Containers
Scaling StarRocks on Amazon EKS with KEDA and Karpenter for enterprise OLAP workloads
Financial analytics at enterprise scale is unforgiving. Queries must return in seconds, not minutes. Thousands of finance professionals need concurrent access during monthly close cycles. And when data volumes grow from hundreds of gigabytes to terabytes, spanning billions of records, the infrastructure underneath must scale without forcing engineers to choose between performance and cost.
This is the challenge the Amazon WW Stores FinTech team faced. We build and operate analytical products covering financial reporting, planning and allocation, self-serve analytics, and AI-powered financial insights, serving thousands of finance users every business day.
As workloads scaled, the gap between what our systems could deliver and what our finance teams needed grew impossible to ignore. The demands were clear:
- Sub-second to single-digit-second query responses across terabytes of financial data
- Hundreds of concurrent users supported during peak business cycles
- Horizontal scaling without disruptive data rebalancing
Our existing systems could satisfy one or two of these dimensions in isolation, but not all three simultaneously at the data volumes we were projecting. This wasn’t a migration problem, it was a greenfield opportunity to build the right analytical foundation from scratch.
This post shares what we found, the architecture we built on Amazon Elastic Kubernetes Service (Amazon EKS), and how we use KEDA and Karpenter to elastically scale StarRocks for bursty enterprise financial workloads. We partnered with the Data on EKS team on the reference blueprints that back this infrastructure.
The analytical challenge
Financial analytics differs fundamentally from general operational analytics. It involves deeply nested hierarchies, multi-dimensional pivots, and complex join chains that stress analytical engines in ways that standard benchmarks fail to capture. To make the evaluation meaningful, we needed to test against data and queries that reflected our actual production conditions.
We worked with two production-representative datasets that together, captured the full range of our analytical workloads. The first covered hierarchical financial data organized around multi-level dimensional structures with complex join patterns across three to seven tables. The second comprised operational data, characterized by high-cardinality aggregations across millions of distinct values. Together, these datasets represented the two most demanding workload shapes in our production environment. Rather than relying on generic benchmark queries, we defined a Query Complexity Framework to systematically evaluate each engine against the real patterns our finance workloads exhibit:
- High-Cardinality Filtering: WHERE clauses on columns with large distinct value counts (for example, cost center or revenue classification codes)
- Data Aggregation: GROUP BY operations with complex aggregate functions across large fact datasets
- Complex Data Relationships: Star schema patterns with over 3 table JOINs
- Pivot Transformations: Converting row values into columnar format for financial reporting
- Hierarchical Navigation: Drill-down operations across parent-child reporting hierarchies
A single financial query routinely spans several of these dimensions simultaneously. That combination is what makes financial OLAP workloads significantly harder than what standard benchmarks test for. Using this framework, we designed a comprehensive set of benchmark queries with clear targets: sub-5 seconds for standard queries, sub-20 seconds for complex queries, and linear scalability from 50 to 1,000 concurrent users.
We evaluated two Online Analytical Processing (OLAP) candidates, StarRocks (3.4.0) and ClickHouse (25.6.4.12), on identical infrastructure to ensure a fair comparison deployed across multiple availability zones.
Benchmark results: StarRocks compared to ClickHouse
StarRocks is an open source MPP analytical database with a Cost-Based Optimizer and shared-data architecture, designed for concurrent complex analytical workloads. ClickHouse is an open source columnar OLAP database optimized for fast single-table aggregations and high-throughput data ingestion on simpler query patterns.
Running both engines through our Query Complexity Framework against our actual production datasets produced clear results:
| Query Pattern | ClickHouse | StarRocks (External Catalog) | StarRocks (Local / Native) |
| Simple scans – no JOINs | 33% higher throughput; lower P95 | Baseline | Best – local indexes accelerate lookups |
| Simple scans at peak (1,000 users) | Baseline | 1.5X better P95 vs ClickHouse | Best P95 at scale |
| Single JOIN | Baseline | .5X higher throughput; .5X lower P95 | Best – indexed dimension lookups |
| Multi-JOIN (over 2–3 tables) | Baseline |
3X-5X higher throughput; .8X lower P95 |
Best – 36x less data scanned |
| Filtered scans (over 3 filters) | Baseline | 2X higher throughput; .6Xlower P95 | Best – local indexes |
| TB-scale ingestion |
Excellent – ~6min/TB (after EBS tuning) |
N/A – queries in-place from S3 | Good – 30+ min/TB using Spark connector |
| High-cardinality GROUP BY | Excellent | Excellent | Excellent |
| Pivot operations | Excellent | Baseline | Good- reduced I/O overhead |
Note: The Local / Native column reflects benchmarks where all data resided on BE nodes. In production, we use a hybrid approach—dimension tables are ingested into indexed native tables on BE nodes for accelerated joins, while fact tables remain in S3 and are queried through External Catalog using CN nodes.
Why we chose StarRocks
The benchmark results told a clear story. Straightforward queries flatter both engines. At low complexity, ClickHouse and StarRocks performed similarly, with ClickHouse showing a slight edge on straightforward aggregations. As query patterns moved toward what our finance users actually run (multi-table joins, hierarchical pivots, and high-cardinality filters applied simultaneously), the engines diverged sharply. ClickHouse does hold genuine advantages: it ingests TB-scale data faster and excels on straightforward query patterns. For ours, where complex, concurrent financial queries define the baseline, those strengths were not enough.
StarRocks’ Cost-Based Optimizer self-tunes query plans as data distributions change, which is why performance held up across multi-table joins, hierarchical pivots, and high-cardinality filters without manual intervention. Just as importantly, External Catalog queries through AWS Glue delivered strong baseline performance for analytical scans without requiring data ingestion first—teams query existing Hive and Iceberg tables directly.
StarRocks’ stateless Compute Nodes (CN) carry no persistent data, so they scale in and out instantly with no rebalancing or disruption to running queries—exactly what makes KEDA-driven autoscaling practical for an OLAP workload. Its hybrid architecture gave us deployment options most OLAP engines can’t offer, stateless CNs scale against data in Amazon Simple Storage Service (Amazon S3), while dedicated Backend (BE) nodes add indexed local storage for dimension join acceleration, all within the same cluster. These properties gave us the confidence that StarRocks would scale with our workload rather than constrain it.
Architecture on Amazon EKS
Our architecture on Amazon EKS uses the StarRocks Kubernetes Operator to manage the full cluster lifecycle using a declarative StarRocksCluster CRD, providing automated rolling updates and self-healing without the need to build custom management tooling. Frontend (FE) nodes serve as the control plane, using a three-node Raft quorum for leader election and metadata consistency, ensuring high availability (HA) for SQL parsing and query coordination.
The data layer is split into two tiers to optimize for different access patterns. Backend (BE) nodes are deployed as StatefulSets using Amazon EBS volumes (PV/PVCs) to provide durable, high-performance storage for indexed dimension tables and operational telemetry. This persistence ensures that indexed lookups and local data scans consistently outperform S3-based access for our highest-frequency reporting workloads. In contrast, Compute Nodes (CN) provide an elastic, shared-data layer that pulls from Amazon S3 and maintains only ephemeral local caches. Because CNs are stateless and managed as Deployments, they bypass the slow, ordered sequencing of StatefulSets. This allows KEDA with ScaledObjects to scale compute resources near-instantly with no data movement required to meet fluctuating query demands while maintaining the cost benefits of a shared-data architecture.
StarRocks offers Shared-Nothing (BE nodes with local storage and compute) and Shared-Data (stateless CN nodes backed by object storage with local caching) architectures. StarRocks Kubernetes Operator’s StarRocksCluster CRD supports both using starRocksBeSpec and starRocksCnSpec, enabling hybrid deployments in a single cluster. Our production deployment combines both modes within the same cluster: CN nodes provide elastic, stateless compute for fact table scans against data in Amazon S3 using AWS Glue Catalog, while BE nodes store indexed dimension tables on persistent EBS volumes for accelerated join performance. CN nodes scale freely for burst demand with no data movement; BE nodes remove S3 round trips for the dimension lookups that dominate our join-heavy financial queries. The StarRocks query planner routes each workload to the appropriate tier automatically.
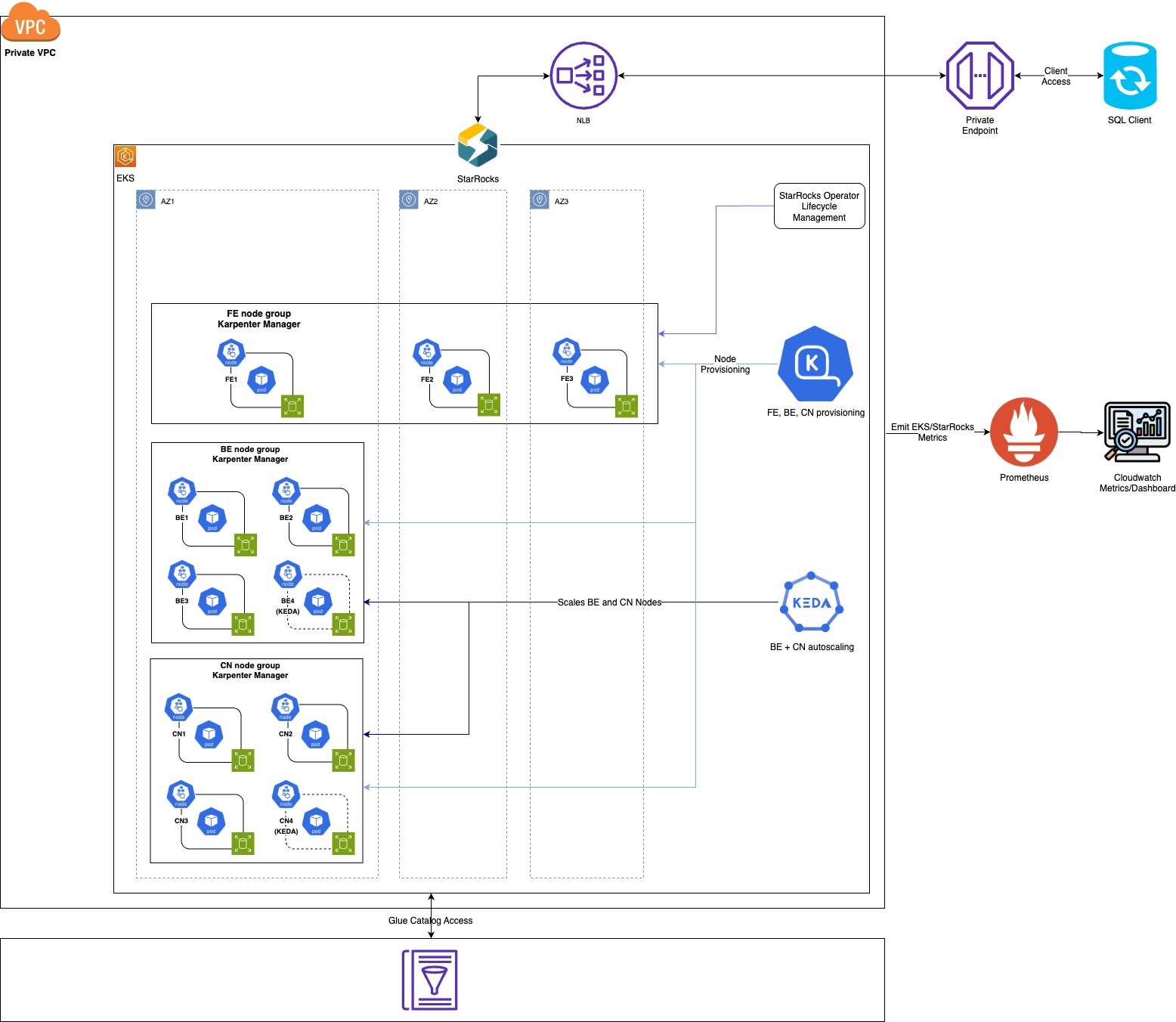
Figure 1: StarRocks on Amazon EKS production architecture spanning three availability zones. Each node role (FE, BE, CN) runs in dedicated Karpenter NodePools. KEDA drives autoscaling for both BE and CN nodes based on Prometheus metrics. StarRocks Operator manages cluster lifecycle, and AWS Glue Catalog enables federated data lake queries.
Connectivity, integration, and monitoring
Client tools including internal BI platforms, and SQL Workbench connect through AWS PrivateLink and a Network Load Balancer, ensuring private, secure connectivity without traversing the public internet. StarRocks’ external catalog feature enables federated queries across our data ecosystem. AWS Glue Data Catalog serves as the central metadata store, and StarRocks queries Hive and Apache Iceberg tables in S3 through it without a separate ingestion step. External Catalog queries deliver strong baseline performance for analytical scans, letting teams start querying their existing data lake immediately. For join-heavy workloads, ingesting dimension tables into indexed native tables on EBS volumes delivers measurably faster response times. This is a clear optimization path as workloads mature. For native table ingestion, AWS Glue Jobs with the StarRocks Spark Connector handle batch pipelines. Cross-account catalog access supports our multi-account AWS organization structure.
For monitoring, we combine Prometheus for StarRocks metrics collection, covering FE query counts, BE memory utilization, CN cache hit rates, and query queue depth, with Amazon CloudWatch for centralized dashboards, alerting, and operational runbook integration.
Elastic Scaling with KEDA and Karpenter
Traditional OLAP systems couple storage and compute tightly, making elastic scaling impractical. You either overprovision for peaks or accept degraded performance when load spikes. StarRocks breaks this constraint through two layers of automation.
KEDA (Kubernetes Event-Driven Autoscaling) monitors StarRocks-specific metrics through Prometheus—query queue depth, CPU and memory utilization, and pending query counts—and automatically adjusts pod counts to match real demand rather than relying on basic resource thresholds alone. CN nodes are fully stateless and begin serving queries the moment they join (no data movement required) making them the first line of defense for burst load. BE nodes scale independently for a different purpose. They expand storage capacity and query execution parallelism for sustained load increases, with StarRocks replicating data shards to new replicas automatically, though they need time to warm up.
Karpenter takes over at the infrastructure layer. When KEDA requests additional pods and they land in the Kubernetes scheduler queue, Karpenter provisions right-sized EC2 instances on demand instead of relying on pre-warmed node pools. FE and BE NodePools run on On-Demand instances to protect coordination and persistent data, while CN NodePools use Spot instances since stateless nodes tolerate interruptions gracefully. Each role runs in a dedicated NodePool, so scaling decisions for one never interfere with another. The end-to-end flow is straightforward: rising query load triggers KEDA, KEDA scales pods, Karpenter provisions nodes, and new capacity registers with StarRocks—instantly for CNs, progressively for BEs as data replicates. When load drops, Karpenter consolidates underutilized nodes automatically, returning the cluster to its baseline with no manual intervention.
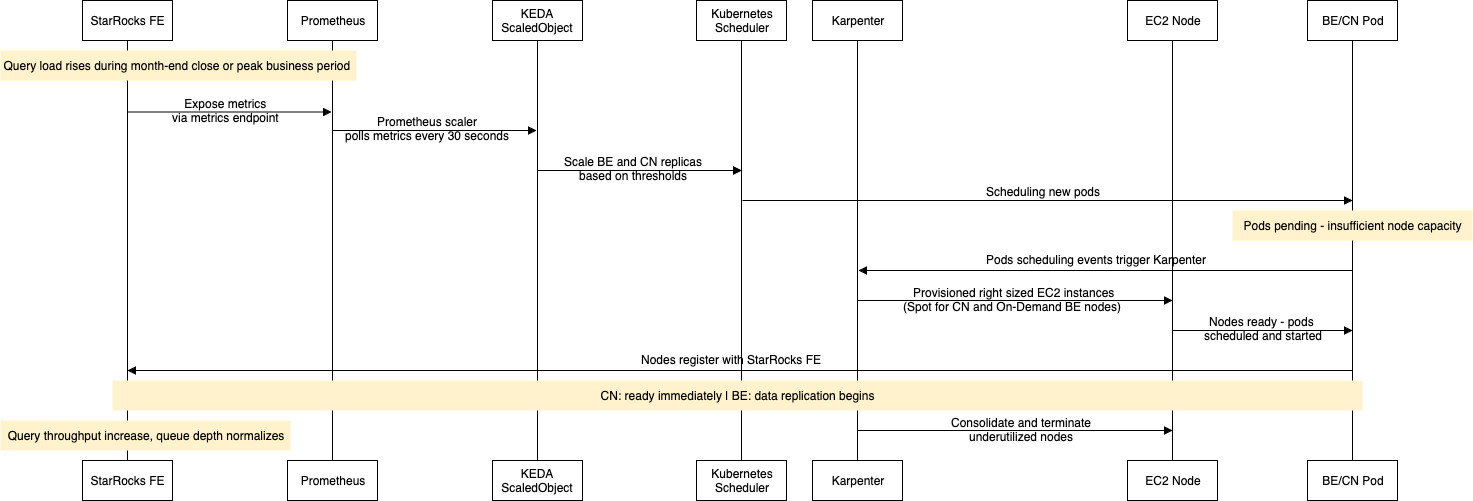
Figure 2: End-to-end KEDA and Karpenter scaling flow for StarRocks nodes, covering the full path from rising query load to new nodes joining the cluster.
Lessons learned and operational insights
Building and running StarRocks on EKS at production scale taught us several things that are difficult to learn from documentation alone.
1. Memory management requires active tuning
During 1,000-user stress tests, memory limit exceeded errors caused roughly 40 percent query failures. Multi-join queries exhausted per-BE memory limits, and CN nodes were under-provisioned for complex scan patterns. We resolved this by migrating to memory-optimized EC2 instances for BE nodes, configuring StarRocks Resource Groups to cap and queue queries instead of failing them, and tuning query_mem_limit per workload profile. Peak error rates dropped from 40 percent to under 5 percent.
2. S3 I/O Bottlenecks and the Hybrid Architecture Fix
CN-heavy deployments hit throughput bottlenecks under concurrent scans. S3 request limits and network constraints caused P95 latency spikes on complex joins. The fix: dimension tables with indexes moved to BE nodes on EBS to remove S3 round trips, while CN nodes handle fact table scans and burst queries. The StarRocks query planner routes workloads automatically, no application-layer changes needed.
3. SQL dialect migration from Amazon Athena and Presto
Despite StarRocks’ ANSI SQL and MySQL protocol support, teams encountered friction around function naming, array syntax, type conversions, and correlated subqueries. We built an internal translation guide and validation test suite for pre-migration query verification.
4. Tune EBS throughput before benchmarking any EBS-Backed system
Although we selected StarRocks, our ClickHouse evaluation produced one broadly useful operational finding. EBS throughput configuration is critical for any EBS-backed analytical workload. With default gp3 throughput at 125 MB/s, loading our 4.7 TB dataset took 13 hours. After adjusting to 1,000 MB/s with optimized IOPS settings, the same load completed in 25 minutes, a 31x improvement. Anyone evaluating ClickHouse or any EBS-backed system should tune these settings before drawing performance conclusions.
5. Instance type selection for StarRocks Node roles
Each node role has a distinct resource profile. We configure multiple instance types per Karpenter NodePool so Karpenter can optimize for availability and cost, especially important for CN Spot instances during peak scaling.
| Role | Sizing | Instance Types |
| FE (query planning, metadata) | 32 vCPU, 64–128 GB | c6i.8xlarge , c6in.8xlarge , m5.8xlarge |
| BE & CN (data scans, joins, aggregations) | 96 vCPU, 384–768 GB | r6i.24xlarge , m6in.24xlarge , r6in.24xlarge , m5n.24xlarge |
Lesson 1 revealed FE nodes were CPU bound, but rarely hit memory limits, while BE and CN nodes consistently exhausted memory and network throughput during complex joins and S3 reads. Compute-optimized families fit FE; memory-optimized with enhanced networking resolved BE and CN bottlenecks.
6. Future optimization
While our EBS-based production baseline remains the standard, we’re exploring storage-optimized EC2 instances with local NVMe SSDs for the BE layer to push the performance ceiling, minimizing storage latency and maximizing throughput for sub-second analytical workloads with the most extreme latency demands.
Key takeaways
- Always benchmark with your actual data, not generic tests. Our Query Complexity Framework revealed engine differences that standard benchmarks would have missed, and gave us defensible results across product teams with different priorities.
- Striaghtforward query speed doesn’t equal the best OLAP engine. ClickHouse outperformed StarRocks on no-JOIN queries at low concurrency. But those patterns represented a small fraction of our actual workload distribution. Always evaluate against the full spectrum of queries your users actually run.
- Shared-data architecture on EKS enables elastic scaling that tightly coupled systems can’t. CN node statelessness is the architectural primitive that makes KEDA and Karpenter OLAP autoscaling practical. BE scaling adds a complementary layer for sustained load growth.
Conclusion
Running large-scale financial analytics on Kubernetes requires a clear-eyed evaluation of workload characteristics, an honest comparison of engine trade-offs, and an architectural foundation designed to scale elastically from the start.
By combining StarRocks’ Cost-Based Optimizer and flexible hybrid deployment with KEDA’s event-driven pod scaling and Karpenter’s just-in-time node provisioning, our team built an analytical solution that delivers sub-5-second standard query responses and sub-20-second complex query responses at 1,000 concurrent users while preserving the cost efficiency that elastic compute scaling makes possible. The architecture isn’t specific to financial analytics. Any team with complex, variable analytical workloads and a data lake strategy on AWS can apply the same pattern: decouple storage and compute, instrument for real demand signals, and let the infrastructure respond automatically. The production-ready blueprints, Helm configurations, and autoscaling reference implementations used in this deployment are published in the Data on EKS project.
Acknowledgements
We would like to recognize Candice Xu (Data Engineer) and JP Bonard (Senior Data Engineer), who played a pivotal role in selecting StarRocks as our OLAP engine. Their contributions (benchmarking performance, conducting load testing, and building the data model and StarRocks platform for the organization) were instrumental to this work.