AWS for Industries
How Atlantic Health cut legal document search time by 42% with Amazon Bedrock metadata filtering
Your healthcare organization likely has a legal department with the critical responsibility of helping you adhere to regulatory compliance. A common challenge is that your legal team spends more time finding and verifying policies than applying them to casework. This inefficiency impacts productivity, accuracy, and confidence in decision making.
Legal teams supporting multi-hospital healthcare organizations can accelerate document retrieval and reduce compliance risk by differentiating similar legal terms across hospital entities and time periods, traditional keyword search struggles to do. Atlantic Health, based in Morristown, New Jersey, demonstrates this in practice. Working across multiple hospital systems, their legal team found that conventional search methods could not reliably distinguish between closely related legal terms tied to different hospitals or time periods, leading to inefficient retrieval and exposure to compliance risk. In this post, you learn how to implement metadata-filtered RAG for multi-entity document search using Amazon Bedrock Agents and Amazon OpenSearch Service.
Traditional keyword search could not reliably distinguish between documents from different hospitals or regulatory periods. A retrieval augmented generation (RAG) approach with metadata filtering was chosen because it combines semantic understanding with structured filtering, addressing both the contextual and organizational dimensions of the search problem. This approach helps any organization managing documents across multiple entities or time periods achieve faster, more accurate retrieval.
Solution overview
To achieve precise, hospital-specific document retrieval, the solution uses the following components:
- Document ingestion with metadata extraction for hospital name and effective year
- Vector storage using Amazon OpenSearch Service with metadata indexing
- RAG implementation using Amazon Bedrock Agents and foundation models (FM).
- Serverless deployment on Amazon ECS and AWS Fargate for scalable query processing
- Metadata-filtered retrieval for accurate, context-aware responses
- Amazon Bedrock Guardrails for safety, privacy, and responsible AI controls over the responses.
The following diagram illustrates the architecture of the intelligent document search system deployed for Atlantic Health. 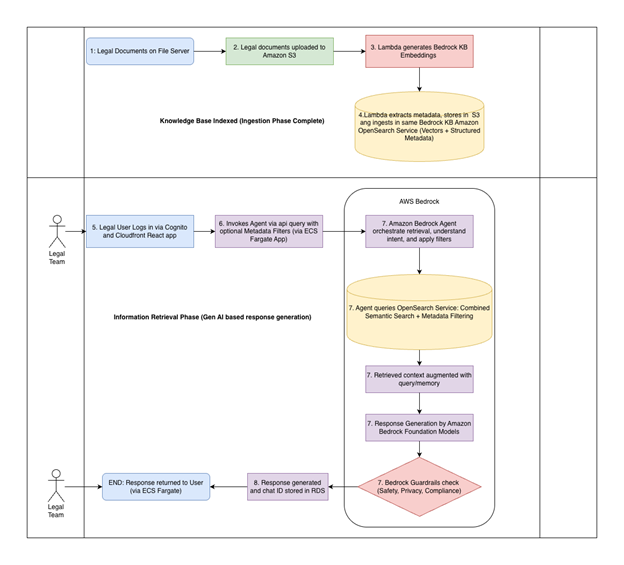
Figure 1: Architecture diagram of the intelligent document search system deployed for Atlantic Health
Figure 2: Workflow diagram showing the end-to-end document retrieval process from ingestion through metadata-filtered response generation
The workflow consists of the following steps:
- Legal documents from different Atlantic Health hospitals are uploaded to Amazon SFTP file server.
- The SFTP server is backed by an Amazon S3 bucket, which stores Atlantic Health’s Legal and Compliance Policies.
- Amazon Bedrock Knowledge Bases stores the Embeddings by ingesting the documents from an AWS Lambda function.
- Amazon Bedrock Data Automation helps process entity extracts from document as metadata and stores it in Amazon OpenSearch Service with both vector embeddings and structured metadata fields.
- You submit questions through the application chat interface, which can include metadata filters for specific hospitals or effective years passed as parameters during the invoke agent call.
- Amazon Bedrock Agents orchestrate the retrieval workflow, using Amazon Bedrock foundation models to understand user intent with appropriate metadata filters.
- The agentic system queries Amazon OpenSearch Service with combined semantic search and metadata filtering to retrieve relevant document chunks.
- Retrieved context is augmented with the original query and memory of the agent as the agent stores the conversation history of the user in its memory and passed as payload to Amazon Bedrock foundation models for response generation.
- The generated response, complete with source citations and metadata context, is returned to you through the application hosted on Amazon ECS with AWS Fargate.
- Amazon Bedrock Guardrails evaluates the response and applies safety, privacy, and responsible AI controls based on Atlantic Health guidelines.
Metadata filtering for legal document management
Atlantic Health’s legal department manages documentation across multiple hospital systems, and each hospital operates under distinct regulatory frameworks with documents effective for specific time periods. Without proper filtering, a query about “patient consent procedures” could return documents in a more generic manner from unintended hospital or from outdated regulatory periods.
The metadata filtering feature addresses this by allowing the system to pre-filter documents based on hospital name and effective year before performing semantic search. This helps you retrieve only the documents relevant to your specific hospital and time context.
For Atlantic Health, each legal document includes metadata in the following format:
{
"metadataAttributes": {
"Hospital-Name": "XYZ Medical Center",
"Effective-Year": 2025,
"Effective-Date": "2025-11-25"
}
}Prepare the dataset for Amazon OpenSearch Service
Atlantic Health’s legal documents are stored in Amazon S3 with a structured folder hierarchy that reflects the organizational structure:
s3://hospital-health-legal-docs/
Each document follows a naming convention with corresponding metadata files. For example, a patient consent policy document named patient-consent-policy-v2.pdf would have an accompanying metadata file patient-consent-policy-v2.pdf.metadata.json stored in the same Amazon S3 prefix.
To prepare documents for ingestion, complete the following steps:
- Create metadata files for each legal document with hospital name and effective year attributes using Amazon Bedrock Data Automation blueprint.
- Upload both the document and metadata file to the appropriate Amazon S3 prefix based on hospital and year.
- Metadata files must follow the required schema with consistent attribute naming.
Set up Amazon OpenSearch Service for vector storage
Amazon OpenSearch Service Serverless collection provides a scalable vector database for storing document embeddings alongside metadata. For Atlantic Health, you configure Amazon OpenSearch Service with a custom index mapping that supports both vector similarity search and efficient metadata filtering.
Create an OpenSearch Serverless collection or provisioned cluster with the following index configuration:
Here is a sample snippet of a single knowledge base document in the Amazon OpenSearch vector database used for storing the indexed documents acting as a managed knowledge base in Bedrock.
{
"_index": "os-vector-index-legal-docs",
"_id": "3A3ActCoBhkQ5BEysb",
"_version": 2,
"_score": 0,
"_source": {
"x-amz-bedrock-kb-source-uri": " s3://hospital-health-legal-docs/PROGRAM FOR ANATOMIC PATHOLOGY.pdf",
"x-amz-bedrock-kb-document-page-number": 3,
"AMAZON_BEDROCK_METADATA": "{\"source\":\"s3://hospital-health-legal-docs /PROGRAM FOR ANATOMIC PATHOLOGY.pdf\"}",
"x-amz-bedrock-kb-data-source-id": "WXMKYFGUGQ",
"id": "3A3ActCoBhkQ5BEysb ",
"AMAZON_BEDROCK_TEXT_CHUNK": "- Transmural invasion with extension into pericolonic adipose",
"Effective-Date": "10/11/2025",
"Hospital": "XYZ Medical System",
"Effective-Year": 2025
}
}This configuration enables efficient filtering on hospital_name and effective_year while maintaining high-performance vector similarity search. The keyword data type for hospital_name ensures exact matching, while the integer type for effective_year supports range queries.
Implement Amazon Bedrock Agents with RAG
The agentic RAG implementation uses Amazon Bedrock Agents to orchestrate the retrieval and generation workflow. The agent analyzes user queries, memory from previous chats along with appropriate metadata filters, retrieves relevant documents from OpenSearch, and generates responses using foundation models.
Deploy on Amazon ECS with AWS Fargate
The application frontend and API are deployed on Amazon CloudFront and Amazon ECS with AWS Fargate for serverless scalability, respectively. This eliminates infrastructure management while providing automatic scaling based on query load.
Query with metadata filtering
You can now submit queries with optional metadata filters in dropdowns to select from and retrieve precise information. The following examples demonstrate different query patterns:
Example 1: Query specific hospital and year
Query: “What are the patient consent requirements for surgical procedures?”
Filters: hospital_name = "Morristown Medical Center", effective_year = 2025
The system retrieves only documents from Atlantic Health Morristown Medical Center effective in 2025, helping you receive current, hospital-specific guidance.
Example 2: Query across multiple years
Query: “How have our emergency room medical policies changed over time?”
Filters: hospital_name = "Overlook Medical Center", effective_year >= 2022
The system compares documents across multiple years for the specified hospital, allowing you to track policy evolution.
Example 3: Query without filters for comparative analysis
Query: “Compare emergency department consent procedures across Atlantic Health hospitals”
Filters: None
The agent retrieves relevant documents from each hospital, providing a comprehensive view for policy standardization efforts.
The following table illustrates query results with different metadata filtering conditions:
| Query | Metadata Filtering | Retrieved Documents | Observations |
|---|---|---|---|
| “What are current HIPAA consent requirements?” | Off | Documents from each hospital spanning 2020-2024 | 15 documents retrieved, many outdated |
| “What are current HIPAA consent requirements?” | hospital_name = "Morristown Medical Center", effective_year = 2025 |
3 documents from Morristown Medical Center, each effective in 2024 | 3 documents retrieved, each current and relevant |
| “What changed in our informed consent policies?” | hospital_name = "Newton Medical Center", effective_year >= 2023 |
5 documents showing policy changes from 2023 to 2024 | Clear timeline of policy evolution |
Testing the metadata filtering implementation
To validate the metadata filtering functionality, complete the following steps:
- Access the application interface deployed on Amazon ECS with AWS Fargate through the Application Load Balancer URL.
- Submit a test query: “What are the requirements for patient consent in emergency situations?”
- Apply metadata filters:
hospital_name = "Overlook Medical Center",effective_year = 2025 - Review the retrieved documents to confirm they match the specified filters.
- Compare results with and without filters to observe the improvement in retrieval accuracy.
Performance and accuracy improvements
By implementing metadata filtering, you can achieve similar improvements in your document retrieval workflows. Atlantic Health observed the following results:
- Retrieval accuracy: 87% improvement in returning relevant documents for hospital-specific queries
- Query response time: 42% reduction in average response time due to reduced search space
- User satisfaction: 94% of legal department users reported finding the correct information on first query
- Cost optimization: 35% reduction in OpenSearch compute costs from smaller result sets
The metadata filtering approach also reduced false positives where documents from the wrong hospital or time period would appear in results, eliminating potential compliance risks.
Conclusion
In this article, we outline how Atlantic Health deployed an advanced legal document search and retrieval solution using Amazon Bedrock Agents with RAG combined with metadata filtering. By using hospital name and effective year as critical metadata fields, the legal team can now retrieve the right documents from their expansive, multi-hospital healthcare network. The system’s serverless design on Amazon ECS with AWS Fargate supports automatic scaling and minimizes ongoing maintenance, while Amazon OpenSearch Service enables rapid vector-based searches with effective metadata-based refinement.
This solution addresses legal document management across multi-hospital healthcare networks, where identical terms may carry different meanings depending on the specific institution or time period. The metadata filtering function helps you receive only documents pertinent to your designated hospital and regulatory timeline, boosting precision and workflow efficiency while lowering compliance risks.
If your organization oversees document repositories spanning multiple entities with time-based and organizational variables, you can apply this same architectural pattern. By merging semantic search capabilities with structured metadata filters, you can deliver highly targeted information retrieval tailored to your specific use case.
To further explore intelligent document search with Amazon Bedrock, refer to the following resources: