Containers
Start Pods faster by prefetching images
Introduction
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) to run machine learning workloads. Containerization allows machine learning engineers to package and distribute models easily, while Kubernetes helps in deploying, scaling, and improving. When working with customers that run machine learning training jobs in Kubernetes, we ‘ve seen that as the data set and model size grows, so does the container image size, which results in slow containers startup.
The slow container startup problem isn’t unique to machine learning and artificial intelligence. We have seen similar issues in build environments and data analytics workloads. The container images for these workloads include data, libraries, and dependencies. As a result, these images can vary from a few hundred MBs to tens of GBs.
When images grow beyond a few hundred MBs, it can take several minutes to start a container. The primary reason for this slowness is that the container runtime must pull the entire container image before the container can start. Kubernetes solves this problem by caching images on nodes. However, that only reduces the startup time for subsequent containers because the first image pull remains a challenge.
Several community projects such as Kubernetes-image-puller have attempted to tackle this issue by prefetching larger images. The idea is to pull the image on nodes before a Pod gets scheduled. These projects add another component that customers must manage because they rely on DaemonSets and CronJobs to maintain a cached copy of large images. This post proposes a design that allows you to pre-pull images on nodes without managing infrastructure or Kubernetes resources.
Amazon EKS data plane management with AWS Systems Manager
AWS Systems Manager is a secure end-to-end management solution for AWS resources. It offers a suite of operational management tools to simplify the management of AWS resources, automate operational tasks, and streamline IT operations at scale.
With AWS Systems Manager, you can securely manage instances, automate patching and software installations, monitor and collect operational data, and enable remote access to instances, which makes it an essential tool for efficiently managing your AWS infrastructure. You can use AWS Systems Manager to customize nodes as they get created.
In this post we use AWS Systems Manager State Manager to cache container images on nodes. To keep the cache current, the solution uses an event-driven architecture to update the cache as new images get pushed to the image registry. By caching container images on nodes, we significantly reduce the container startup time. When containers get created, the container runtime doesn’t spend any time pulling the image from the container registry. As a result, horizontal scaling occurs almost immediately.
Solution overview
We’ll reduce the Pod startup time by caching images for a sample application before a Pod gets scheduled on the node. The solution uses Amazon EventBridge and AWS Systems Manager for the automation. Whenever we push a new image to the sample application’s Amazon Elastic Container Registry (Amazon ECR) repository, AWS Systems Manager executes commands to pull the new image on all worker nodes.
As new worker nodes start, AWS Systems Manager runs similar automation to pull the image. Below is the architecture diagram for setting up an event-driven process to prefetch data to Amazon EKS Nodes using SSM Automation.
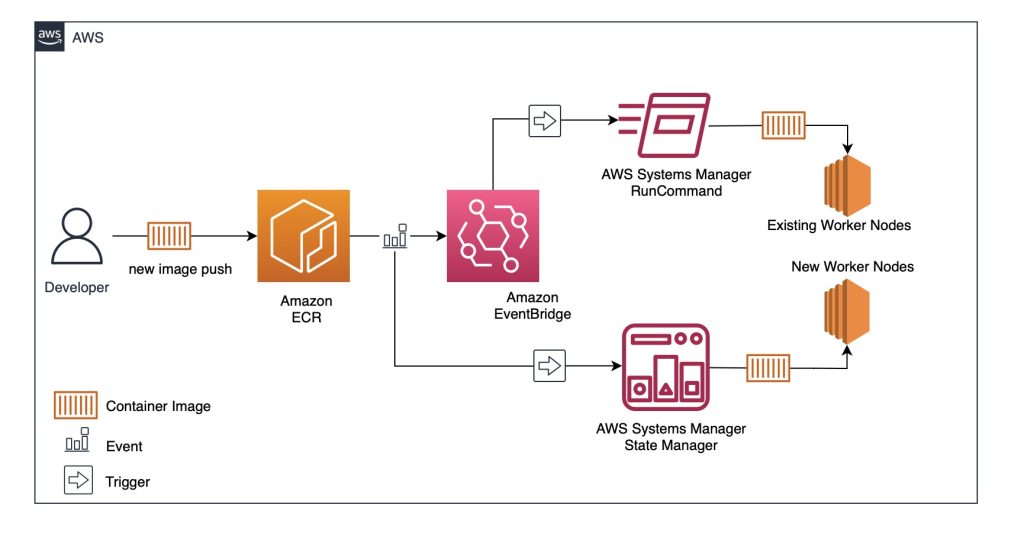
The process for implementing this solution is as follows:
- The first step is to identify an Amazon ECR repository to fetch the container image.
- Next, when a container image gets pushed to Amazon ECR, an event based rule is triggered by Amazon EventBridge, which starts an AWS Systems Manager (SSM) automation to prefetch container images from Amazon ECR.
- Whenever a new worker node gets added to your cluster, based on the tags on the worker node, AWS Systems Manager State Manager association prefetches container images to new nodes.
Prerequisites
To run this solution, you must have the following prerequisites:
- AWS CLI version 2.10 or higher to interact with AWS services
- eksctl for creating and managing your Amazon EKS cluster
- kubectl for running kubectl commands on your Amazon EKS cluster
- envsubst for environment variables substitution (envsubst is included in gettext package)
- jq for command-line JSON processing
Walkthrough
The source code for this post is available in AWS-Samples on GitHub.
Let’s start by setting environment variables:
Create an Amazon EKS cluster:
Create Amazon Elastic Container Registry repository to store the sample application’s image:
Create a large container image:
Create an AWS Identity and Access Management (AWS IAM) role for Amazon EventBridge:
Attach a policy to the role that allows Amazon EventBridge to run commands on cluster’s worker nodes using AWS Systems Manager:
Create an Amazon EventBridge rule that looks for push events on the Amazon ECR repository:
Attach System Manager Run command as the target. Whenever we push a new image to the Amazon ECR repository, Amazon EventBridge triggers SSM run command to pull the new image on worker nodes.
Create an AWS Systems Manager State Manager association to prefetch sample application’s images on new worker nodes:
Note: The status of AWS SSM State Manager association will be in “failed” state until the first run.
Validation
We have laid the groundwork for the automation. Let’s validate the setup by pushing a new image to the repository. We’ll know the automation works if worker nodes pull the image before we schedule a Pod.
Test image prefetch on existing nodes
Log into the Amazon ECR repository:
Push the container image we created earlier:
As we push the image to Amazon ECR, it publishes an event to Amazon EventBridge. As a result, the rule we previously created in Amazon EventBridge triggers the AWS Systems Manager Run command.
You can monitor rule invocation in the AWS Management Console. Navigate to Amazon EventBridge in AWS Management Console and switch to the Monitoring tab for the event. If you don’t see FailedInvocations, then EventBridge has delivered the event to AWS Systems Manager successfully.

Note: It might take 3 to 5 mins for the data points to be published in the Monitoring graphs.
Verify if AWS Systems Manager Run command is triggered by Amazon EventBridge. Run the below command to see the invocations. Look for DocumentName, which should be AWS-RunShellScript, RequestedDateTime to identify corresponding run, and then status to make sure if the Run command executed Successfully or not.
Verify that the worker node has pulled the image. We’ll SSM agent to log into the worker node:
Note: If you receive Cannot perform start session: EOF error, try to rerun the command. This error is caused by an issue with Amazon Systems Manager SSM agent.
Test image prefetch on new nodes
We have verified that existing nodes are pulling new image as soon as a new version gets pushed. Let’s validate that the automation also pulls the latest version of image (not to be confused with the $latest tag) on any new nodes that join the cluster.
To test the process, let’s create a new node by increasing the size of the existing node group:
Once the new node becomes available, verify if the image has been cached on it:
Container startup improvement
By prefetching the image, we have reduced container startup time significantly. When a node doesn’t have a cached copy of the image, it must download the entire image before the container can start.
As an example, it takes sixty seconds to start a container using the 1 GB test image we’ve used in this post. The same container starts in one second when the node has a cached copy of the image.

Design considerations
The solution is design to cache images but it doesn’t clean old images. It relies on Kubelet’s garbage collection to remove unused images. The kubelet automatically removes unused images when the root volume usage exceeds 85%.
Prefetching images can fill node’s local storage. Limit the number of images you cache to avoid running into storage capacity issues.
This solution also assumes that the image pull occurs before a Pod gets scheduled on the node. If the Pod is scheduled before the image is cached, then the node must pull the image from the container registry, thus rendering this technique ineffective. Customers can use overprovisioning to ensure that the automation runs before a Pod gets scheduled on new nodes.
Cleaning up
You continue to incur cost until deleting the infrastructure that you created for this post. Use the commands below to delete resources created during this post:
Lazy loading container images
Lazy loading is an approach where data is downloaded from the registry in parallel with the application startup. Seekable OCI (SOCI) is a technology open sourced by AWS that enables containers to launch faster by lazily loading the container image.
To use lazy loading, customers must build a SOCI index of the container image, which adds an additional step to the container build process. Customers that have control over their build process can also consider using SOCI to improve container start up time.
Conclusion
In this post, we showed you how to speed up Pod startup by caching images on nodes. By utilizing AWS Systems Manager SSM to prefetch container images on worker nodes in your Amazon EKS Cluster, you can significantly reduce Pod startup times, even for large images, down to a few seconds. This technique can greatly benefit customers running workloads such as machine learning, simulation, data analytics, and code builds, improving container startup performance and overall workload efficiency. By eliminating the need for additional management of infrastructure or Kubernetes resources, this approach offers a cost-efficient and serverless solution for addressing the slow container startup problem in Kubernetes-based environments.