Networking & Content Delivery
How AWS improves global connectivity via automated traffic engineering
In our previous post on demystifying Amazon Web Services (AWS) Data Transfer services, we discussed how we designed our global network infrastructure to be highly available, resilient, and performant. In this post, we discuss the AWS approach to Inbound Traffic Engineering (TE). The AWS global network infrastructure operates at a massive scale. In 2024, AWS received more than 150 Exabytes of data from external networks, transit providers, and internet exchanges to support our users’ critical applications and workloads. Inbound TE is a critical component in our network management toolset and makes sure that these critical applications and workloads operate uninterrupted. Inbound TE is something we do on behalf of our users, eliminating the need for them to implement complex network orchestration to mitigate the risk of inbound traffic to their AWS resources.
Our Inbound TE system has played a critical role in resolving performance and availability issues while improving the end-user experience. As a result, we achieved a 90% improvement in time-to-mitigation for Private Network Interconnects (PNIs), Transits, and Internet Exchanges, significantly reducing user impact minutes. Inbound TE systems have also enabled operators to address issues such as traffic imbalance, increased latency, volumetric Distribute Denial of Service (DDoS) attacks, and external network suboptimal routing. In some cases, peers are unable to evenly distribute traffic across their sessions within the same site or metro, resulting in some sessions becoming overused while others sit underused.
The Inbound TE system’s ability to dynamically balance traffic across all available sessions makes sure of the full use of capacity and ultimately leads to a better user experience. It has also proven effective in resolving high-latency scenarios such as trans-Pacific outages or backbone congestion within peer networks by rerouting traffic to the nearest AWS Region. We are excited to tell you more about how we operate this aspect of our global network infrastructure, but first we can explore some of the challenges of internet peering.
Peering in the “network of networks”
The internet is a vast, interconnected system of networks often referred to as a “network of networks“. Various types of networks peer with each other to enable computers worldwide to communicate and exchange information. Although the number of networks and their size continues to expand, the bandwidth between networks typically grows at a slower rate by comparison. Advancements in the digital world and the rapid growth of inter-cloud transmissions mean that traffic between these networks is increasing exponentially, putting even more pressure on these constrained inter-network links. AWS has established processes to evaluate and qualify partner networks that want to peer with AWS at peering locations globally. Currently, AWS peers with over five thousand other networks worldwide. To learn more about how AWS has taken steps to increase the bandwidth and performance of network peering, go to our post that details our initiative to grow AWS internet peering with 400 GbE connections with peer networks.
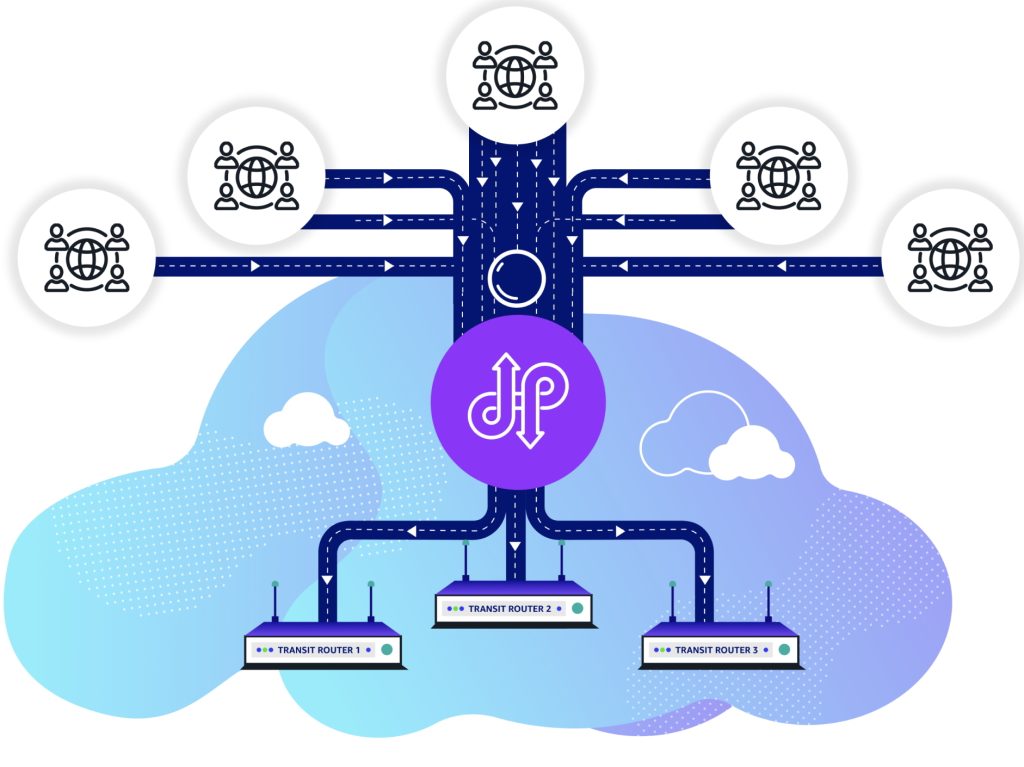
Figure 1: Transit routers peering with other networks
When peered networks experience high usage where they inter-connect, it can result in increased latency, packet loss, and reduced speeds for users. Although adding more peering capacity may seem like the obvious solution, it’s often slow, costly, and operationally complex. This necessitates equipment upgrades, long procurement cycles, and extensive coordination between parties. As a result, many network managers instead choose to optimize their existing capacity to better serve user demands. Traffic engineering techniques play a key role to make sure that available bandwidth is fully used, and in the process maximize the return on investment in capacity expansion. These methods enable more efficient and reliable traffic movement across the Internet, improving performance without the need for costly infrastructure upgrades.
What is the difference between Outbound and Inbound TE?
For Outbound TE, the network typically controls the entire path from the source to the point of exit and can place the traffic in an optimal route within their network. For example, AWS designed and deployed outbound controllers in its border network that prevent congestion by proactively balancing traffic across peer capacity while simultaneously finding the lowest latency paths. Although AWS outbound network controllers provide consistent network performance to support user applications, the existing Outbound TE methods are not as effective when it comes to managing inbound traffic.
For Inbound TE, network managers face greater ambiguity and uncertainty in mitigating inbound congestion and performance-related issues. Inbound TE poses unique challenges, primarily because there is limited control or visibility into the source networks and the intermediary infrastructure between end users and the AWS network. This lack of visibility makes traffic behavior unpredictable, and decisions about routing can have unintended consequences such as inadvertently overloading too much traffic on a single path or interconnect points. Inbound TE is inherently non-deterministic and is thus more complex and riskier than Outbound TE.
Why is automated Inbound TE needed?
Inbound events can be caused by congestion due to organic growth in user traffic, such as inter-cloud workloads, large-scale data migrations, backup and restore operations, or AI and machine learning (ML) training workloads. They can also result from inorganic traffic patterns such as inbound DDoS attacks or imbalanced or sub-optimal traffic distribution from other network providers.
The variability in the types and severity of inbound events often makes it difficult, even for experienced operators, to determine the best course of action. Operators must consider multiple factors, such as the traffic source, causes of sudden throughput spikes, and the current state of transit and peering at the affected location before they choose from various traffic steering strategies. This reliance on operator judgment combined with the “trial and error” nature of operator-driven TE has resulted in many networks (even large ones) to be slow to adopt automated solutions for inbound events. The challenge of automating Inbound TE is further compounded by limited visibility into remote network topologies that makes it difficult to accurately model and predict the effects of routing changes. The dependence on operator judgement and the lack of automation has led to inconsistent and/or prolonged time-to-mitigation (TTM) for internet users. During these events, users experience packet loss and noticeable latency increases such as spikes in Round-Trip Time.
How AWS implements Inbound TE
To solve the Inbound TE problem, AWS developed a suite of automated tools and operator-driven processes across all AWS commercial Regions, as shown in the following figure. The new toolset includes software-defined networking (SDN) controllers that analyze network telemetry to identify opportunities for traffic flow improvement and decide which prefixes to steer and which TE actions to apply. It also includes BGP speakers that inject routes into transit-layer devices to steer traffic away from overloaded links, along with APIs that let operators influence the controller’s behavior. The toolset further offers semi-automated workflows so that operators can manually intervene in edge cases where fully automated TE might not be safe. These operator-driven processes were essential in helping us iteratively validate our steering strategies across a range of real-world scenarios before advancing automation further. This approach gave us a deeper understanding of risks to both users and peer networks, allowing us to build a safer, data-driven, always-on Inbound TE system that replaced older mitigation methods with faster, more consistent, and reliable traffic engineering actions.
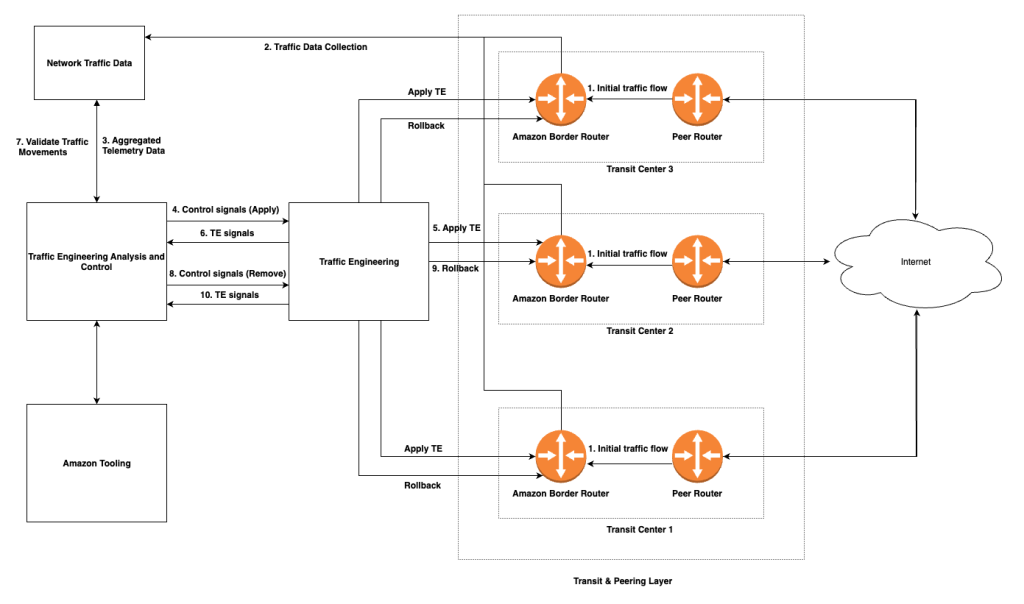
Figure 2: Inbound TE design
The controller supports two types of TE actions. The first is Autonomous System (AS) PATH prepending, which makes a route less preferred by artificially increasing the AS PATH length. While AWS implements this action, peer or downstream networks may not honor the prepended paths due to their internal configurations. In the second type of Inbound TE action, the controller withdraws the prefix from the congested session altogether that forces the peer network to reroute traffic through an alternate path. This is useful for peer networks that have their own congestion mitigation strategies and may request that we avoid certain actions that could interfere with their routing logic.
To address the non-deterministic nature of Inbound TE, the controller is designed to make fast and atomic changes in the network, steering only the minimum number of prefixes necessary and quickly iterating until the issue is resolved. It operates with a closed feedback loop that actively monitors traffic shifts, detects any impairments caused by changes, and automatically rolls back actions if negative impact is observed. This makes sure that mitigations are both effective and safe.
Impact of Inbound TE
AWS continues to build on this strong foundation by further reducing response times and expanding the capabilities of our automated traffic engineering system. Inbound TE operates silently at massive scale, preventing over a thousand congestion events every month across the AWS global network. Our users don’t need to design complex architectures to make sure that their workloads are transmitted without interruption. We build and operate a reliable network that does that for them. Proactively detecting and mitigating issues before they impact performance allows us to make sure of a more stable and seamless experience for all. Our mission is clear: to make the internet faster and more secure.
Conclusion
In this post we explained how AWS manages and responds to events with Inbound TE. We highlighted our unique approach, how it has improved our time to response, and the benefits of doing this on behalf of our users. In a future post we discuss how we automate Outbound TE to make sure of the best possible experience for users’ workloads that send traffic out to the internet from AWS. If you have questions about this post, then start a new thread on AWS re:Post, or contact AWS Support.
About the authors

Reza Hedayati
Reza is a Software Development Manager at Amazon Web Services. He works within AWS Infrastructure on Internet Edge Services, focusing on software-defined networking controllers and operational tooling that provide customers with a seamless experience when accessing their resources in AWS.

Camden Forgia
Camden Forgia is a Principal Product Manager for Amazon Leo focused on delivering the best connectivity experience using Amazon Leo’s constellation of low-earth orbit satellites. Previously, he was a product manager in Amazon Web Services (AWS) focused on building and launching products that deliver the AWS global network infrastructure in novel ways for AWS customers. He was the product manager for external services such as AWS Data Transfer Services and AWS Data Transfer Terminal. Camden has led operations and product management over 10 years for technology companies ranging from semiconductor to cloud to satellite networking.