Containers
Unlocking next-generation AI performance with Dynamic Resource Allocation on Amazon EKS and Amazon EC2 P6e-GB200
The rapid evolution of agentic AI and large language models (LLMs), particularly reasoning models, has created unprecedented demand for computational resources. Today’s most advanced AI models span hundreds of billions to trillions of parameters and necessitate massive computational power, extensive memory footprints, and ultra-fast interconnects to function efficiently. Organizations developing applications for natural language processing, scientific simulations, 3D content generation, and multimodal inference need infrastructure that can scale from today’s billion-parameter models to tomorrow’s trillion-parameter frontiers while maintaining performance.
In this post, we explore how the new Amazon Elastic Compute Cloud (Amazon EC2) P6e-GB200 UltraServers are transforming distributed AI workload through seamless Kubernetes integration. Amazon Web Services (AWS) introduced the EC2 P6e-GB200 UltraServers to meet the growing demand for large-scale AI model training and inference. They represent a significant architectural breakthrough for distributed AI workloads. Furthermore, the EC2 P6e-GB200 UltraServer launch includes support for Amazon Elastic Kubernetes Service (Amazon EKS), providing a Kubernetes-native environment for deploying and scaling from hundreds-of-billions to trillion-parameter models as the AI landscape continues to evolve.
Note: For current best practices and updated instructions on deploying Amazon EC2 P6e-GB200 instances with Amazon EKS, please refer to the AWS documentation.
The power behind P6e-GB200: NVIDIA GB200 Grace Blackwell architecture
At the heart of EC2 P6e-GB200 UltraServers is the NVIDIA GB200 Grace Blackwell Superchip, which integrates two NVIDIA Blackwell GPUs with a NVIDIA Grace CPU. Furthermore, it provides NVLink-Chip-to-Chip (C2C) connection between these components, delivering 900 GB/s of bidirectional bandwidth, which is substantially faster than traditional PCIe interfaces.
When deployed at rack scale, EC2 P6e-GB200 UltraServers participate in NVIDIA’s GB200 NVL72 architecture, creating memory-coherent domains of up to 72 GPUs. Fifth-generation NVLink technology enables GPU-to-GPU communication across discrete servers within the same domain at up to 1.8 TB/s per GPU. Critical to this performance is Elastic Fabric Adapter (EFAv4) networking, which delivers up to 28.8 Tbps of total network bandwidth per UltraServer. EFA couples with NVIDIA GPUDirect RDMA to enable low-latency GPU-to-GPU communication between servers with operating system bypass. This makes sure that the distributed GPU fabric operates with near-local memory performance across nodes. Go to the linked EC2 post to learn more about EC2 P6e-GB200 features details.
This represents a significant evolution from earlier EC2 P6-B200 UltraServers, which provided up to 8 B200 Blackwell GPUs on x86 platforms using PCIe. P6e-GB200 elevates the architecture by providing truly unified memory across racks, a critical requirement for efficiently training and running trillion-parameter models.

Figure 1: Amazon EC2 P6e-GB200 UltraServers
Understanding EC2 P6e-GB200 UltraServer architecture
An EC2 P6e-GB200 UltraServer is not a single EC2 instance. Instead, it consists of multiple interconnected EC2 instances working together as a cohesive unit:
- u-p6e-gb200x36: Contains 36 GPUs distributed across multiple EC2 instances
- u-p6e-gb200x72: Contains 72 GPUs distributed across multiple EC2 instances
Each individual P6e-GB200 EC2 instance provides 4 NVIDIA Blackwell GPUs. Therefore:
- A u-p6e-gb200x36 UltraServer consists of 9 interconnected EC2 instances (9 × 4 = 36 GPUs)
- A u-p6e-gb200x72 UltraServer consists of 18 interconnected EC2 instances (18 × 4 = 72 GPUs)
In Amazon EKS, each EC2 instance appears as a separate Kubernetes node, but Amazon EKS understands the topology and treats them as part of the same UltraServer through topology-aware routing.
Integrating P6e-GB200 UltraServers with Amazon EKS
The Amazon EKS team worked closely with NVIDIA from the beginning to set requirements for integrating P6e-GB200 instances with EKS worker nodes and Kubernetes control plane. Using those specifications we built out our first NVIDIA-flavored ARM64 Amazon Linux 2023 Amazon Machine Images (AMIs). We also prepackaged binaries for Internode Memory Exchange/Management Service (IMEX) and shipping the necessary NVIDIA Driver version. Furthermore, Amazon EKS accelerated making Dynamic Resource Allocation (DRA) generally available to users starting in Amazon EKS Kubernetes version 1.33, where the feature gate is still beta in upstream Kubernetes.
The instances have been tested with NVLink over IMEX as well as through EFA, allowing optimal data flow within and between UltraServers. Our internal testing uses the NVIDIA Collective Communications Library (NCCL), which abstracts the transport-level decision making away from the application layer.
The challenge: running distributed AI workloads on Kubernetes
Deploying tightly coupled GPU workloads across multiple nodes has traditionally presented unique challenges for Kubernetes. Traditional Kubernetes resource allocation assumes hardware is local to each node, making it difficult to effectively manage cross-node GPU resources and memory-coherent interconnects. This is common for large-scale training workloads such as training LLMs or computer vision models that need many GPUs working in parallel.
Consider the traditional approach of requesting GPUs in a Kubernetes pod:
This static approach works well for local GPUs but fails to capture the sophisticated topology of memory-coherent NVLink domains spanning multiple nodes. The existing mechanisms in Kubernetes cannot express specific interconnect patterns or GPU-to-GPU communication channels needed by distributed training frameworks.
The solution: Kubernetes DRA and IMEX
To address these challenges, Kubernetes introduced DRA, a new framework that extends Kubernetes beyond traditional CPU and memory resources to handle complex, specialized hardware topologies. Amazon EKS enabled DRA with Kubernetes version 1.33, providing sophisticated GPU topology management capabilities that were previously impossible with traditional Kubernetes GPU resource allocation.
How DRA solves traditional GPU allocation problems
Unlike the static resource model (for example nvidia.com/gpu: 2) where you request a fixed number of GPUs without topology awareness, DRA enables applications to describe their resource requirements declaratively through ComputeDomain and ResourceClaims. This fundamental shift allows Kubernetes to make intelligent decisions about resource allocation based on actual hardware topology, considering NVLink connectivity, memory bandwidth, and physical proximity automatically. Most importantly, this abstracts away complex manual configurations such as IMEX service setup, NVLink partition management, and low-level hardware initialization that would otherwise need deep GPU cluster expertise.
NVIDIA DRA Driver serves as the critical integration later between the Kubernetes DRA API and the underlying hardware. This consists of two specialized kubelet plugins: the gpu-kubelet-plugin for advanced GPU allocation and the compute-domain-kubelet-plugin that orchestrates IMEX primitives automatically. When you create a ComputeDomain requesting 36 GPUs across 9 EC2 instances (each instance containing 4 Blackwell GPUs), or 72 GPUs across 18 EC2 instances for a full UltraServer, the system automatically deploys the IMEX daemons, establishes gRPC communication between nodes, creates memory-coherent domains with cross-node mappings, and provisions device files inside containers.
Topology-aware scheduling and memory coherence
As a node joins an EKS cluster, the cluster control plane pulls topology information associated with the instance through EC2 topology API and applies labels to the Kubernetes node resources as they join the cluster. Each P6e-GB200 node in an EKS cluster is automatically labeled with its capacity block type (eks.amazonaws.com/capacityType=CAPACITY_BLOCK and eks.amazonaws.com/nodegroup=cbr-1234xyz) and detailed network topology labels (topology.k8s.aws/network-node-layer-1 through network-node-layer-4). These indicate its physical location within the UltraServer network fabric. Moreover, when GPU Feature Discovery (GFD) is enabled in the NVIDIA GPU Operator, it applies clique labels (nvidia.com/gpu.clique) to each node that identify which GPUs belong to the same NVLink domain. These topology dimensions enable you to design topology-aware scheduling for distributed workloads on and across your UltraServer node groups.
IMEX is a critical capability of NVLink-enabled systems such as GB200 that enables GPUs across different nodes to directly access each other’s memory using NVLink. When an IMEX channel is allocated with Kubernetes and DRA through a ComputeDomain, it appears inside containers as a device file (for example /dev/nvidia-caps-imex-channels/channel0). This allows CUDA applications to operate as if all GPUs reside on the same board.
This capability is particularly important for distributed training frameworks such as MPI and NCCL. These can now achieve near-bare-metal performance across node boundaries without custom configurations or code changes. NVLink 5.0 (NVIDIA’s fifth-generation interconnect) provides the underlying bandwidth to power these channels, with 1.8 TB/s bidirectional throughput per GPU. This allows truly memory-coherent compute domains across racks, forming the foundation for real-time, multi-node AI systems.
In the NVL72 architecture, up to 72 GPUs can be connected in a single memory-coherent NVLink domain. The GPUs are organized into cliques based on their physical connectivity through NVSwitches, with all GPUs on a single node guaranteed to be in the same clique and sharing the same Cluster UUID. When GFD is enabled, it labels each node with nvidia.com/gpu.clique containing the NVL Domain ID and Clique ID (for example cluster-abc.0), enabling users to design topology-aware scheduling using node affinity rules. When scheduling your training job across the 9 instance u-p6e-gb200x36 UltraServer or 18 instance u-p6e-gb200x72 UltraServer, the kube-scheduler using properly configured affinity rules makes sure that all nodes belong to the same NVLink domain for maximum bandwidth.
Although NVLink provides ultra-high bandwidth within the same physical domain, EFA networking enables the low-latency, high-throughput communication needed between different UltraServers. EFA’s RDMA capabilities with GPUDirect allow GPUs to communicate directly across nodes without CPU involvement, creating a seamless hybrid architecture where intra-UltraServer communication flows through NVLink while inter-UltraServer communication uses EFA. This makes P6e-GB200 suitable for distributed training of massive models that can scale from single-rack deployments to multi-rack supercomputing clusters while maintaining optimal performance characteristics at each scale.
Workload scheduling flow with DRA
This flowchart demonstrates how Kubernetes DRA integrates with NVIDIA GB200 IMEX technology to deploy distributed AI training workloads across multiple nodes. When a pod requests 8 GPUs for distributed training with properly configured clique affinity rules, the system orchestrates deployment through a coordinated flow. Users specify node affinity targeting specific cliques (nvidia.com/gpu.clique), the kube-scheduler places pods based on these affinity constraints, DRA components handle resource management and cross-node coordination, NVIDIA drivers manage GPU allocation and IMEX orchestration, and the IMEX service makes sure of cross-node memory coherence through gRPC communication. The result is a seamless deployment across two nodes (4 GPUs each) within the same NVLink domain, enabling high-bandwidth, low-latency communication that is essential for large-scale AI training workloads.
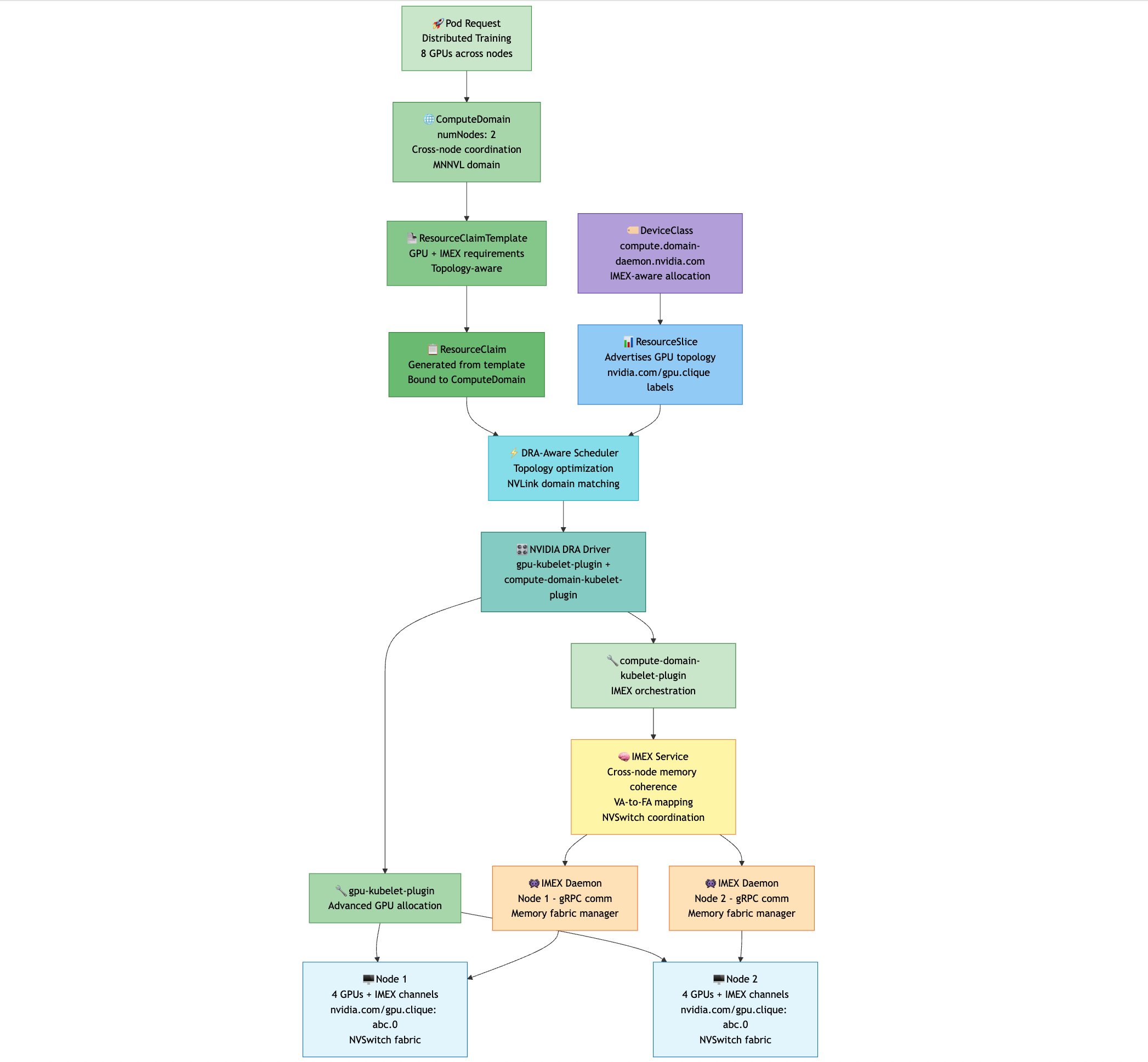
How to use p6e-GB200 with Kubernetes DRA with Amazon EKS
In the following sections we walk through setting up an EKS cluster with EC2 P6e-GB200 UltraServers to use these capabilities.
Prerequisites
Before starting, make sure that you have the following tools and access. Reference the Amazon EKS User Guide for instructions.
- AWS Command Line Interface (AWS CLI) installed
- eksctl installed (version supporting EKS 1.33)
- kubectl installed
- helm installed
- Access to EC2 Capacity Blocks for P6e-GB200 instances
Step 1: Reserve P6e-GB200 UltraServer capacity
Important: P6e-GB200 UltraServers are available only through EC2 Capacity Blocks for machine learning (ML). You must reserve the UltraServer (not individual instances) before creating your EKS cluster.
In the AWS console:
- Navigate to EC2 Console > Capacity Reservations > Capacity Blocks
- Choose the UltraServers tab (not Instances)
- Choose either:
- u-p6e-gb200x36 (36 GPUs across 9 instances)
- u-p6e-gb200x72 (72 GPUs across 18 instances)
- Complete the reservation for your desired time period
| Note: For current best practices and updated instructions on deploying Amazon EC2 P6e-GB200 instances with Amazon EKS, please refer to the AWS documentation. |
Step 2: Create the EKS cluster configuration file
Create a file named cluster-config.yaml with the following content:
Step 3: Deploy the EKS cluster
This deployment creates an EKS 1.33 cluster with all 9 p6e-gb200.36xlarge instances from your UltraServer reservation, with EFA networking enabled for optimal GPU-to-GPU communication.
Step 4: Deploy the NVIDIA GPU Operator
The NVIDIA GPU Operator is essential for GB200 instances because it provides comprehensive GPU lifecycle management including runtime configuration and advanced features such as Multi-Instance GPU (MIG) support. For GB200’s complex NVLink topology spanning multiple nodes, the GPU Operator dynamically manages GPU resources, configures MIG profiles, and handles the sophisticated interconnect relationships that static device plugins cannot manage.
Step 5: Install the NVIDIA DRA Driver
The NVIDIA DRA Driver is essential for P6e-GB200 UltraServers because it provides capabilities that go beyond traditional GPU device plugins. Although the standard NVIDIA Device Plugin exposes individual GPUs as countable resources (nvidia.com/gpu: 2), the DRA Driver enables two critical capabilities needed for GB200 systems:
1. ComputeDomain management: The DRA Driver manages ComputeDomains, which are abstractions for Multi-Node NVLink (MNNVL) deployments. When you create a ComputeDomain resource, the DRA Driver automatically:
- Orchestrates IMEX primitives (daemons, domains, channels) across multiple nodes
- Establishes the gRPC communication needed for cross-node GPU memory sharing
- Manages the ephemeral lifecycle of IMEX channels tied to workload lifecycles
2. Advanced GPU allocation: Beyond GPU counting, the DRA Driver enables dynamic allocation of GPU configurations, MIG devices, and topology-aware scheduling that understands the NVLink relationships between GPUs across nodes.
The DRA Driver consists of two kubelet plugins:
- gpu-kubelet-plugin: For advanced GPU allocation features
- compute-domain-kubelet-plugin: For ComputeDomain orchestration
Create a Helm values.yaml file to deploy NVIDIA DRA Driver:
Then install the NVIDIA DRA driver:
After installation, the DRA Driver creates DeviceClass resources that enable Kubernetes to understand and allocate ComputeDomain resources. This makes the advanced topology management possible for distributed AI workloads on EC2 P6e-GB200 UltraServers.
Step 6: Verify DRA resources
Confirm the DRA resources are available:
Validating IMEX channel allocation
With the GPU Operator and DRA driver configured, you can now create IMEX channels that enable direct memory access between GPUs across different nodes. The following example demonstrates how a ComputeDomain resource automatically provisions the necessary IMEX infrastructure:
Now, you create a test to validate IMEX channel allocation. Create a file named imex-channel-injection.yaml:
This example creates a ComputeDomain resource and references it from a pod. The ComputeDomain controller automatically creates the necessary ResourceClaimTemplate, which the pod uses to access an IMEX channel. Behind the scenes, this triggers the deployment of IMEX daemons on the chosen nodes, creating one-off IMEX domains dynamically rather than needing pre-configured static domains.
Apply and validate
Apply the imex-channel-injection.yaml to your cluster and validate it is working as expected.
The logs show IMEX version 570.133.20 initializing and establishing gRPC connections between nodes, confirming that the memory-coherent domain is operational. This demonstrates that GPU memory from different nodes in your UltraServer can now be accessed directly through NVLink. Furthermore, this enables unprecedented performance for distributed AI workloads.
Multi-node IMEX communication in action
To demonstrate how NVIDIA DRA driver orchestrates cross-node GPU communication, the following sections walk through deploying a multi-node MPI benchmark that uses IMEX channels for high-bandwidth GPU-to-GPU memory transfers across EC2 P6e-GB200 UltraServer nodes.
Deploy the multi-node MPI Job
When you apply this configuration, the following orchestrated sequence occurs:kubectl apply -f nvbandwidth-test-job.yaml
- ComputeDomain creation and node selection: The DRA driver immediately begins orchestrating the multi-node setup:
- Identifies 2 nodes with available GB200 GPUs
- Verifies nodes belong to the same NVLink domain
- Creates the ComputeDomain resource
- IMEX domain establishment: DRA automatically:
- Deploys IMEX daemon pods on both selected nodes
- Configures cross-node gRPC communication channels
- Establishes shared memory mappings between GPUs
Node topology update: After ComputeDomain creation, both nodes now share the same clique ID:
ComputeDomain status: The ComputeDomain shows successful cross-node coordination:
Cross-node IMEX communication in action
IMEX daemon coordination: Behind the scenes, IMEX daemons on both nodes establish communication:
IMEX version 570.133.20 is running:
Cross-node GPU memory access: The benchmark results demonstrate true cross-node GPU communication:
The bandwidth test results reveal the true power of IMEX-enabled cross-node communication, where GPUs 0-3 on the first node and GPUs 4-7 on the second node achieve consistent ~821 GB/s bandwidth regardless of physical location. This remarkable consistency demonstrates that IMEX has created a unified memory domain where cross-node GPU memory access performs identically to intra-node access, with the NVLink fabric operating at full capacity and delivering 46 TB/s total aggregate bandwidth across the entire domain. Most impressively, the MPI application sees all 8 GPUs as if they were on a single node, with CUDA applications able to directly access remote GPU memory through the IMEX channel device file without any special cross-node communication code.
This example demonstrates how DRA transforms multi-node GPU clusters into unified computing resources, enabling LLM training to span multiple UltraServer nodes with native GPU memory access while maintaining optimal performance. All 72 GPUs in a u-p6e-gb200x72 UltraServer appear as one unified memory space to applications, with Kubernetes handling all complex IMEX orchestration automatically so that data scientists can focus on their models rather than infrastructure complexity. The result is seamless scaling across multiple nodes while maintaining the performance characteristics of a single, massive GPU system.
Conclusion
Amazon EC2 P6e-GB200 UltraServers on Amazon EKS represent a major step forward for users looking to train and deploy trillion-parameter AI models at scale. Combining the power of NVIDIA’s GB200 Grace Blackwell Superchip with NVLink, supported by Amazon EKS, DRA, and NVIDIA tooling, AWS has made exascale AI computing accessible through familiar container orchestration patterns.The integration of IMEX channels and NVLink enables memory-coherent GPU clusters that span nodes and racks, breaking through the traditional limitations of node-local GPU computing. This architectural advancement unlocks new possibilities for training foundation models across trillions of parameters, running multimodal AI with real-time performance requirements, and deploying complex inference pipelines with sub-second latency requirements.
To get started with DRA on Amazon EKS, refer to the Amazon EKS AI/ML documentation for comprehensive guidance, and explore the AI on EKS project, which provides hands-on DRA examples you can test and implement in your own environment.
SECURITY NOTE: The configurations demonstrated in this post are basic examples intended to illustrate core functionality. In production environments, you should implement more security controls.
Please contact your AWS account teams to know more about using P6e-GB200 on Amazon EKS.
About the authors
 Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives.
Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives.
 Chris Splinter is a Principal Product Manager on the Amazon EKS team, focused on helping customers run AI workloads with Kubernetes.
Chris Splinter is a Principal Product Manager on the Amazon EKS team, focused on helping customers run AI workloads with Kubernetes.
 Nick Baker is a Software Development Engineer on the Amazon EKS Node Runtime Team. He is focused on adding support for accelerated workloads and improving data-plane stability on EKS.
Nick Baker is a Software Development Engineer on the Amazon EKS Node Runtime Team. He is focused on adding support for accelerated workloads and improving data-plane stability on EKS.