AWS Database Blog
Category: Amazon DocumentDB

How Amazon DocumentDB on AWS Graviton4 R8g instances delivers 63% better Sysbench benchmark results
This post demonstrates how in our testing upgrading to Graviton4-based R8g instances on Amazon DocumentDB (with MongoDB compatibility) version 5.0 and 8.0 delivers up to 63% better performance compared to Graviton2-based R6g instances on the Sysbench benchmark. This improvement comes at only a 5% cost increase.
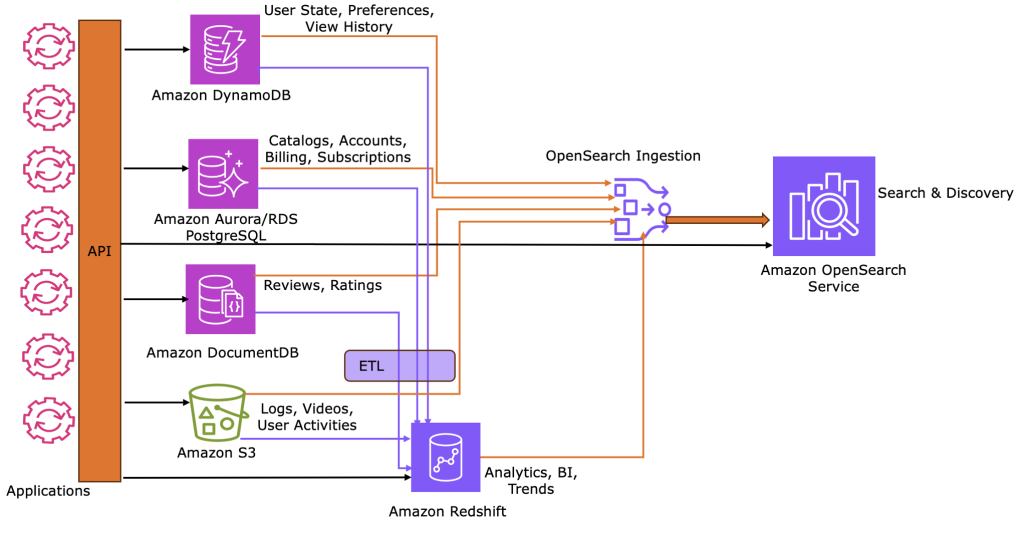
How to build unified JSON search solutions in AWS
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.

Turbocharge your applications with Amazon DocumentDB 8.0
Amazon DocumentDB 8.0 brings in support for MongoDB 8.0 API driver compatibility while maintaining support for applications built using MongoDB API versions 6.0 and 7.0. This post explores the new features in Amazon DocumentDB 8.0 and demonstrates how they improve performance and cost efficiency.

Build a fitness center management application with Kiro using Amazon DocumentDB (with MongoDB compatibility)
In this post, we walk through how we used Kiro, an agentic Integrated Development Environment (IDE), to build a complete fitness center management application that digitizes paper-based fitness tracking. We explore Kiro’s spec-driven development workflow and see how it transforms complex application development into a streamlined, iterative process. Our solution uses Amazon DocumentDB as the backend.

Amazon DocumentDB (with MongoDB compatibility) introduces new query planner that delivers up to 10x performance improvements
On Oct 28, 2025, Amazon DocumentDB (with MongoDB compatibility) introduced a new query planner (NQP) to improve database performance and stability. The redesigned architecture uses improved cost estimation techniques and optimized algorithms for smarter query plan selection.

Migrating Amazon DocumentDB Cluster across Regions: A step by step guide
In this post, you will learn to migrate a regional Amazon DocumentDB cluster from one AWS Region to another using the Global Cluster feature with low downtime and without performance impact.

JSON database solutions in AWS: Amazon DocumentDB (with MongoDB compatibility)
JSON has become the standard data exchange protocol in modern applications. Its human-readable format, hierarchical structure, and schema flexibility make it ideal for representing complex, evolving data models. As applications grow more sophisticated, traditional relational databases often struggle with several challenges: Rigid schemas that resist frequent changes Complex joins for hierarchical data Performance bottlenecks when […]

Announcing Extended Support for Amazon DocumentDB (with MongoDB compatibility) version 3.6
Today, Amazon DocumentDB (with MongoDB compatibility) announced that Amazon DocumentDB version 3.6 will reach end of life on March 30, 2026. Starting March 31, 2026, you can continue to run Amazon DocumentDB version 3.6 on Extended Support. Extended Support provides fixes for critical security issues and bugs through patch releases for three years beyond the end of standard support of Amazon DocumentDB version 3.6.

Transform uncompressed Amazon DocumentDB data into compressed collections using AWS DMS
In this post, we discuss handling large collections that are approaching 32 TiB for Amazon DocumentDB. We demonstrate solutions for transitioning from uncompressed to compressed collections using AWS DMS. This migration not only accommodates larger uncompressed data volumes, but also significantly reduces storage, compute costs associated with Amazon DocumentDB and improves performance.

Amazon DocumentDB Quick Start: Zero Setup with AWS CloudShell
Amazon DocumentDB (with MongoDB compatibility) launched its integration with AWS CloudShell. With this integration, you can now connect to Amazon DocumentDB with a single click on the AWS Management Console without needing to perform any setup. In this post, we show how to connect to and work with Amazon DocumentDB using CloudShell. Amazon DocumentDB is […]