AWS for Industries
Automate TM Forum API testing using Amazon Bedrock and Claude
Introduction
Testing telecommunications TM Forum APIs with Behavior Driven Development (BDD) presents challenges for your development teams. You need to navigate complex business processes, maintain alignment with TM Forum standards, and manage extensive test scenarios. These challenges are compounded when you’re dealing with frequent specification updates and collaborating across teams.
In this post, you will learn how to use Amazon Bedrock with Claude to automatically generate comprehensive BDD test scenarios and Stub code from TM Forum API specifications. This generative AI approach can reduce your test development time while ensuring consistent coverage and standardization.
You’ll see this solution in action with the TMF629 Customer Management API, which enables standard customer data management across telecommunications systems.
By implementing this automated testing solution, you can maintain compliance with TM Forum’s conformance requirements while freeing your development teams to focus on higher-value activities. The solution transforms manual BDD testing processes into efficient, AI-powered workflows that adapt quickly to specification changes and ensure thorough test coverage.
Inherent Challenges
Testing TM Forum APIs presents several complex challenges when using Behaviour-Driven Development (BDD). The interconnected nature of telecommunications services makes it difficult to translate technical specifications into clear, natural language scenarios.
Maintaining BDD consistency becomes particularly challenging as different teams often develop their own approaches to scenario generation and stub code implementation. This leads to inconsistent test coverage, varying quality standards, and different stub code patterns across your organization.
The complexity increases when your teams need to master both BDD frameworks and TM Forum’s detailed API specifications simultaneously. This makes it difficult to maintain scenario consistency across API version updates and ensure alignment with conformance requirements. Coordination between API developers, testers, and business analysts creates another layer of complexity. These teams must work together to create documentation that bridges the gap between BDD best practices and TM Forum standards while keeping test scenarios both technically accurate and business-relevant across multiple interconnected domains.
This lack of standardization in both scenario generation and stub code development not only impacts test quality and maintainability but also significantly hampers the ability to share and reuse test assets across teams, leading to duplicated efforts and inconsistent testing practices.
Solution Architecture
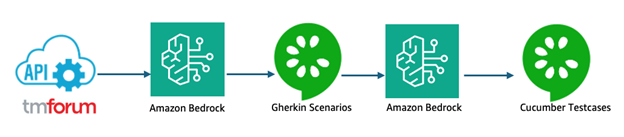
Figure 1: High level solution architecture
The solution uses Amazon Bedrock with Claude to interpret TM Forum API specifications and automatically generate standardized Gherkin scenario. These scenarios are then converted into Java code stubs, streamlining your test development process.
You maintain full control over the testing process, with the ability to review and refine the generated content to match your business requirements. (As depicted in figure 1)
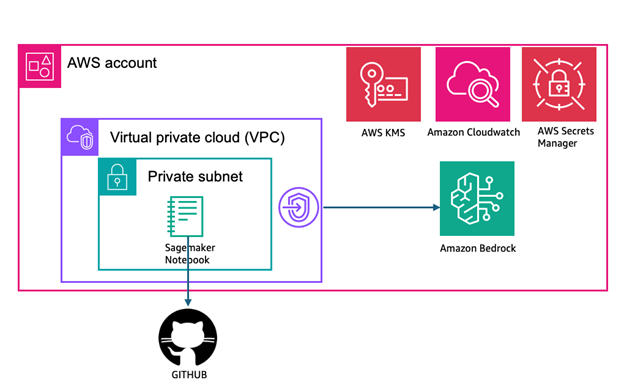
Figure 2: AWS Cloud Solution Architecture
The solution runs in an Amazon SageMaker notebook deployed in your VPC, where you can select specific API paths, methods, and response codes for scenario generation. Amazon Bedrock serves as the secure foundation model platform where your API specifications are processed by Claude’s advanced natural language capabilities to extract test requirements and convert them into structured BDD scenarios. The notebook environment provides you with a familiar development experience while maintaining security through your VPC configuration. (As shown in figure 2)
After generating the Gherkin scenarios, the solution creates Java stub code that you can integrate with your existing codebase.
Prompt Engineering
Prompt engineering is an effective way to harness the power of Foundational Models (FM). You can pass specific instructions within the context window of the foundation model, allowing you to provide detailed context about your TM Forum API specifications and testing requirements. With Amazon Bedrock, you can create personalized prompts that help Claude understand the technical complexity of telecommunications APIs.
The COSTAR framework (Context, Objective, Style, Tone, Audience, and Response) offers you a structured methodology for crafting effective prompts. By following this approach, you can design prompts tailored to generate the specific types of BDD scenarios you need:
- Context: Include relevant TM Forum API documentation and specifications
- Objective: Specify the exact test scenarios you need to generate
- Style: Request Gherkin syntax compatible with your BDD framework
- Tone: Define the technical precision level required
- Audience: Clarify if the output is for developers, testers, or business analysts
- Response: Specify the structure of the generated test scenarios
Chain-of-thought (CoT) prompting improves the reasoning abilities of foundation models by breaking down complex testing tasks into smaller, more manageable steps. When you use this technique with Claude on Amazon Bedrock, you can guide the model to first analyze the API specification, then identify test scenarios, and finally generate appropriate Gherkin syntax and stub code.
By applying these prompt engineering techniques with Amazon Bedrock, you’ll generate more accurate and comprehensive BDD test scenarios that properly test your TM Forum API implementations.
Gherkin Scenario Prompt
The sample prompt for generating the Gherkin scenarios as per the structure defined is available in the notebook.
The prompt you’ll use provides detailed instructions for converting API documentation into Gherkin test scenarios. You’ll process a Swagger file to generate structured Gherkin test cases for specific API endpoints. The process involves parsing API details including paths, operations, and response codes, then extracting required parameters, types, and example values. The instructions specify step by step (Chain of Thought) guidance on how you can construct test scenarios with proper Given-When-Then syntax, including server details, authorization tokens, parameter values, and expected response validations. The output follows a standardized Gherkin format with clear scenario titles, parameter settings, and response validations.
This systematic approach ensures you create consistent, maintainable test scenarios that accurately reflect the API’s functionality while providing comprehensive test coverage for your QA engineers and developers.
Java Stub Code Prompt
The sample prompt for generating the cucumber test scenarios as per the structure defined is available in the notebook you’re working with.
The prompt you’ll use outlines instructions for converting Gherkin Feature files into executable Cucumber-based Java test code. You’ll analyze your provided feature file to identify scenarios, steps, and examples, then transform them into a structured Java class with appropriate step definitions.
The process involves creating a Java class named after the feature (suffixed with “Steps”), implementing methods for each unique Gherkin step using Cucumber annotations (@Given, @When, @Then), and handling parameterized scenarios through Scenario Outlines.
Your generated code will follow Java best practices, including descriptive method names, proper exception handling, and clear documentation through comments. The output will be well-formatted Java code that accurately represents your feature file’s scenarios, complete with placeholder implementations and TODO comments for steps requiring further development. The focus is on helping you create maintainable, executable test code that strictly adheres to the functionality specified in your original Gherkin feature file.
Prerequisites
Before you begin, make sure you have:
- An AWS account with access to Amazon Bedrock and Amazon SageMaker AI.
- Terraform (1.12.2 or later)
- Access to TM Forum API specifications v3 Customer Management API (TMF629)
Set up the SageMaker notebook
To set up the Amazon SageMaker notebook in your AWS account, you’ll use Terraform to provision the required resources.
- Clone the repository to your local machine. git clone https://github.com/aws-samples/sample-genai-gherkin-testcase.git
- Navigate to the solution directoryc d sample-genai-gherkin-testcase/terraform
- Initialize Terraform terraform init
- Preview the resources that will be created. terraform plan
- Deploy the resources to your AWS account: terraform apply
On the AWS Management Console, navigate to Amazon SageMaker.
- In the navigation pane, choose Notebook instances.
- Find the notebook instance that was created by terraform and choose Open Jupyter and open the notebook instance with a standard Jupyter interface.

Figure 3: Amazon Sagemaker AI Notebook Instances
- Navigate to
sample-genai-gherkin-testcase/input folder and uploads the swagger api spec in the input folder. Click on upload and choose a file and then click upload.
Figure 4: jupyter notebook -Input Schema
Navigate back to sample-genai-gherkin-testcase folder and open the notebook gherkin_java_generator.iypnb. Select conda_python3 as kernel.
Figure 5: jupyter notebook-Setting Kernel
- Follow the step-by-step instructions within the notebook to implement the solution.
The notebook contains all the code needed to connect to Amazon Bedrock, process the TM Forum API specifications, and generate your BDD test scenarios.
Implementation steps
1. Run the first code cell to import and initialize the bedrock runtime and set up model parameters. The Claude model uses three key parameters: temperature (set to 0 for consistent outputs), top_p, and top_k (both using default values) to control text generation.
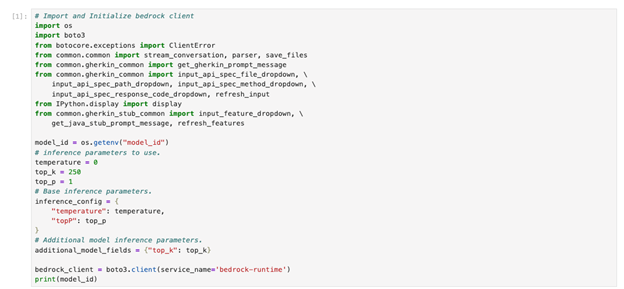
Figure 6: Claude Inference Parameter Setting
2. Run the next cell which asks you to provide inputs for the API specification file, endpoint selection, method and response code.
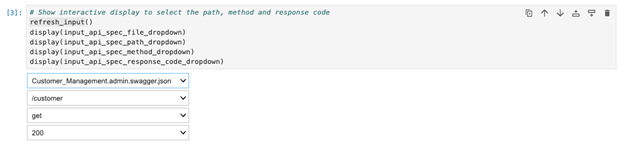
Figure 7: jupyter notebook-Parameter Selection
When you run the code, you can:
- Select a YAML file from your input folder
- Choose the API path
- Select the HTTP method
- Select the response code for scenario generation
3. Invoke the Amazon Bedrock streaming API to generate the scenarios based on your selected inputs. The code sends your API specification and prompt to Claude through Amazon Bedrock’s converse stream API, which processes the information and returns Gherkin scenarios tailored to your selected endpoints.
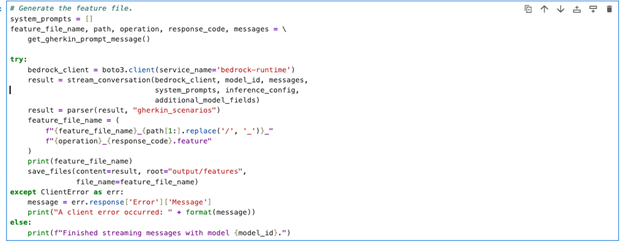
Figure 8: jupyter notebook-Generate feature file
The notebook automatically saves your generated Gherkin scenarios in a structured output directory (As shown in figure 9 and 10) for further processing. You can examine both your generated test scenarios and the model’s detailed explanations. The explanations provide insights into how Claude interprets your API specifications and creates scenarios. The organized folder structure makes it easy for you to locate specific test cases and track the generation process for each API endpoint you selected.
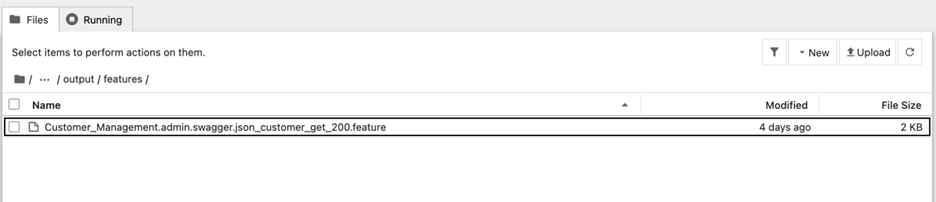
Figure 9: jupyter notebook-output feature file location
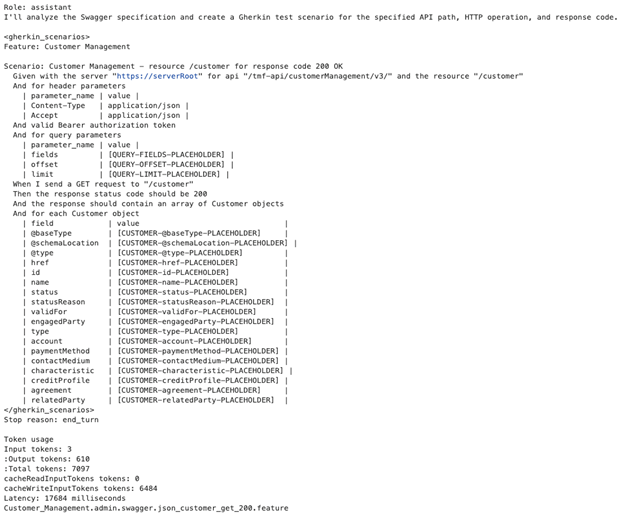
Figure 10: jupyter notebook-sample gherkin feature file
4. Run the next cell in the notebook which sets up the prompt for Cucumber test scenario generation and asks for your input. You’ll need to select the feature file
(generated from previous step) for which you want to generate Java stub code. The dropdown menu will display all available feature files from your output directory.

Figure 11: jupyter notebook-Select feature file
5. Invoke the Amazon Bedrock converse API to generate the Java stub code. The notebook sends your selected Gherkin feature file to Claude through Amazon Bedrock, which processes the content and returns the corresponding Java implementation code.
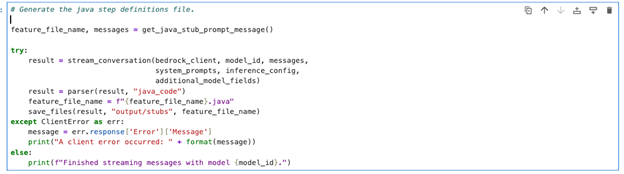 Figure 12: jupyter notebook-Generate java step definition
Figure 12: jupyter notebook-Generate java step definition
The notebook automatically saves your generated Cucumber test scenarios in a structured output directory. You can examine both your generated Java cucumber test case and the explanations provided by Claude. The organized folder structure makes it easy for you to locate specific test cases and track the generation process for each API endpoint you’ve tested (As shown in figure 13 and 14).

Figure 13: jupyter notebook-java step file location
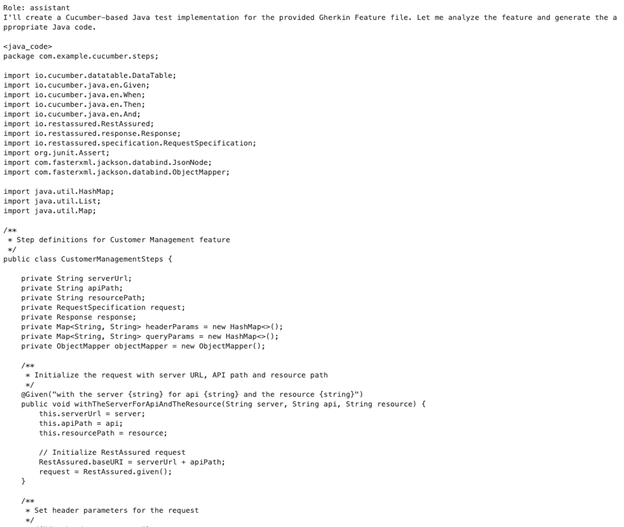
Figure 14: jupyter notebook-sample java step file
This file contains the actual implementation of the steps described in the feature file. When creating these files, it’s important to review and modify any placeholder values with appropriate test data that matches your specific testing environment. Optionally, you can first create the feature file with your desired test values, and then use it to generate the Java code, ensuring alignment between your scenarios and step definitions.
You can extend this solution by creating prompt catalogs targeting different programming languages and libraries. For example, you might develop additional prompts for generating tests in Python with pytest etc. This flexibility allows you to adapt the solution to your organization’s specific technology stack while maintaining consistent test coverage across all your TM Forum API implementations.
Lessons Learned
Throughout the development of this solution, you’ll find several valuable insights that can help you achieve better results when using foundation models for test generation.
- COSTAR Framework: Use clear and direct instruction to achieve the right results. Use of multiple examples allows to cover multiple scenarios and pattern of outputs. Use chain of thoughts as a method allows detailed step by step processing. Appropriate XML tags allow calling programs to extract the relevant outputs. Providing reference examples in the prompt defines the response structure.
- Long Contexts tips: For large TM Forum OpenAPI specifications, breaking down tasks to focus on specific paths, methods, and response levels reduces unnecessary information. This results in shorter, more focused prompts and improved efficiency when interacting with Claude. Filtering API specifications to include only the required path, method, and response code minimizes context size by eliminating unnecessary information.
- Prompt Caching: Caching relevant portions of prompts saves on input token costs when repeatedly generating tests for similar API endpoints.
- Iterative Refinement: Continuously refining prompts based on output quality leads to improved outcomes. While specificity is important for technical accuracy in TM Forum API tests, allowing some flexibility helps Claude handle edge cases in API specifications.
Clean Up
To avoid incurring future AWS charges, it’s important to delete all resources created during this tutorial.
- Backup Your Notebook Files: Before destroying the resources, ensure you’ve backed up all important files from your SageMaker notebook.
- Clean up the resources by running the following command. terraform destroy
This will remove the Amazon SageMaker notebook along with the VPC it was created in.
Conclusion
This post has shown you how to generate comprehensive Gherkin scenarios and corresponding Cucumber test code from TM Forum API specifications using Amazon Bedrock and Claude. The solution follows an iterative approach, starting with a base prompt and refining it through multiple iterations based on best practices like providing clear examples, allowing the foundation model to think through problems step-by-step, using XML tags for structured outputs, and setting appropriate parameters.