AWS HPC Blog
Introducing fair-share scheduling for AWS Batch
Today we’re introducing fair-share scheduling, a new way to manage many users or workloads in a single AWS Batch job queue, with compute allocation among them managed by AWS Batch.
AWS Batch is a cloud-native batch scheduler designed for rapidly running batch workloads at scale while maintaining low costs. It’s a fully managed service for customers to submit, run, and monitor millions of jobs, and it handles all the provisioning of resources and job scheduling for you. That leaves you to focus on the problem you’re trying to solve, not the operation of a compute fleet.
Until now, AWS Batch used a first-in, first-out (FIFO) strategy to schedule jobs. Customers who have shared compute capacity amongst dozens or even hundreds of workloads experienced “unfair” situations as the order of submission defined when the scheduler placed jobs. This led to workloads which required to run jobs immediately get stuck behind already submitted jobs on the shared compute environment.
With the launch of fair-share scheduling (FSS) in AWS Batch, customers have more control of the scheduling behavior in order to address the shortcomings of FIFO scheduling. In this post, we’ll explain how fair-share scheduling works in more detail. You’ll find a link to our step-by-step workshop at the end of this post, so you can try it out yourself.
FIFO Job Scheduling
In FIFO, jobs are submitted to a queue, and are scheduled to run in the order they’re submitted, when they reach the head of the queue and there are enough free compute resources to run the job.

Figure 1: FIFO Job scheduling with a single queue. Jobs are scheduled from the head of the queue.
While this works well for most situations, FIFO can cause “unfair” situations where a workload gets trapped. For example, this can occur when many long-running jobs are in front of a few short jobs.
Customers told us they wanted the AWS Batch scheduler to provide fairness in compute allocation. This is important, because they needed their different business groups to have confidence that when they use shared compute environments their workloads are not held hostage by another group hogging the resources.
FIFO queues can’t solve this problem. We needed some more levers that impact the scheduling algorithm.
Introducing fair-share scheduling (FSS)
With fair-share scheduling, we’ve enhanced AWS Batch with a new set of controls, that allow you to give fair treatment (defined by your business needs) to many users, while managing them all from a single AWS Batch job queue, reducing the time it requires for you to onboard new users and create new environments. We introduced scheduling policies, share identifiers, fairness-over-time parameters, job priority, and compute reservation.
AWS Batch scheduler will keep track of resource usage and schedule jobs so that capacity is allocated fairly. The allocation details can be configured using a scheduling policy attached to the queue.
Introducing scheduling policy
Creating and attaching a scheduling policy to a job queue enables fair share scheduling for that queue. Customers can differentiate their jobs from one another by using a shareIdentifier value, which is set by them at submission time. This could just be their username, or the name of their department. You can control which shareIdentifier can be used by a specific user using IAM policies. The shareIdentifier provides a hint to the scheduler that these are different workloads needing equitable access to the shared compute environments.
Each share identifier also has a weightFactor, which defines the ratio of compute capacity allocated to each shareIdentifier. Since you do not need to configure share identifiers before using them, each has a weightFactor of 1 by default. This results in all jobs with a shareIdentifier getting an equal share of the attached compute resources in relation to all the other jobs withshareIdentifiers within the queue.
You can override the weightFactor for a specific shareIdentifier in the scheduling policy. For example, specifying a weightFactor of 0.5 for a workload will result in that workload getting twice as many resources as a workload with the default weightFactor of 1. Figure 2 shows how two different workloads are scheduled according to their default weightFactor.
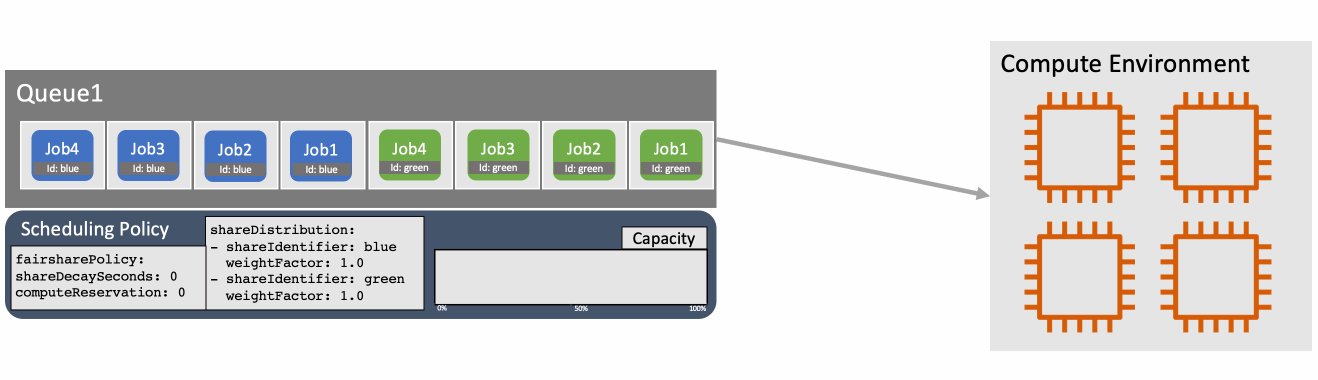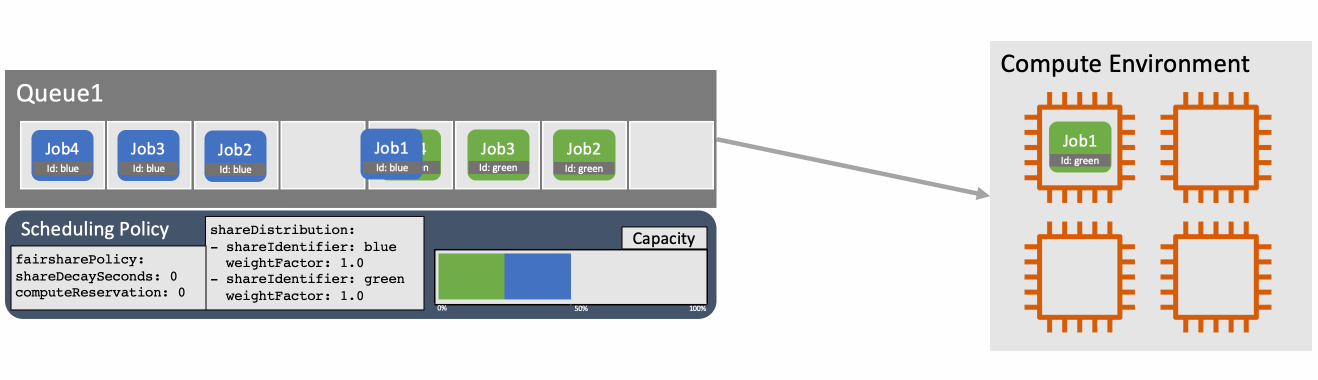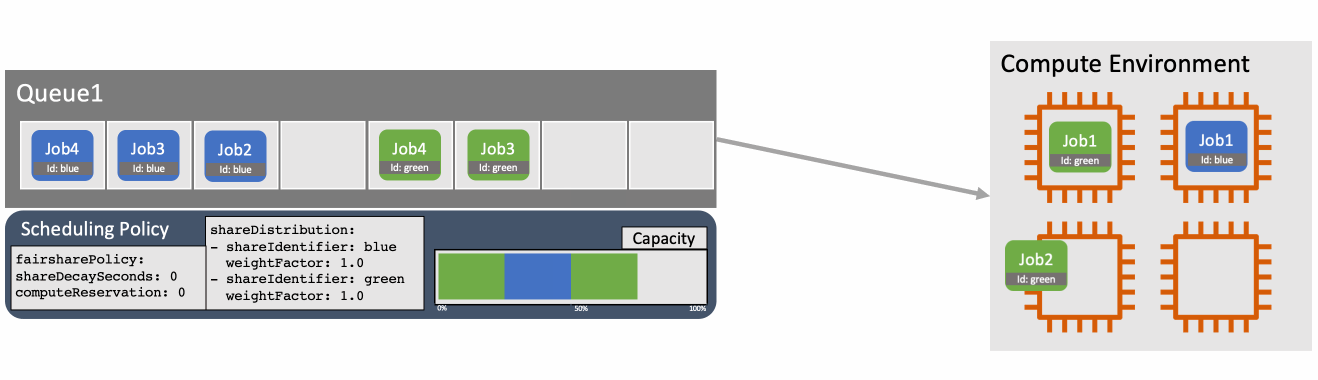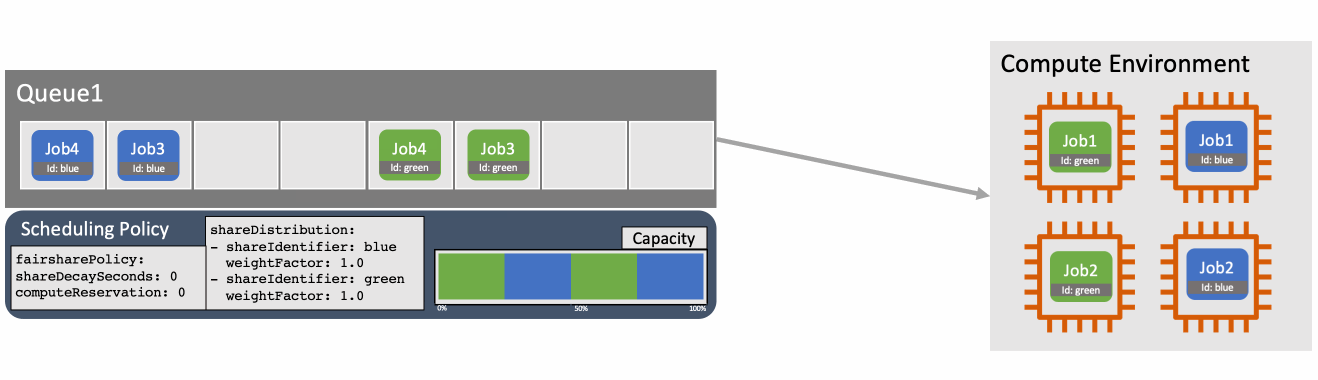
Figure 2: With two identifiers defined in the scheduling policy jobs are scheduled so that the capacity usage is balanced according to the relative weightFactors.
Figure 3 shows an example of a scheduling policy in the AWS Batch Console.

Figure 3: Scheduling policy screenshot of an example policy with two shares.
Controlling fairness over time
By default, the AWS Batch scheduler will look at the current usage when determining the order of dispatch for shareIdentifiers. Customers can define the time windows (shareDecaySeconds) that should be used when calculating fairness for workloads over a longer period. This might be useful to smooth out resource usage over time, especially in cases where there is a heavy disparity of job count or job run times between shareIdentifiers.
Submitting jobs with higher priority
We’re also introducing scheduling priority which determines the order of execution of jobs within a shareIdentifier. Jobs with a higher priority will be scheduled before jobs with a lower scheduling priority within a shareIdentifier. The priority can be specified in the job definition or when submitting a job. Figure 4 shows how higher priority jobs (Job 4 to Job 6) are scheduled first, even though they were submitted after lower priority jobs (Job1 to Job3).

Figure 4: Fair-share scheduling with using priorities when submitting the jobs. High priority jobs (Job4 to Job6) are scheduled first when capacity is available in the compute environment.
Compute capacity reservations
Along with fair dispatch of jobs there might still be cases where you want to reserve a portion of your compute resources exclusively for workloads that do not have active jobs. Compute capacity reservation within a scheduling policy lets you do that. This helps to prevent a single workload from taking up all the capacity and allows for jobs from a new workload to start processing right away.
Three different scenarios will help you understand how this works.
In the first example (Figure 5) we defined a scheduling policy that reserves 50% of the compute capacity to be used by the jobs with two different shareIdentifier values, also defined in the policy. This in effect allocates 25% of the capacity to each of green and blue categories. The remaining 50% of capacity is available for either of the workloads to leverage. At first only “green” jobs are in the queue, so they get 75% of all the capacity (25% + 50%), and the scheduler reserves the last 25% for blue workloads. As blue requests come into the queue, they get their allocated 25% capacity. When resources are freed by jobs finishing blue and green jobs get an equal share of the unallocated compute capacity.

Figure 5: The dotted boxes within the capacity illustrate the reservation for each of two workloads. The green workload might reach 75% capacity. In this case, when blue jobs are submitted, the remaining 25% capacity is still assured. When Job1 (green) finishes, another blue job is scheduled taking the weightFactor into account.
Next, in Figure 6 we show another scenario which uses three shareIdentifiers and a reservation of 75%, which leads to 25% reservation for each. Any one of these workloads may be able to consume as much as 50% of the available capacity (25% exclusive and 25% unreserved), but other shareIdentifiers are still able to access a 25% share of the total capacity.

Figure 6: With three shareIdentifier values and 75% capacity reserved, each identifier has exclusive access to 25% of the capacity.
Finally, what if we want to reserve ALL the capacity? Batch imposes a maximum for computeReservation of 99% to prevent a scenario where some submitted jobs will never get scheduled. Figure 7 shows an example of this.

Figure 7: With 99% reserved the capacity is evenly split between the two shareIdentifiers.
Reservations are important in fair-share scheduling, because they enable you to define policies that preventing any single workload dominating the capacity in a shared compute environment.
More control of scheduling behavior
In summary, fair-share scheduling policies allow you to influence how jobs get scheduled using the following criteria:
Weight Factors per Share Identifier – Different identifiers (e.g., workloads/users) will have a weightFactor of 1 by default, so that they get an equal share. You can adjust this weightFactor to grant a user a bigger share. The use of the identifiers can be controlled via IAM policy to ensure fairness amongst users.
Fair Share over Time – A scheduling policy can take prior usage into account to apply fair share scheduling, not just the current usage by a shareIdentifier.
Priority Scheduling – Scheduling policies can shift priority for a user (shareIdentifier), so that a job can “jump the queue” and get scheduled ahead of time. This helps customers prioritize jobs without draining the queue beforehand.
Compute Reservation – Compute reservation is a parameter that allows customers to reserve a part of their compute resources for jobs that have fair-share identifier that have not been used yet.
Conclusion
Fair-share scheduling (FSS) for AWS Batch provides fine-grain control of the scheduling behavior by using a policy. With FSS, customers can prevent “unfair” situations caused by strict first-in, first-out scheduling where high priority jobs can’t “jump the queue” without draining other jobs first. You can now balance resource consumption between groups of workloads and have confidence that the shared compute environment is not dominated by a single workload.
To get started, you can follow our step-by-step workshop. For more details on the new fair-share scheduling features, you can refer to the AWS Batch scheduling policies user guide and API documentation.
Note: we published a more recent blog post — Diving Deeper into Fair-Share Scheduling in AWS Batch — which goes into more details and policy showcases examples and their affect on how jobs from different shares are scheduled.