Networking & Content Delivery
Identifying unhealthy targets of Elastic Load Balancer
Introduction
The Elastic Load Balancing (ELB) service provides you with Amazon CloudWatch metrics (HealthyHostCount and UnhealthyHostCount) to monitor the targets behind your load balancers. Although the unhealthy host count metric gives the aggregate number of failed hosts, there is a common pain point when you create an alarm for unhealthy hosts based on these metrics. This is because there is no easy way for you to tell which target was or is unhealthy. The easiest way for you to identify an unhealthy host is to check all of your targets and see which one stops receiving new requests. This blog post proposes an AWS serverless solution to help you identify the unhealthy target of a load balancer.
In this post, we will demonstrate how to use an AWS Lambda function to identify unhealthy targets and send an email notification that includes the load balancer name, Region, AWS account, timestamp, failed target IDs, HealthyHostCount, and cause of failure. The unhealthy targets are listed in JSON format so it’s easy to consume and conduct further processing. Also, the Lambda function can run an “OnDemandHealthCheck”, which sends a health check to the targets that went unhealthy, and reports if they’re pass or fail, and why. This offers a direct view of the cause of health check failure. This offers a direct view of the cause of health check failure. This solution supports all load balancer types including Classic Load Balancer (CLB), Application Load Balancer (ALB), and Network Load Balancer (NLB).
Solution overview

When a target fails an ELB health check, it triggers a CloudWatch alarm whose alarm action sends an Amazon Simple Notification Service (SNS) notification to trigger a Lambda function. The Lambda function makes a describe-load-balancer or describe_target_groups API call to get the identity of the failed target as well as the cause of the failure.
At the same time, the Lambda function puts the data points that it collects from the API call to a custom CloudWatch metric. For example, the metric below shows that 2 out of 4 targets of a load balancer failed health check. As you can see, we can quickly get the information such as timestamp, instance ID, and load balancer name from this metric.

In addition, you can also search the CloudWatch log stream of your Lambda function to find out if an instance failed an ELB health check at any time.

Getting Started and setup
We’ll go over two ways to set up this solution: first, by using the AWS Management Console, and then by using AWS CloudFormation.
The Lambda function zip package is available here. Let’s dive in!
Setting it up using the AWS Management Console
STEP 1: Create an IAM policy
In the IAM console, create an IAM policy with the permissions required by the Lambda function. You can find the sample IAM policy in Appendix A. To learn more, see the documentation for Creating IAM Policies. To learn how to create an IAM role for AWS Lambda see the documentation for Creating a Role for an AWS Service (Console).

STEP 2: Create an IAM role
After the IAM policy is ready, we need to create an IAM role for the AWS Lambda service to assume. Make sure to select Lambda as the service that is going to use this IAM role.

Attach the IAM policy that we created in Step1.

STEP 3: Create the first SNS topic
Create the first trigger SNS topic that we are going to use as an action for the CloudWatch alarm that we are going to create in Step 5. We use this SNS topic to trigger the Lambda function that we are going to create in Step 6. To learn how to create an SNS topic see the documentation for Create a Topic (Console). To learn more, see the documentation for Invoking Lambda functions using Amazon SNS notifications.

STEP 4: Create the second SNS topic
Create the second SNS topic. We use the second SNS topic to send notifications to its subscribers of the unhealthy targets’ details.

STEP 5: Create a CloudWatch Alarm
Create a CloudWatch Alarm and configure the alarm action to send notifications to the second SNS topic created in Step 4. Taking Classic Load Balancer as an example, we select the UnHealthyHostCount metric of the load balancer, choose a load balancer — “demo-public”, and choose Next.
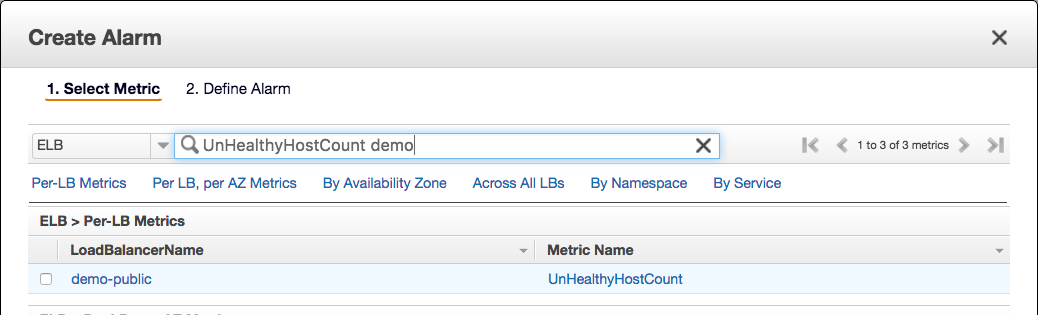
Set the threshold of the CloudWatch Alarm to equal or larger than three. Configure the alarm period to be 1 minute and the statistic to maximum. With this configuration, an alarm will be triggered when UnHealthyHostCount is equal to or greater than 1 for three consecutive evaluate period(s), which is 3 minutes. You can always adjust this configuration based on your use case. Smaller threshold and shorter alarm periods make the alarm more sensitive.
Now, let’s add a send notification action for this alarm by selecting the first SNS topic that we created in Step 3.

To learn more, see the documentation for Creating Amazon CloudWatch Alarms. You can find the sample CloudWatch Alarm configuration in Appendix B.
STEP 6: Create a Lambda function
Open the AWS Lambda console to create the Lambda function. While creating the function, make sure to select the IAM role that we created in Step 2. Set the Runtime environment to Python2.7.

STEP 7: Configure the Lambda function
Change the handler name to identitying_unhealthy_targets.lambda_handler so that AWS Lambda can pick up the Python file that contains the function code. Then choose the Upload button and upload the Lambda function zip file.

Now, let’s add the event source for the Lambda function. The event source is the CloudWatch alarm that we created in Step 5.

After we see the function code on the Lambda console, add the following environment variables to the Lambda function.
- ONDEMAND_HEALTHCHECK – Whether the Lambda function should send a health check request when it detects an unhealthy target
- SNS_TOPIC – The SNS ARN which sends notification of unhealthy targets
- TARGETGROUP_ARN – The ARN of the target group (ALB or NLB only)
- TARGETGROUP_TYPE – The type of the target group, for example, Instance or IP (ALB or NLB only)
- NAMESPACE – The namespace of ELB, for example, AWS/ELB, AWS/ApplicationELB or AWS/NetworkELB
Environment Variables of Classic Load Balancer

Environment Variables of Application/Network Load Balancer

To make OnDemandHealthCheck work, we need to configure the Lambda function to access the load balancer in your VPC. Therefore, we need to add the Lambda function to our VPC by associating subnets. In addition, since our Lambda function needs to talk to AWS service endpoints such as CloudWatch endpoint, SNS endpoints, our subnets need to have a default route to a NAT gateway or NAT instance. Now, we need to associate a security group to our Lambda function to make sure it can send health check requests to our load balancer.

Setting it up using AWS CloudFormation
This blog post provides two CloudFormation templates for monitoring Classic Load Balancer (known as elb in the AWS CLI/SDK) and Application/Network Load Balancer (known as elbv2 in AWS CLI/SDK). Both templates create the following AWS resources to monitor and send a notification when a target fails a load balancer health check along with the cause of failure.
- Two SNS topics (one for triggering the Lambda function and one for sending a notification)
- A Lambda function
- An IAM role for the Lambda function
- A CloudWatch Alarm
- A new customer CloudWatch metric
STEP 1: Download the CloudFormation template
The CloudFormation template for Classic Load Balancer is available here.
The CloudFormation template for Application/Network Load Balancer is available here.
In the CloudFormation console, choose the Launch Stack button below to launch a monitor utility stack in the US East (N. Virginia) Region.
To launch a monitor stack for Classic Load Balancer
![]()
To launch a monitor stack for Application/Network Load Balancer
![]()
STEP 2: Create CloudFormation Stack
After you download the CloudFormation templates, in the CloudFormation console, under Choose a template, choose Browse, and select the template based on your load balancer type.
After selecting the template, we need to add the following parameters to the CloudFormation stack. The following screenshot shows the required parameters for the Application/Network Load Balancer (elbv2) template:
- Stack name– Name of the CloudFormation stack
- Email – The email address that you want to be notified of any unhealthy target event
- CloudWatchAlarmName – Name of the CloudWatch alarm used for monitoring Unhealthy Targets
- LoadBalancerName – Name of the load balancer that you want to monitor. If it is an NLB or ALB, the name should look like — net/lbname/d665cae1604417d or app/lbname/d665cae1604417d
- Namespace – Namespace of the load balancer type
- OnDemandHealthCheck – Option to turn on on-demand health check
- Region – Region of where you want to create Lambda function
- Namespace – Namespace of the load balancer type
- TargetGroupARN – ARN of the target group that you want to monitor. For example, arn:aws:elasticloadbalancing:us-east-1:1111111111:targetgroup/my-tg/83b692961bdc9a81
- TargetGroupType – Type of the target group
- VPCSecurityGroupIDs – A comma-delimited list of strings – the security groups that your Lambda function will use. The security groups need to allow Lambda to communicate with your ELB. For example, sg-b23fb7d7,sg-af5fd2ca
- VPCSubnetIDs – A comma-delimited list of strings – the subnet IDs that your Lambda function should be assigned to. The subnets need to be part of your ELB’s VPC. They need to have a default route to NGW or NAT instance so that the Lambda function can access the Internet. For example, subnet-a7926688,subnet-878974cf

In the following pane, check Acknowledge access Capabilities to allow CloudFormation to create or update IAM resources.

Choose Create Change Set to create the resources added by transforms.

Next, you will see the following list of AWS resources added to your CloudFormation stack.

Verification
Let’s use Application Load Balancer as an example. We are going to purposely make one target fail its ELB health check by changing the permission of the application home page on one target instance. Then we’ll verify if we get a notification of this failure. After that, we’ll take a look at the customer CloudWatch metric and check if it captures this failure.
The ELB health check is configured as follows:
- Response Timeout: 5 seconds
- Interval: 30 seconds
- Unhealthy Threshold: 2
- Healthy Threshold: 2
If a target fails two consecutive ELB health checks, which is 60 seconds, it will be marked as unhealthy. As you can see in the following example screenshot, initially all four targets are healthy.

Then, after I removed the read permission of the health check page – index.html on instance — i-0081135f04b0e4b23, it became unhealthy.

At 5:27 PM, which is about 3 minutes after the instance became unhealthy, I received the email notification —

As you can see, the notification explained why the target failed the ELB health check. In this case, it was due to “Health checks failed with these codes: [403],” which is what I expected.
Now, let’s take a look at the CloudWatch metric.

As you can see, out of four targets, target — i-0081135f04b0e4b23 entered the unhealthy state at 17:26 PM PST.
I also turn on “OnDemandHealthCheck” and repeat the verification process above on a Classic Load Balancer and I receive an email notification —

As you can see that the Lambda function sends an on-demand health check request and receives HTTP 403 status code while the expected HTTP status code is 200.
Conclusion
The setup outlined in this blog post provides timely information by giving you more visibility into unhealthy targets as well as logging it for future reference. This solution delivers alerts and notifications triggered by a CloudWatch alarm based on the ELB UnhealthyHostCount metric, so you get rapid notification of events to help accelerate troubleshooting.
Notes
- We use the UnhealthyHostCount instead of HealthyHostCount metric to monitor the load balancer’s target state because you might see drops in HealthyHostCount while all targets are actually in the healthy state. For example, when you deregister any targets.
- You need to create the CloudFormation stack in the same Region as the load balancer that you want to monitor.
- The default threshold of CloudWatch alarm is reached when UnHealthyHostCount is equal to or greater than 1 for three consecutive evaluation periods, with the alarm period set to 1 minute. You can always adjust this configuration based on your use case.
- AWS service costs apply to the resources created by the CloudFormation template. So after you complete this exercise, you can delete the CloudFormation stack. For more information, see Deleting a Stack on the AWS CloudFormation Console
- The CloudFormation template for AWS/ApplicationELB or AWS/NetworkELB only creates an alarm for one target group. However, you can always create more CloudWatch alarms for other target groups that you want to monitor and associate them to the same SNS topic to the Lambda function.
- OnDemand SSL/HTTPS HealthCheck does not check the cipher suite used by the targets. Therefore, there is a chance where OnDemandHealthCheck reports healthy while the targets actually fail ELB health check. If you encounter this issue, please contact AWS support.
— Long;
Appendix A – IAM policy
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "LambdaLogging",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": ”*"
},
{
"Sid": "SNS",
"Action": [
"sns:Publish"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Sid": "EC2",
"Action": [
"ec2:CreateNetworkInterface",
"ec2:Describe*",
"ec2:AttachNetworkInterface",
"ec2:DeleteNetworkInterface"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Sid": "ELB",
"Action": [
"elasticloadbalancing:Describe*"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Sid": "CW",
"Action": [
"cloudwatch:putMetricData"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
Appendix B – CloudWatch Alarm configuration
{
"EvaluationPeriods": 3,
"AlarmArn": "arn:aws:cloudwatch:us-east-1:YOURACCOUNT:alarm:demo-alarm",
"StateUpdatedTimestamp": "2018-05-11T17:55:25.053Z",
"AlarmConfigurationUpdatedTimestamp": "2018-05-11T17:55:25.053Z",
"ComparisonOperator": "GreaterThanOrEqualToThreshold",
"AlarmActions": [
"arn:aws:sns:us-east-1:YOURACCOUNT:demo-AlarmTriggerTopic-GEI986OJ63NJ"
],
"AlarmDescription": " Alarms when there is any unhealthy target",
"Namespace": "AWS/NetworkELB",
"Period": 60,
"StateValue": "INSUFFICIENT_DATA",
"Threshold": 1.0,
"AlarmName": "identifying_unhealthy_targets",
"Dimensions": [
{
"Name": "TargetGroup",
"Value": "targetgroup/demo/2bd9bf15038f8ed3"
},
{
"Name": "LoadBalancer",
"Value": "net/demo/d665cae1604417dc"
}
],
"Statistic": "Maximum",
"StateReason": "Unchecked: Initial alarm creation",
"InsufficientDataActions": [],
"OKActions": [],
"ActionsEnabled": true,
"MetricName": "UnHealthyHostCount"
}
Appendix C – Notification format
=Subject= Region + Alarm + ELB/TargetGroup name =Content= Account Timestamp Region ELB/TargetGroup name Unhealthy Registered Targets and the cause of failure OnDemand Health Check Result (optional)
Sample email of Application/Network Load Balancer:
US-EAST-1 Alarm: unhealthy registered targets of ELB -- applicationloadbalancer-name
Account: account-id
Timestamp: 2018-05-04T00:36:43.384+0000
Region: us-east-1
ELB: applicationloadbalancer -name
Unhealthy Registered Targets and Cause of Failure:
{u'HealthCheckPort': '80', u'Target': {u'Id': 'i-00000000000000001', u'Port': 80}, u'TargetHealth': {u'State': 'unhealthy', u'Reason': 'Target.ResponseCodeMismatch', u'Description': 'Health checks failed with these codes: [503]'}}
Appendix D – Lambda testing file
Classic Load Balancer:
{
"Records": [
{
"Sns": {
"Message": "{ \"AlarmName\": \"uhh\", \"AlarmDescription\": \"YourAlarmDescription\", \"AWSAccountId\": \"YourAcclountID\", \"NewStateValue\": \"ALARM\", \"NewStateReason\": \"Threshold Crossed: 1 datapoint [3.0 (03\/08\/17 22:17:00)] was greater than or equal to the threshold (1.0).\", \"StateChangeTime\": \"2017-07-31T22:18:08.421+0000\", \"Region\": \"US East - N. Virginia\", \"OldStateValue\": \"OK\", \"Trigger\": { \"MetricName\": \"UnHealthyHostCount\", \"Namespace\": \"AWS\/ELB\", \"StatisticType\": \"Statistic\", \"Statistic\": \"MAXIMUM\", \"Unit\": null, \"Dimensions\": [ { \"name\": \"LoadBalancerName\", \"value\": \"YourLoadBalancerName\" } ], \"Period\": 60, \"EvaluationPeriods\": 3, \"ComparisonOperator\": \"GreaterThanOrEqualToThreshold\", \"Threshold\": 1, \"TreatMissingData\": \"- TreatMissingData:NonBreaching\", \"EvaluateLowSampleCountPercentile\": \"\" } }"
}
}
]
}
Application/Network Load Balancer:
{
"Records": [{
"Sns": {
"Message": "{ \"AlarmName\": \"YourAlarmName\", \"AlarmDescription\": \"YourAlarmDescription\", \"AWSAccountId\": \"YourAcclountID\", \"NewStateValue\": \"ALARM\", \"NewStateReason\": \"Threshold Crossed: 1 datapoint [1.0 (04/08/17 00:35:00)] was greater than or equal to the threshold (1.0).\", \"StateChangeTime\": \"2017-08-04T00:36:43.384+0000\", \"Region\": \"US East - N. Virginia\", \"OldStateValue\": \"OK\", \"Trigger\": { \"MetricName\": \"UnHealthyHostCount\", \"Namespace\": \"AWS/ApplicationELB\", \"StatisticType\": \"Statistic\", \"Statistic\": \"MAXIMUM\", \"Unit\": null, \"Dimensions\": [ { \"name\": \"TargetGroup\", \"value\": \"YourTargetGroupName\" }, { \"name\": \"LoadBalancer\", \"value\": \"YourLoadBalancerName\" } ], \"Period\": 60, \"EvaluationPeriods\": 3, \"ComparisonOperator\": \"GreaterThanOrEqualToThreshold\", \"Threshold\": 1, \"TreatMissingData\": \"- TreatMissingData:NonBreaching\", \"EvaluateLowSampleCountPercentile\": \"\" } }"
}
}]
}
About the Author

| Blog: Using AWS Client VPN to securely access AWS and on-premises resources | ||
| Learn about AWS VPN services | ||
 |
Watch re:Invent 2019: Connectivity to AWS and hybrid AWS network architectures |