AWS Open Source Blog
Announcing the Simple Database Archival Solution
Today, we are excited to announce the release of the Simple Database Archival Solution (SDAS). SDAS is an open source solution available under Apache License 2.0, which you can deploy in your AWS account to archive data to AWS. SDAS provides organizations with an efficient, easy and cost-effective solution for archiving Oracle, Microsoft SQL, and MySQL databases.
SDAS addresses a common problem faced by many AWS customers, which is the need to efficiently and securely archive data from their databases. Many organizations are required to retain data for long periods, and storing this data on-premises can be costly and complex. Additionally, cloud adoption is becoming more prevalent, and customers often need a solution to easily transfer data from their cloud-hosted databases to the cloud for long-term storage.
SDAS offers a differentiated solution by providing an easy-to-use, open source tool that can be deployed directly into customers’ AWS accounts. With SDAS, customers can quickly and easily map the schema of their database, perform validation, and transfer data to Amazon Simple Storage Service (Amazon S3) for storage. This is accomplished using AWS Step Functions, AWS Glue, Amazon S3, and Amazon Athena which provide a highly scalable and reliable solution for transferring data.
With its open source approach, SDAS offers customers a high degree of flexibility to customize and extend the solution to meet their unique requirements. This level of flexibility ensures that the solution can be adapted to the specific needs of any organization, regardless of their size or industry.
What is Simple Database Archival Solution (SDAS)?
As businesses accumulate more and more data over time, the need for effective database archiving solutions has become increasingly important, for example moving older, rarely used data to an archive. Businesses can reduce the size of their active databases, which can improve performance and reduce storage costs. Archiving can also help organizations meet legal and regulatory requirements for data retention, as well as ensure that important data is available for future use and discovery, if necessary. Out of the box, SDAS provides the following key features:
- Support Oracle, MySQL or Microsoft SQL Server
- Identify the data type and table schema
- Validate the data on the target after the archiving process has completed
- Configure WORM (“Write Once Read Many”)
- Define a data retention period for the data
- Provide detailed information about the status of the data
- Perform various data validation and integrity checks
- Make it simple for operations to ingest and archive a database
- Preview data archived in Amazon S3
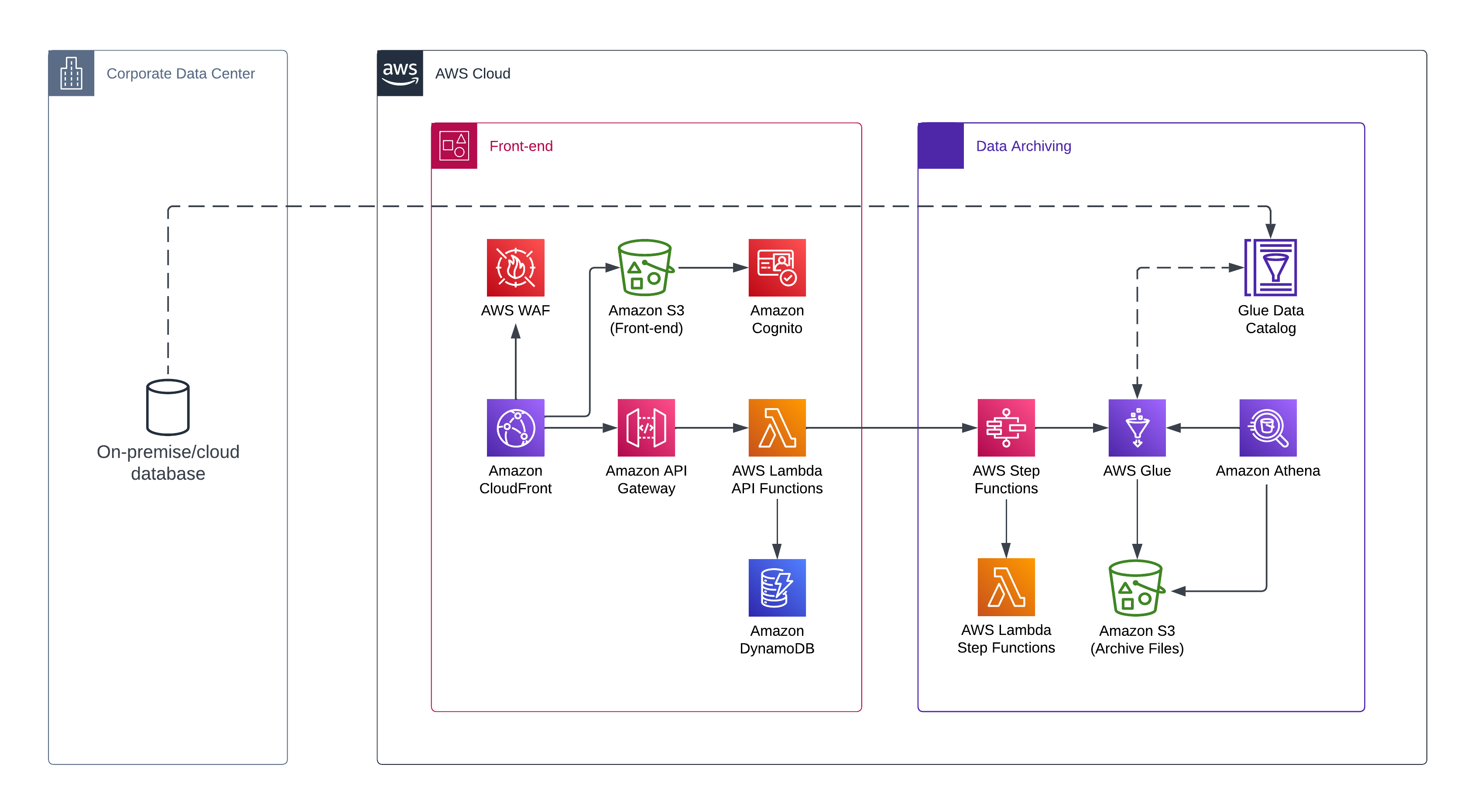
SDAS Architecture
SDAS is a solution that provides customers with a robust and scalable mechanism for archiving databases to AWS. SDAS has an intuitive front-end interface as its core, enabling users to easily manage and configure their archives. The front-end is built using the CloudScape Design Framework, a powerful and flexible framework for developing web applications. This front-end is supported by several key AWS services, including Amazon Cognito for authentication and authorization, API Gateway with Amazon Lambda functions for user operations, and Amazon S3 for storing the front-end build files.
Amazon Cognito is a fully managed service that provides user authentication and authorization, making it easy to secure user access to web and mobile applications. It supports several authentication methods, including social identity providers such as Facebook, Google, and Amazon, as well as enterprise identity providers via SAML 2.0. With Cognito, users can easily sign up, sign in, and manage their own profiles and settings, without the need for complex user management infrastructure.
API Gateway is a fully managed service that provides a secure, scalable, and reliable API for interacting with SDAS’s front-end interface. It enables users to easily integrate SDAS with other AWS services or third-party applications, while also providing features such as authentication, and authorization. Supporting Lambda functions are used to provide serverless compute resources for user operations, enabling SDAS to easily handle varying levels of traffic and user load. Finally, Amazon S3 is used to store the front-end build files, providing a highly durable and scalable object storage service that is optimized for use with AWS applications.
The SDAS platform also includes Amazon DynamoDB, which serves as the primary storage mechanism for archive metadata. DynamoDB provides a highly scalable and durable NoSQL database that is optimized for high-volume workloads. Additionally, the solution leverages AWS Secrets Manager to securely store passwords and other sensitive information.
Archiving of data is performed using AWS Glue, a fully managed ETL service that enables customers to extract, transform, and load data from a variety of sources. SDAS includes pre-built Spark Python scripts that are used to transform the data before archiving it to Amazon S3. The archived data is stored in Parquet file format, which is optimized for query performance and storage efficiency.
Finally, to provide users with an easy-to-use interface for querying archived data, SDAS leverages Amazon Athena. Athena is a serverless query service that allows users to query data stored in S3 using SQL. By using Athena, users can quickly and easily perform ad-hoc analysis on their archived data without the need for complex setup or maintenance.
In summary, SDAS provides a comprehensive solution for archiving databases to AWS that leverages several key AWS services to enable reliability, scalability, and security. The solution is highly customizable and can be tailored to meet the specific needs of individual customers. With its intuitive front-end and powerful back-end architecture, SDAS is an ideal solution for organizations looking to simplify the process of archiving their data to the cloud.
Sample Use Case
A health care and life sciences company needs to decommission a Microsoft SQL database as it is associated with a legacy application that is no longer in use. The database contains important historical data that the company needs to retain. Maintaining the database up and running incurs significant costs, including licensing, maintenance, and hardware expenses and it is no longer being required by day-to-day business operations. To address this challenge, the company decides to decommission the Microsoft SQL database and archive its data to AWS using SDAS.
By archiving the data with SDAS, the company can take advantage of lower storage costs, better data durability, and easy accessibility for analysis and reporting. The business impact of this decision includes:
Cost Savings: Decommissioning the Microsoft SQL database reduces expenses related to licensing, maintenance, and hardware. This frees up resources that can be allocated to more critical business initiatives.
Simplified Data Management: By consolidating the historical data in Amazon S3, the company streamlines its data management processes. This makes it easier to perform data analysis and generate reports when needed, without the complexity of managing a legacy database.
Security: AWS offers advanced security features, such as encryption and access controls, helping the company protect its sensitive historical data.
Scalability: As the company continues to grow, Amazon S3’s scalable storage solution enables them to store and manage increasing amounts of data without worrying about capacity constraints.
By archiving the Microsoft SQL database to Amazon S3 using SDAS, the health care and life sciences company can effectively balance the need to preserve important historical data with the desire to optimize operational costs and improve overall data management.
Steps to Archive a Database with SDAS: A Comprehensive Solution for AWS Customers
Start and Discover
To start the archiving process, gather essential connection information, including the database name, database URI, and credentials. With this information, SDAS attempts to connect to the database, and if successful, proceeds to the next step. In the next step, SDAS collects the tables and associated schema from the target database to be archived.

Figure 1: Screenshot view of SDAS connecting to the Source Database.
To identify the data that needs to be archived, SDAS uses a technique to scan the metadata associated with the table. This process is designed to accurately identify the data type and schema of the table and ensure that the data is properly formatted and validated before being transferred to AWS. The process involves running multiple SQL queries to extract the database schema definition to allow AWS Glue to read and finally write the data to Amazon S3.
Once the data type and schema of the table have been identified, SDAS can begin the process of transferring the data to AWS.

Figure 2: Screenshot view of SDAS performing a scan as well as gathering the database schema definition.
Archive
The archive phase of SDAS is a critical step in the process of archiving data to Amazon S3. SDAS is designed to automatically archive data from Oracle, Microsoft SQL, and MySQL databases, providing flexibility and versatility for customers. The archiving process can be triggered either manually or automatically based on a defined schedule, enabling customers to customize the solution to their specific needs.

Figure 3: Screenshot view of SDAS starting an archive process.
At the core of the archive phase is AWS Glue, a fully managed Extract, Transform, and Load (ETL) service that provides a flexible and scalable solution for copying the database from the source to the target. SDAS leverages the power of AWS Glue to perform necessary transformations on the data, including data cleaning and schema transformations, ensuring that the data is properly formatted and validated before being transferred to Amazon S3.
Once the data is transferred to Amazon S3, it is stored as Parquet files, a columnar storage format that is optimized for query performance and storage efficiency. This makes the archived data easy to query, for instance using Amazon Athena, a serverless query service that allows customers to query data stored in S3 using SQL. By leveraging the power of Amazon Athena, customers can easily perform ad-hoc analysis on their archived data without the need for complex setup or maintenance.

Figure 4: Screenshot view of the AWS Glue jobs running which copies the data from the source to Amazon S3.
Data Validation
The data validation phase of SDAS is a critical step that ensures the accuracy and completeness of the archived data. After the archival process is complete, SDAS automatically triggers a validation process to ensure that the data has been properly transferred and stored in Amazon S3.
The validation process begins by comparing the source data to the archived data stored in Amazon S3, using a variety of techniques such as checksums, and data sampling. This process ensures that the data has been accurately transferred and stored, with no data loss or corruption. SDAS does not perform validation on the source data, only on the data stored in Amazon S3.
If any discrepancies are detected, SDAS provides you with the ability to identify the affected table. In addition to ensuring the accuracy of the archived data, SDAS also provides security features to protect against unauthorized access or modification of the data. Passwords are stored in AWS Secrets Manager, which provides a highly secure mechanism for storing and managing secrets, such as database passwords.

Figure 5: Screenshot of the validation processes performed on the target data.
Access to Archived Databases
Access to the archived databases in SDAS is limited to authorized users who can access them through the Amazon Athena Console. To explore and visualize the data using Business Intelligence tools, users can download, install, and configure either an ODBC (Open Database Connectivity) or JDBC (Java Database Connectivity) driver to connect to Amazon Athena.
SDAS also includes a preview mode through the console, which allows users to quickly view the database that has been archived without the need for additional drivers or tools. This preview mode provides users with a quick and easy way to assess the quality and completeness of the archived data before proceeding with further analysis or querying.

Figure 6: Screenshot of the Data Preview feature in SDAS
Object Lock
SDAS includes a powerful feature that enables users to enable Amazon S3 Object Lock, a feature that allows objects to be stored using a WORM (Write Once, Read Many) model. This feature is designed for use in scenarios where it is critical that data is not modified or deleted after it has been written.
By enabling Amazon S3 Object Lock, users can ensure that their archived data is fully protected from accidental or malicious deletion or modification. This feature provides a powerful layer of security that helps to prevent data loss or corruption, ensuring that the archived data remains complete and accurate for future analysis and querying.

Figure 7: Screenshot of the Object Lock feature
Give SDAS a try!
1. Install the Simple Database Archival Solution in your AWS Account.
2. Send any issues, improvements, or suggestions to us at our GitHub page.
3. To help you get started, we have also published a self-guided workshop that walks through the installation and core features of SDAS. Thank you to James Gaines for their support in building the workshop.
Conclusion
The Simple Database Archival Solution (SDAS) offers organizations a comprehensive open source solution for archiving various types of databases, including Oracle, Microsoft SQL, and MySQL. With SDAS, businesses can easily and cost-effectively archive, validate, and securely store their data in Amazon S3. SDAS also provides users with various options for accessing and analyzing their archived data, making it a valuable tool for data analysis and reporting.
Additional thanks to Rohit Jagetia, Joe Cangialosi, James Gaines, and Duverney Tavares for their work on this solution.