AWS Big Data Blog
Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less.
In our benchmark tests using TPC-DS datasets at 3 TB scale, we observed that Amazon EMR on EKS provides up to 61% lower costs and up to 68% improved performance compared to running open-source Apache Spark on Amazon EKS via equivalent configurations. In this post, we walk through the performance test process, share the results, and discuss how to reproduce the benchmark. We also share a few techniques to optimize job performance that could lead to further cost-optimization for your Spark workloads.
How does Amazon EMR on EKS reduce cost and improve performance?
The EMR runtime for Spark is a performance-optimized runtime for Apache Spark that is 100% API compatible with open-source Apache Spark. It’s enabled by default with Amazon EMR on EKS. It helps run Spark workloads faster, leading to lower running costs. It includes multiple performance optimization features, such as Adaptive Query Execution (AQE), dynamic partition pruning, flattening scalar subqueries, bloom filter join, and more.
In addition to the cost benefit brought by the EMR runtime for Spark, Amazon EMR on EKS can take advantage of other AWS features to further optimize cost. For example, you can run Amazon EMR on EKS jobs on Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances, providing up to 90% cost savings when compared to On-Demand Instances. Also, Amazon EMR on EKS supports Arm-based Graviton EC2 instances, which creates a 15% performance improvement and up to 30% cost savings when compared a Graviton2-based M6g to M5 instance type.
The recent graceful executor decommissioning feature makes Amazon EMR on EKS workloads more robust by enabling Spark to anticipate Spot Instance interruptions. Without the need to recompute or rerun impacted Spark jobs, Amazon EMR on EKS can further reduce job costs via critical stability and performance improvements.
Additionally, through container technology, Amazon EMR on EKS offers more options to debug and monitor Spark jobs. For example, you can choose Spark History Server, Amazon CloudWatch, or Amazon Managed Prometheus and Amazon Managed Grafana (for more details, refer to the Monitoring and Logging workshop). Optionally, you can use familiar command line tools such as kubectl to interact with a job processing environment and observe Spark jobs in real time, which provides a fail-fast and productive development experience.
Amazon EMR on EKS supports multi-tenant needs and offers application-level security control via a job execution role. It enables seamless integrations to other AWS native services without a key-pair set up in Amazon EKS. The simplified security design can reduce your engineering overhead and lower the risk of data breach. Furthermore, Amazon EMR on EKS handles security and performance patches so you can focus on building your applications.
Benchmarking
This post provides an end-to-end Spark benchmark solution so you can get hands-on with the performance test process. The solution uses unmodified TPC-DS data schema and table relationships, but derives queries from TPC-DS to support the Spark SQL test case. It is not comparable to other published TPC-DS benchmark results.
Key concepts
Transaction Processing Performance Council-Decision Support (TPC-DS) is a decision support benchmark that is used to evaluate the analytical performance of big data technologies. Our test data is a TPC-DS compliant dataset based on the TPC-DS Standard Specification, Revision 2.4 document, which outlines the business model and data schema, relationship, and more. As the whitepaper illustrates, the test data contains 7 fact tables and 17 dimension tables, with an average of 18 columns. The schema consists of essential retailer business information, such as customer, order, and item data for the classic sales channels: store, catalog, and internet. This source data is designed to represent real-world business scenarios with common data skews, such as seasonal sales and frequent names. Additionally, the TPC-DS benchmark offers a set of discrete scaling points (scale factors) based on the approximate size of the raw data. In our test, we chose the 3 TB scale factor, which produces 17.7 billion records, approximately 924 GB compressed data in Parquet file format.
Test approach
A single test session consists of 104 Spark SQL queries that were run sequentially. To get a fair comparison, each session of different deployment types, such as Amazon EMR on EKS, was run three times. The average runtime per query from these three iterations is what we analyze and discuss in this post. Most importantly, it derives two summarized metrics to represent our Spark performance:
- Total execution time – The sum of the average runtime from three iterations
- Geomean – The geometric mean of the average runtime
Test results
In the test result summary (see the following figure), we discovered that the Amazon EMR-optimized Spark runtime used by Amazon EMR on EKS is approximately 2.1 times better than the open-source Spark on Amazon EKS in geometric mean and 3.5 times faster by the total runtime.
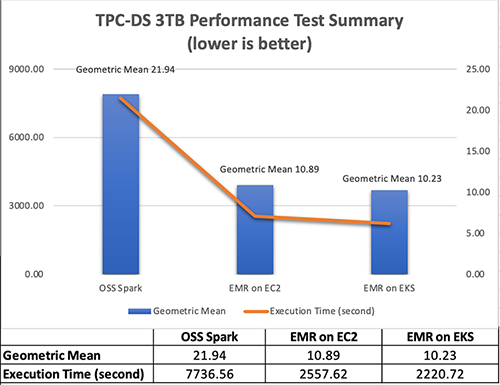
The following figure breaks down the performance summary by queries. We observed that EMR runtime for Spark was faster in every query compared to open-source Spark. Query q67 was the longest query in the performance test. The average runtime with open-source Spark was 1019.09 seconds. However, it took 150.02 seconds with Amazon EMR on EKS, which is 6.8 times faster. The highest performance gain in these long-running queries was q72—319.70 seconds (open-source Spark) vs. 26.86 seconds (Amazon EMR on EKS), a 11.9 times improvement.

Test cost
Amazon EMR pricing on Amazon EKS is calculated based on the vCPU and memory resources used from the time you start to download your EMR application Docker image until the Amazon EKS pod terminates. As a result, you don’t pay any Amazon EMR charges until your application starts to run, and you only pay for the vCPU and memory used during a job—you don’t pay for the full amount of compute resources in an EC2 instance.
Overall, the estimated benchmark cost in the US East (N. Virginia) Region is $22.37 per run for open-source Spark on Amazon EKS and $8.70 per run for Amazon EMR on EKS – that’s 61% cheaper due to the 68% quicker job runtime. The following table provides more details.
| Benchmark Job | Runtime (Hour) | Estimated Cost | Total EC2 Instance | Total vCPU | Total Memory (GiB) | Root Device (EBS) |
| Amazon EMR on EKS | 0.68 | $8.70 | 6 | 216 | 432 | 20 GiB gp2 |
| Open-Source Spark on Amazon EKS | 2.13 | $22.37 | 6 | 216 | 432 | 20 GiB gp2 |
|
Amazon EMR on Amazon EC2 (1 primary and 5 core nodes) |
0.80 | $8.80 | 6 | 196 | 424 | 20 GiB gp2 |
The cost estimate doesn’t account for Amazon Simple Storage Service (Amazon S3) storage, or PUT and GET requests. The Amazon EMR on EKS uplift calculation is based on the hourly billing information provided by AWS Cost Explorer.
Cost breakdown
The following is the cost breakdown for the Amazon EMR on EKS job ($8.70):
- Total uplift on vCPU – (126.93 * $0.01012) = (total number of vCPU used * per vCPU-hours rate) = $1.28
- Total uplift on memory – (258.7 * $0.00111125) = (total amount of memory used * per GB-hours rate) = $0.29
- Total Amazon EMR uplift cost – $1.57
- Total Amazon EC2 cost – (6 * $1.728 * 0.68) = (number of instances * c5d.9xlarge hourly rate * job runtime in hour) = $7.05
- Other costs – ($0.1 * 0.68) + ($0.1/730 * 20 * 6 * 0.68) = (shared Amazon EKS cluster charge per hour * job runtime in hour) + (EBS per GB-hourly rate * root EBS size * number of instances * job runtime in hour) = $0.08
The following is the cost breakdown for the open-source Spark on Amazon EKS job ($22.37):
- Total Amazon EC2 cost – (6 * $1.728 * 2.13) = (number of instances * c5d.9xlarge hourly rate * job runtime in hour) = $22.12
- Other costs – ($0.1 * 2.13) + ($0.1/730 * 20 * 6 * 2.13) = (shared EKS cluster charge per hour * job runtime in hour) + (EBS per GB-hourly rate * root EBS size * number of instances * job runtime in hour) = $0.25
The following is the cost breakdown for the Amazon EMR on Amazon EC2 ($8.80):
- Total Amazon EMR cost – (5 * $0.27 * 0.80) + (1 * $0.192 * 0.80) = (number of core nodes * c5d.9xlarge Amazon EMR price * job runtime in hour) + (number of primary nodes * m5.4xlarge Amazon EMR price * job runtime in hour) = $1.23
- Total Amazon EC2 cost – (5 * $1.728 * 0.80) + (1 * $0.768 * 0.80) = (number of core nodes * c5d.9xlarge instance price * job runtime in hour) + (number of primary nodes * m5.4xlarge instance price * job runtime in hour) = $7.53
- Other Cost – ($0.1/730 * 20 GiB * 6 * 0.80) + ($0.1/730 * 256 GiB * 1 * 0.80) = (EBS per GB-hourly rate * root EBS size * number of instances * job runtime in hour) + (EBS per GB-hourly rate * default EBS size for m5.4xlarge * number of instances * job runtime in hour) = $0.041
Benchmarking considerations
In this section, we share some techniques and considerations for the benchmarking.
Set up an Amazon EKS cluster with Availability Zone awareness
Our Amazon EKS cluster configuration looks as follows:
In the cluster configuration, the mn-od managed node group is assigned to the single Availability Zone b, where we run the test against.
Availability Zones are physically separated by a meaningful distance from other Availability Zones in the same AWS Region. This produces round trip latency between two compute instances located in different Availability Zones. Spark implements distributed computing, so exchanging data between compute nodes is inevitable when performing data joins, windowing, and aggregations across multiple executors. Shuffling data between multiple Availability Zones adds extra latency to the network I/O, which therefore directly impacts Spark performance. Additionally, when data is transferred between two Availability Zones, data transfer charges apply in both directions.
For this benchmark, which is a time-sensitive workload, we recommend running in a single Availability Zone and using On-Demand instances (not Spot) to have a dedicated compute resource. In an existing Amazon EKS cluster, you may have multiple instance types and a Multi-AZ setup. You can use the following Spark configuration to achieve the same goal:
Use instance store volume to increase disk I/O
Spark data shuffle, the process of reading and writing intermediate data to disk, is a costly operation. Besides the network I/O speed, Spark demands high performant disk to support a large amount of data redistribution activities. I/O operations per second (IOPS) is an equally important measure to baseline Spark performance. For instance, the SQL queries 23a, 23b, 50, and 93 are shuffle-intensive Spark workloads in TPC-DS, so choosing an optimal storage strategy can significantly shorten their runtime. General speaking, the recommended options are either attaching multiple EBS disk volumes per node in Amazon EKS or using the d series EC2 instance type, which offers high disk I/O performance within a compute family (for example, c5d.9xlarge is the d series in the c5 compute optimized family).
The following table summarizes the hardware specification we used:
| Instance | On-Demand Hourly Price | vCPU | Memory (GiB) | Instance Store | Networking Performance (Gbps) | 100% Random Read IOPS | Write IOPS |
| c5d.9xlarge | $1.73 | 36 | 72 | 1 x 900GB NVMe SSD | 10 | 350,000 | 170,000 |
To simplify our hardware configuration, we chose the AWS Nitro System EC2 instance type c5d.9xlarge, which comes with a NVMe-based SSD instance store volume. As of this writing, the built-in NVMe SSD disk requires less effort to set up and provides optimal disk performance we need. In the following code, the one-off preBoostrapCommand is triggered to mount an instance store to a node in Amazon EKS:
Run as a predefined job user, not a root user
For security, it’s not recommended to run Spark jobs as a root user. But how can you access the NVMe SSD volume mounted to the Amazon EKS cluster as a non-root Spark user?
An init container is created for each Spark driver and executor pods in order to set the volume permission and control the data access. Let’s check out the Spark driver pod via the kubectl exec command, which allows us execute into the running container and have an interactive session. We can observe the following:
- The init container is called
volume-permission. - The SSD disk is called
/ossdata1. The Spark driver has stored some data to the disk. - The non-root Spark job user is called
hadoop.

This configuration is provided in a format of a pod template file for Amazon EMR on EKS, so you can dynamically tailor job pods when Spark configuration doesn’t support your needs. Be aware that the predefined user’s UID in the EMR runtime for Spark is 999, but it’s set to 1000 in open-source Spark. The following is a sample Amazon EMR on EKS driver pod template:
In the job submission, we map the pod templates via the Spark configuration:
Spark on k8s operator is a popular tool to deploy Spark on Kubernetes. Our open-source Spark benchmark uses the tool to submit the job to Amazon EKS. However, the Spark operator currently doesn’t support file-based pod template customization, due to the way it operates. So we embed the disk permission setup into the job definition, as in the example on GitHub.
Disable dynamic resource allocation and enable Adaptive Query Execution in your application
Spark provides a mechanism to dynamically adjust compute resources based on workload. This feature is called dynamic resource allocation. It provides flexibility and efficiency to manage compute resources. For example, your application may give resources back to the cluster if they’re no longer used, and may request them again later when there is demand. It’s quite useful when your data traffic is unpredictable and an elastic compute strategy is needed at your application level. While running the benchmarking, our source data volume (3 TB) is certain and the jobs were run on a fixed-size Spark cluster that consists of six EC2 instances. You can turn off the dynamic allocation in EMR on EC2 as shown in the following code, because it doesn’t suit our purpose and might add latency to the test result. The rest of Spark deployment options, such as Amazon EMR on EKS, has the dynamic allocation off by default, so we can ignore these settings.
Dynamic resource allocation is a different concept from automatic scaling in Amazon EKS, such as the Cluster Autoscaler. Disabling the dynamic allocation feature only fixes our 6-node Spark cluster size per job, but doesn’t stop the Amazon EKS cluster from expanding or shrinking automatically. It means our Amazon EKS cluster is still able to scale between 1 and 30 EC2 instances, as configured in the following code:
Spark Adaptive Query Execution (AQE) is an optimization technique in Spark SQL since Spark 3.0. It dynamically re-optimizes the query execution plan at runtime, which supports a variety of optimizations, such as the following:
- Dynamically switch join strategies
- Dynamically coalesce shuffle partitions
- Dynamically handle skew joins
The feature is enabled by default in EMR runtime for Spark, but disabled by default in open-source Apache Spark 3.1.2. To provide the fair comparison, make sure it’s set in the open-source Spark benchmark job declaration:
Walkthrough overview
With these considerations in mind, we run three Spark jobs in Amazon EKS. This helps us compare Spark 3.1.2 performance in various deployment scenarios. For more details, check out the GitHub repository.
In this walkthrough, we show you how to do the following:
- Produce a 3 TB TPC-DS complaint dataset
- Run a benchmark job with the open-source Spark operator on Amazon EKS
- Run the same benchmark application with Amazon EMR on EKS
We also provide information on how to benchmark with Amazon EMR on Amazon EC2.
Prerequisites
Install the following tools for the benchmark test:
- The AWS Command Line Interface (AWS CLI) version 2.1.14 or higher (for instructions, refer to Installing or updating the latest version of the AWS CLI)
- eksctl
- kubectl
- Helm CLI
- Docker on Mac (for Linux or Windows OS, refer to Docker Desktop overview)
Provision resources
The provision script creates the following resources:
- A new Amazon EKS cluster
- Amazon EMR on EKS enabler
- The required AWS Identity and Access Management (IAM) roles
- The S3 bucket
emr-on-eks-nvme-${ACCOUNTID}-${AWS_REGION}, referred to as <S3BUCKET> in the following steps
The provisioning process takes approximately 30 minutes.
- Download the project with the following command:
- Create a test environment (change the Region if necessary):
Modify the script if needed for testing against an existing Amazon EKS cluster. Make sure the existing cluster has the Cluster Autoscaler and Spark Operator installed. Examples are provided by the script.
- Validate the setup:
Generate TPC-DS test data (optional)
In this optional task, you generate TPC-DS test data in s3://<S3BUCKET>/BLOG_TPCDS-TEST-3T-partitioned. The process takes approximately 80 minutes.
The job generates TPC-DS compliant datasets with your preferred scale. In this case, it creates 3 TB of source data (approximately 924 GB compressed) in Parquet format. We have pre-populated the source dataset in the S3 bucket blogpost-sparkoneks-us-east-1 in Region us-east-1. You can skip the data generation job if you want to have a quick start.
Be aware of that cross-Region data transfer latency will impact your benchmark result. It’s recommended to generate the source data to your S3 bucket if your test Region is different from us-east-1.
- Start the job:
- Monitor the job progress:
- Cancel the job if needed:
The job runs in the namespace oss with a service account called oss in Amazon EKS, which grants a minimum permission to access the S3 bucket via an IAM role. Update the example .yaml file if you have a different setup in Amazon EKS.
Benchmark for open-source Spark on Amazon EKS
Wait until the data generation job is complete, then update the default input location parameter (s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned) to your S3 bucket in the tpcds-benchmark.yaml file. Other parameters in the application can also be adjusted. Check out the comments in the yaml file for details. This process takes approximately 130 minutes.
If the data generation job is skipped, run the following steps without waiting.
- Start the job:
- Monitor the job progress:
- Cancel the job if needed:
The benchmark application outputs a CSV file capturing runtime per Spark SQL query and a JSON file with query execution plan details. You can use the collected metrics and execution plans to compare and analyze performance between different Spark runtimes (open-source Apache Spark vs. EMR runtime for Spark).
Benchmark with Amazon EMR on EKS
Wait for the data generation job finish before starting the benchmark for Amazon EMR on EKS. Don’t forget to change the input location (s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned) to your S3 bucket. The output location is s3://<S3BUCKET>/EMRONEKS_TPCDS-TEST-3T-RESULT. If you use the pre-populated TPC-DS dataset, start the Amazon EMR on EKS benchmark without waiting. This process takes approximately 40 minutes.
- Start the job (change the Region if necessary):
Amazon EKS offers multi-tenant isolation and optimized resource allocation features, so it’s safe to run two benchmark tests in parallel on a single Amazon EKS cluster.
- Monitor the job progress in real time:
- Cancel the job (get the IDs from the cluster list on the Amazon EMR console):
The following are additional useful commands:
Benchmark for Amazon EMR on Amazon EC2
Optionally, you can use the same benchmark solution to test Amazon EMR on Amazon EC2. Download the benchmark utility application JAR file from a running Kubernetes container, then submit a job via the Amazon EMR console. More details are available in the GitHub repository.
Clean up
To avoid incurring future charges, delete the resources generated if you don’t need the solution anymore. Run the following cleanup script (change the Region if necessary):
Conclusion
Without making any application changes, we can run Apache Spark workloads faster and cheaper with Amazon EMR on EKS when compared to Apache Spark on Amazon EKS. We used a benchmark solution running on a 6-node c5d.9xlarge Amazon EKS cluster and queried a TPC-DS dataset at 3 TB scale. The performance test result shows that Amazon EMR on EKS provides up to 61% lower costs and up to 68% performance improvement over open-source Spark 3.1.2 on Amazon EKS.
If you’re wondering how much performance gain you can achieve with your use case, try out the benchmark solution or the EMR on EKS Workshop. You can also contact your AWS Solution Architects, who can be of assistance alongside your innovation journey.
About the Authors
 Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
 Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.