approximately 924 GB compressed data in Parquet file format. The setup instructions and technical details can be found in the aws-sample repository.
In summary, the entire performance test job includes 104 SparkSQL queries and was completed in approximately 24 minutes (1,397.55 seconds) with an estimated running cost of $5.08 USD. The input data and test result outputs were both stored on Amazon S3.
The job has been configured with the following parameters that match with the previous Amazon EMR 6.5 test:
- EMR release – EMR 6.10.0
- Hardware:
- Compute – 6 X c5d.9xlarge instances, 216 vCPU, 432 GiB memory in total
- Storage – 6 x 900 NVMe SSD build-in storage
- Amazon EBS root volume – 6 X 20GB gp2
- Spark configuration:
- Driver pod – 1 instance among other 7 executors on a shared Amazon Elastic Compute Cloud (Amazon EC2) node:
spark.driver.cores=4spark.driver.memory=5gspark.kubernetes.driver.limit.cores=4.1
- Executor pod – 47 instances distributed over 6 EC2 nodes
spark.executor.cores=4spark.executor.memory=6gspark.executor.memoryOverhead=2Gspark.kubernetes.executor.limit.cores=4.3
- Driver pod – 1 instance among other 7 executors on a shared Amazon Elastic Compute Cloud (Amazon EC2) node:
- Metadata store – We use Spark’s in-memory data catalog to store metadata for TPC-DS databases and tables—
spark.sql.catalogImplementationis set to the default valuein-memory. The fact tables are partitioned by the date column, which consists of partitions ranging from 200–2,100. No statistics are pre-calculated for these tables.
Results
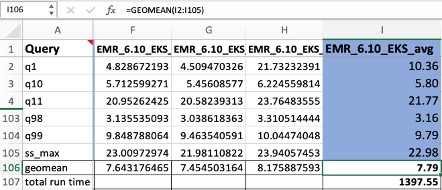
A single test session consists of 104 Spark SQL queries that were run sequentially. We ran each Spark runtime session (EMR runtime for Apache Spark, OSS Apache Spark) three times. The Spark benchmark job produces a CSV file to Amazon S3 that summarizes the median, minimum, and maximum runtime for each individual query.
The way we calculate the final benchmark results (geomean and the total job runtime) are based on arithmetic means. We take the mean of the median, minimum, and maximum values per query using the formula of AVERAGE(), for example AVERAGE(F2:H2). Then we take a geometric mean of the average column I by the formula GEOMEAN(I2:I105) and SUM(I2:I105) for the total runtime.
Previously, we observed that EMR on EKS 6.5 is 3.5 times faster than OSS Spark on EKS, and costs 2.6 times less. From this benchmark, we found that the gap has widened: EMR on EKS 6.10 now provides a 5.37 times performance improvement on average and up to 11.61 times improved performance for individual queries over OSS Spark 3.3.1 on Amazon EKS. From the running cost perspective, we see the significant reduction by 4.3 times.

The following graph shows the performance improvement of Amazon EMR 6.10 compared to OSS Spark 3.3.1 at the individual query level. The X-axis shows the name of each query, and the Y-axis shows the total runtime in seconds on logarithmic scale. The most significant performance gains for eight queries (q14a, q14b, q23b, q24a, q24b, q4, q67, q72) demonstrated over 10 times faster for the runtime.

Job cost estimation
The cost estimate doesn’t account for Amazon S3 storage, or PUT and GET requests. The Amazon EMR on EKS uplift calculation is based on the hourly billing information provided by AWS Cost Explorer.
- c5d.9xlarge hourly price – $1.728
- Number of EC2 instances – 6
- Amazon EBS storage per GB-month – $0.10
- Amazon EBS gp2 root volume – 20GB
- Job run time (hour) –
- OSS Spark 3.3.1 – 2.09
- EMR on EKS 6.5.0 – 0.68
- EMR on EKS 6.10.0 – 0.39
| Cost component | OSS Spark 3.3.1 on EKS | EMR on EKS 6.5.0 | EMR on EKS 6.10.0 |
| Amazon EC2 | $21.67 | $7.05 | $4.04 |
| EMR on EKS | $ – | $1.57 | $0.99 |
| Amazon EKS | $0.21 | $0.07 | $0.04 |
| Amazon EBS root volume | $0.03 | $0.01 | $0.01 |
| Total | $21.88 | $8.70 | $5.08 |
Performance enhancements
Although we improve on Amazon EMR’s performance with each release, Amazon EMR 6.10 contained many performance optimizations, making it 5.37 times faster than OSS Spark v3.3.1 and 1.59 times faster than our first release of 2022, Amazon EMR 6.5. This additional performance boost was achieved through the addition of multiple optimizations, including:
- Enhancements to join performance, such as the following:
- Shuffle-Hash Joins (SHJ) are more CPU and I/O efficient than Shuffle-Sort-Merge Joins (SMJ) when the costs of building and probing the hash table, including the availability of memory, are less than the cost of sorting and performing the merge join. However, SHJs have drawbacks, such as risk of out of memory errors due to its inability to spill to disk, which prevents them from being aggressively used across Spark in place of SMJs by default. We have optimized our use of SHJs so that they can be applied to more queries by default than in OSS Spark.
- For some query shapes, we have eliminated redundant joins and enabled the use of more performant join types.
- We have reduced the amount of data shuffled before joins and the potential for data explosions after joins by selectively pushing down aggregates through joins.
- Bloom filters can improve performance by reducing the amount of data shuffled before the join. However, there are cases where bloom filters are not beneficial and can even regress performance. For example, the bloom filter introduces a dependency between stages that reduces query parallelism, but may end up filtering out relatively little data. Our enhancements allow bloom filters to be safely applied to more query plans than OSS Spark.
- Aggregates with high-precision decimals are computationally intensive in OSS Spark. We optimized high-precision decimal computations to increasing their performance.
Summary
With version 6.10, Amazon EMR has further enhanced the EMR runtime for Apache Spark in comparison to our previous benchmark tests for Amazon EMR version 6.5. When running EMR workloads with the the equivalent Apache Spark version 3.3.1, we observed 1.59 times better performance with 41.6% cheaper costs than Amazon EMR 6.5.
With our TPC-DS benchmark setup, we observed a significant performance increase of 5.37 times and a cost reduction of 4.3 times using EMR on EKS compared to OSS Spark.
To learn more and get started with EMR on EKS, try out the EMR on EKS Workshop and visit the EMR on EKS Best Practices Guide page.
About the Authors
 Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
 Ashok Chintalapati is a software development engineer for Amazon EMR at Amazon Web Services.
Ashok Chintalapati is a software development engineer for Amazon EMR at Amazon Web Services.