AWS Database Blog
Category: Amazon Neptune

Build a semantic ontology to power AI assistants on AWS – Part 1
In this post, we show you how to build a semantic ontology that helps your AI assistants navigate enterprise data efficiently. You’ll learn how to structure a property graph store for data relationships, set up vector indexing for semantic search, and implement an automated fact-learning layer that improves use. This bottom-up approach grounds your ontology in the data that exists, building abstractions from observed patterns rather than theoretical models.

Building Financial Hierarchies with Amazon Neptune for Treasury Operations
In this post, we show how Amazon’s Finance Technology (FinTech) team uses Amazon Neptune to model complex corporate treasury structures as a property graph. These structures include the legal entity relationships, intercompany agreements, and bank account associations that govern payment routing and cash management.

Improving generative AI accuracy with vector and graph search hybrid queries
In this post, we discuss the differences between vector search and graph search, how to combine the two for hybrid querying, and use cases that benefit from hybrid querying.

Exploring type-safe .NET development for Amazon Neptune with Gremlinq
In this post, we walk through how Gremlinq works, demonstrate its capabilities, show you how to set up a Neptune project with the provided templates, and help you understand where this approach might fit in your development context.

AWS purpose-built database recovery: A guide to business continuity and disaster recovery strategies
This post addresses recovery challenges in multi-database architectures, focusing on both low-consistency and mission-critical scenarios. We explore practical strategies for implementing resilient recovery mechanisms across Amazon DynamoDB, Amazon Aurora, Amazon Neptune, Amazon OpenSearch Service, and other AWS database services.
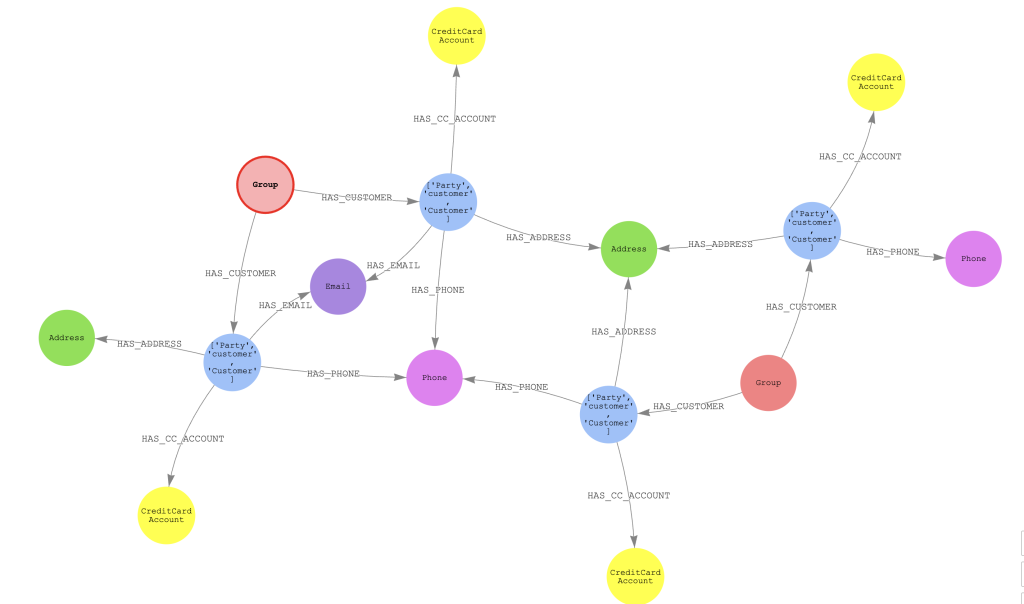
Build fraud detection systems using AWS Entity Resolution and Amazon Neptune Analytics
In this post, we show how you can use graph algorithms to analyze the results of AWS Entity Resolution and related transactions for the CNP use case. We use several AWS services, including Neptune Analytics, AWS Entity Resolution, Amazon SageMaker notebooks, and Amazon S3.
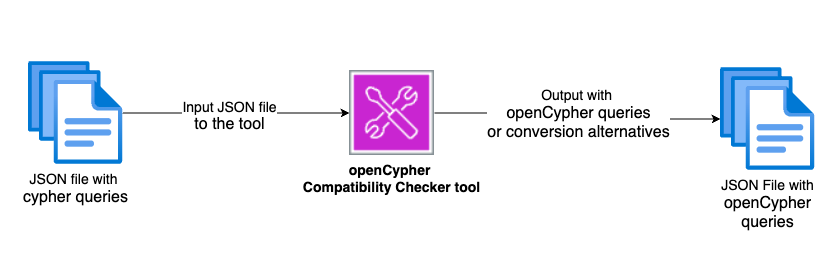
Validate Neo4j Cypher queries for Amazon Neptune migration
In this post, we show you how to validate Neo4j Cypher queries before migrating to Neptune using the openCypher Compatibility Checker tool. You can use this tool to identify compatibility issues early in your migration process, reducing migration time and effort.
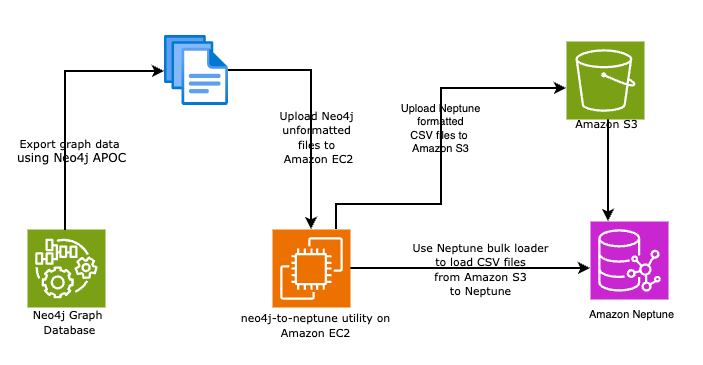
Automate your Neo4j to Amazon Neptune migration using the neo4j-to-neptune utility
In this post, we walk you through two methods to automate your Neo4j database to Neptune using the neo4j-to-neptune utility. This tool offers a fully automated end-to-end process in addition to a step-by-step manual process.

Build and explore Knowledge Graphs faster with Amazon Neptune using Graph.Build and G.V() – Part 2
This is a guest blog by Arthur Bigeard, Founder at gdotv, in partnership with Charles Ivie, Sr Graph Architect at AWS. G.V() is a graph database IDE available for Desktop or on AWS Marketplace, offering extensive graph visualization and querying capabilities for Amazon Neptune and Neptune Analytics. In Part 1 of this series, we demonstrated […]

Build and explore Knowledge Graphs faster with Amazon Neptune using Graph.Build and G.V() – Part 1
This is a guest blog post by Richard Loveday, Head of Product at Graph.Build, in partnership with Charles Ivie, Graph Architect at AWS. The Graph.Build platform is a dedicated, no-code graph model design studio and build factory, available on AWS Marketplace. Knowledge graphs have been widely adopted by organizations, powering use cases such as social […]