AWS Database Blog
Category: Amazon DynamoDB

Similarweb’s migration from HBase to Amazon DynamoDB
Managing massive data volumes at scale presents significant operational challenges. At Similarweb we faced these challenges with Apache HBase and found a solution in Amazon DynamoDB. Similarweb is a digital intelligence platform that provides AI-powered insights into website traffic, app usage, and market trends to help businesses benchmark competitors and optimize growth strategies. We faced growing scalability and operational complexity issues with our existing Apache HBase infrastructure, which prompted us to explore more flexible and efficient alternatives. This post walks you through our journey migrating our data storage from Apache HBase to DynamoDB. We discuss the technical challenges, migration approach, data modeling strategies, cost optimization techniques, and key benefits achieved along the way.

Best practices for Amazon DynamoDB Global Tables – Part 3: Validating regional resilience with AWS Fault Injection Service
In this post, we show you how to use AWS Fault Injection Service (AWS FIS) to validate that your application handles regional disruptions the way you expect, by running controlled experiments against your DynamoDB global tables. We cover both multi-Region strong consistency (MRSC) and multi-Region eventually consistent (MREC) global tables, because AWS FIS works differently with each.

Best practices for Amazon DynamoDB Global Tables – Part 2: Failover strategies
In this post we cover the two primary failover strategies for DynamoDB global tables, the tradeoffs between them, and the operational considerations that you must be aware of during and after a failover.

Best practices for Amazon DynamoDB Global Tables – Part 1: Operational readiness
This is Part 1 of a series on best practices for DynamoDB global tables. In this post, we focus on preparation: understanding how replication works, what your resilience posture looks like, and the operational groundwork that separates a controlled failover from a scramble.

Introducing ExtendDB: An open source DynamoDB-compatible adapter with pluggable storage backends
Today, we are announcing ExtendDB, an open source Amazon DynamoDB-compatible adapter with pluggable storage backends, released under the Apache 2.0 License. ExtendDB implements the DynamoDB wire protocol and ships with PostgreSQL as its first backend, so any AWS SDK, CLI, or tool that works with DynamoDB works with ExtendDB unchanged. In this post, we introduce ExtendDB, walk through getting started, and explain the architecture. This is a v0.1 release for development, testing, and experimentation.

Zero-downtime DynamoDB construct migration: from Table to TableV2 with cdk orphan
In this post, we show you how to use the new cdk orphan command to safely migrate a DynamoDB table from the Table construct to TableV2 with zero downtime. Your data stays intact, streams keep flowing, and your application remains available throughout the process.

Filter, transform, and load your DynamoDB table exports using AWS Glue
In this post, we show how you can load (import) an Amazon DynamoDB full or incremental table export into a second DynamoDB table with precise control over what gets loaded, at what write rate, and with the ability to observe the progress. This technique helps drive large-scale data migrations and synchronizations where you want maximum control.

AWS purpose-built database recovery: A guide to business continuity and disaster recovery strategies
This post addresses recovery challenges in multi-database architectures, focusing on both low-consistency and mission-critical scenarios. We explore practical strategies for implementing resilient recovery mechanisms across Amazon DynamoDB, Amazon Aurora, Amazon Neptune, Amazon OpenSearch Service, and other AWS database services.
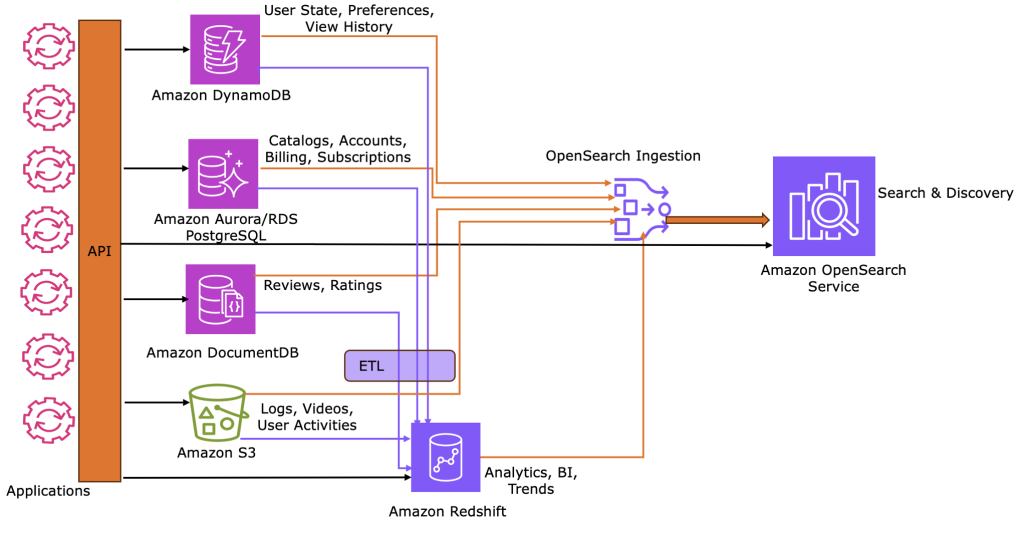
How to build unified JSON search solutions in AWS
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.

Enabling nested transactions in Amazon DynamoDB using C#
In this post, I introduce a framework for managing atomicity, consistency, isolation, and durability (ACID) compliant transactions in Amazon DynamoDB using C#, featuring support for nested transactions. This capability allows you to implement sophisticated logic with finer control over data consistency and error handling within your .NET applications. With this nested transaction framework, you can isolate issues, allow for partial rollbacks, and build maintainable, modular workflows on top of the built-in transactional capabilities of DynamoDB.