AWS Database Blog
How to use Amazon Aurora to drive 3x latency improvement for end users
Born on AWS
InfoScout was born on AWS, being along for the journey since its inception in 2011. It all started with a single Amazon EC2 instance to collect receipts uploaded from friends and family. Seven years later, we now manage 150+ AWS instances to support our mobile applications, data pipelines, machine learning models, and our SaaS analytics platform. This post provides some detailed insights into our growing infrastructure and database migration challenges.
Our business is simple. We have a portfolio of mobile apps that enable everyday consumers to capture pictures of their shopping receipts and upload them to the cloud. We analyze this data and then provide deep insights to brands, retailers, agencies, and consumer packaged goods (CPG) companies on their shoppers. This consumer-centric approach to gathering data at a large scale enables brands to finally answer the “why” behind so many questions. “Why did sales fall 5% in my category?” “What consumer shifts in the category are driving sales to my brand?” “What segment of consumers is shifting their spend to online?” We now capture 1 in 500 purchases in the US, resulting in a stream of 300,000 receipt images per day.
To power our entire infrastructure and applications on AWS, we have been using Amazon EC2, Amazon RDS, Amazon S3, Amazon VPC, and Route 53 heavily. We started off with a single VPC in northern California in 2011, but by 2016 we expand our footprint on AWS in order to keep up with our growing data pipeline and customer demands. We were interested in Amazon Aurora and AWS Lambda, but they weren’t available in our region, so step one was migrating our footprint to a newer location in Oregon.
In November and December 2016, we migrated more than 100 servers, including multiple databases. Phase 2 of our growth on AWS had begun.
Growing pains
Like many startups, we experienced scaling challenges, and our top priority was to improve our database throughput and performance. Even before the move to Oregon, we were beginning to experience database performance issues as our business grew.
InfoScout’s primary transactional database was configured on an Amazon RDS for MySQL instance. It served as our consumer database backend, storing all of our mobile user data, survey data, and receipt data. Our configuration included a single master database and two read replicas, used both for high availability and ETL. We had been scaling the instance vertically as the database grew, eventually upgrading to the largest instance size supported by Amazon RDS for MySQL at the time. This approach worked in the beginning, but as our database grew to several TBs in size we saw two major issues crop-up during periods of high traffic.
First, overall performance in query execution time was suffering. Under peak load, we would receive too many concurrent requests and our queue depth on the Amazon RDS instance would back up considerably. We’d see a queue depth of 50, 100, or even 125, indicating an I/O-level operation backlog. This caused reads to slow down, pages to time out, and jobs to fail. Second, storage was becoming an issue. Amazon RDS for MySQL had a max storage size of 6 TB at the time (it now supports up to 16 TB), and our database was already 5 TB.
Because of these performance and storage issues, we were spending precious time and resources to tend to MySQL. Whenever there were issues during high traffic periods, we would have to shut down other services that were not essential. This would lighten the load on the database. Constant Amazon CloudWatch alerts impacted our other responsibilities.
We evaluated a number of possibilities to manage the problem: Sharding our database cluster, ripping it out into microservices, archiving older data, or even migrating back to MySQL on Amazon EC2. However, these options seemed too complex and unsustainable given our growth rate. After a few conversations with our account managers and AWS solutions architects, we began investigating Aurora with MySQL-compatibility as a new destination for our primary database.
We were apprehensive about Aurora at first. It was relatively new, its proprietary nature was not in line with our other architectural components, and we had doubts it could really plug-and-play with a MySQL database. However, we were lured by the scalability and feature sets. Lower cost, faster performance, short replication lag, and its 64-TB maximum storage meant that there was no need to shard our database anytime in the near future.
Migrating to Aurora
Before making the jump to Aurora for our production database, we had to resolve some additional compatibility checks, as well as test and tune a staging environment.
Out of the approximately 250 tables on our mobile backend, the majority used the MySQL InnoDB storage engine. A dozen or so were on the older MyISAM storage engine (to support legacy FULLTEXT search queries). Aurora is compatible with InnoDB but not MyISAM, which meant we had to migrate our MyISAM tables to InnoDB immediately – a straightforward task. After this was done, we migrated our entire staging environment to Aurora and retired our Amazon RDS for MySQL staging environment.
For the next 2-3 weeks, we tested, tuned, and monitored performance of the staging environment on Aurora, and things were looking good. A staging environment for internal testing obviously doesn’t get the traffic that a production environment gets. However, from a logical and SQL standpoint, everything was working end-to-end. Calls to the Aurora cluster were working as expected, and data was flowing smoothly. We now had high confidence in Aurora with MySQL compatibility.
After the staging environment was given the green light in the Summer of 2017, we made the checklist for migration. It looked something like:
- Spin up two Aurora read replicas from our Amazon RDS for MySQL Master DB
- Wait for the Aurora replicas to catch up, which happened quickly
- Turn off all consumer traffic and our asynchronous Python Celery queue
- Change the MySQL master password to confirm that no rogue process is writing to the lame duck MySQL DB
- Validate Aurora tables are caught up and no writes are hitting MySQL master
- Promote one Aurora DB to the new master DB
- Update Route 53 DNS record to point DB endpoint to new Aurora DB
- Boot backup consumer app, Celery queue, and other services
We had many CloudWatch dashboards monitoring queries, read time and write time, throughput, and replication lag. The Aurora cluster started to heat up, and all CloudWatch metrics looked good. The migration looked to be a success, although it was the middle of the night with no traffic. We recognized there was still a chance we’d receive an alert after we signed off on the migration. However, when we checked in next morning, things were running smoothly – we could tell right away that Aurora was highly performant.
Results
Below are graphs that highlight execution time and latency before and after the cutover – you can see the immediate improvement in performance.
We are big fans of CloudWatch and have about two dozen metrics defined to monitor the performance of our large asynchronous farm of Celery workers. After migrating to Aurora, we noticed a 10x reduction time for one of our critical steps in the receipt engine state machine. This task is responsible for image duplication and validation of recent receipt submissions. The following graph shows the run time of a critical asynchronous job in the receipt pipeline. You can see 10-fold reduction in execution time from 4 seconds to 400 ms.
In addition to AWS monitoring tools, we use production-grade services like New Relic for deep performance monitoring. We pulled those reports and saw a 3-fold improvement in response times out of the gate! When we were on Amazon RDS for MySQL, standard network calls that mobile clients made to our backend would take 600 ms to complete, nearly all of which was spent within the MySQL query. After deploying on Aurora, this latency was reduced to below 200 ms. After seeing these initial metrics, our infrastructure team was confident that we’d found a new home for our 6-TB transactional data cluster. The following graph shows the latency before and after migration. You can see an immediate improvement in performance.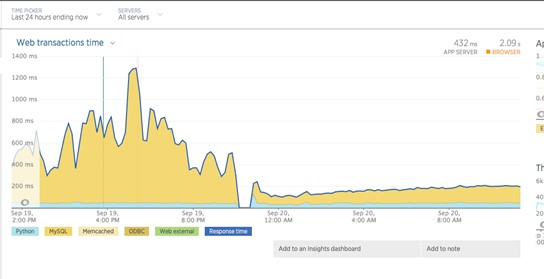
A database to grow on
When we were evaluating our options for migrating or rebuilding our database environment, we considered a number of factors. Ultimately, we did not want to go the route of sharding or building our own cluster because of the operational overhead and infrastructure management involved. We were concerned that the time spent on database administration and operations meant we could not be working on feature development, engineering, and helping the company grow. This would ultimately hurt our business velocity.
Although Aurora seemed like the most sensible option, the decision to migrate wasn’t made in a vacuum. We had a collective team conversation about whether a migration to Aurora made the most sense. MySQL is stable and robust, and it has been around for decades – we’re still believers in the technology. However, we had a large database with more than 20,000 queries-per-minute coming in, and MySQL alone wasn’t able to absorb the stress.
If you’re thinking about a migration for any reason, don’t just chase the hottest technology. Evaluate and consider all of your options, as a team. Stress test your existing production environment and carefully document the issues. And test, test, test your new staging environment against a checklist of requirements. This approach paid off for us. We have already grown since migrating to Aurora, and our new database has been running steadily with high performance. We’re happy with Aurora as our new database engine and confident it is able to scale with our business.
Speaking of scale, in the coming weeks we expect to celebrate receipt number 500 million! Kudos to the team at AWS for making it all possible.

InfoScout application architecture
About the Author
 Dana Ford is a senior engineering director at InfoScout who leads product and engineering for their consumer mobile apps and platform teams. He has been with the company for the past 4 years and helped scale their large AWS footprint to meet growing customer needs.
Dana Ford is a senior engineering director at InfoScout who leads product and engineering for their consumer mobile apps and platform teams. He has been with the company for the past 4 years and helped scale their large AWS footprint to meet growing customer needs.
 Doug Flora is a senior product marketing manager for Amazon Relational Database Service (RDS) at Amazon Web Services.
Doug Flora is a senior product marketing manager for Amazon Relational Database Service (RDS) at Amazon Web Services.