AWS Open Source Blog
Raising Helm – to Enterprise Scale
A typical application deployed to Kubernetes consists of multiple manifests such as Deployment and Service for each microservice. Deploying these individual manifests can be challenging – this is where package managers like Helm come to the rescue. This post from Baruch Sadogursky of JFrog provides a status update on what is being done to make Helm enterprise-ready, and how you can contribute to it.
– Arun
TL/DR: Package managers in general are awful, but Helm, the package manager of Kubernetes, is… not bad at all. Of the seven deadly sins of package managers, Helm commits only two, and these are easily fixable. We’ll be explaining how below. We aren’t quite there yet, but you can expect Helm to become enterprise-ready in the future. Better yet, you can help! Read on for how.
This blog post is not about getting started with Helm. For that, please see the Helm website, which has excellent documentation. Instead, let’s talk about some Helm design and implementation decisions, what’s right, what’s lacking and how we can fix it.
What package managers and printers have in common
You probably know from experience (and from the Oatmeal) that printers were sent to us from hell to make us all miserable. So were package managers. Sam Boyer worked on one of the Go package manager implementations and summarized the problem with both writing and using package managers perfectly in his post “So you want to write a package manager.”
Generally, what we have learned at JFrog over more than a decade of dealing with package managers is that every package manager suffers from at least one (but usually more) of what we call the Seven Deadly Sins of Package Managers:
- Over-architecture
- Lack of planning for enterprise scenarios (e.g., no private repositories, won’t scale, etc.)
- Downloadable index
- CSDR (cross-site dependency resolution) loopholes
- Lack of proper package authentication
- Lack of version management
- Using the wrong service for the central registry (and hard-coding it)
Helm is more than OK!
We like Helm a lot. It successfully avoids most of the above problems. It is simple (#1), the dependencies are versioned (#6), arbitrary URLs aren’t allowed (#4), the authors are authenticated by their public identity (#5), and the central repository is implemented using blob storage (#7). All good – almost.
No authentication? That’s not “enterprise ready”!
There is a point in your scaling journey when you need to know who deployed and downloaded what, and when you want to start granting access to certain people and machines to do or not to do certain things. By the time things break, it’s usually too late.
Until recently, you couldn’t do that with Helm. Although you can easily spin up your own private repo inside your network, which works for a small team for a while, but won’t suffice for a serious development organization, especially with cross-team dependencies and sharing. Maintain a separate installation for each and every team to enforce some kind of separation? The lack of cross-team metadata and the maintenance overhead are serious impediments.
The Fix: Provide Credentials
The Helm accepted our pull request which fixed the problem. Starting from Helm 2.9, you can pass `–username` and `–password` to the repository, which will take care of enforcing authentication, and eventually, authorization, based on those credentials.
More Charts, More Problems
With this problem behind us, we are now addressing the downloadable index problem. First, why is it even a problem? Isn’t it good to be able to perform offline searches? We think that a downloadable index, though utterly justifiable when first invented, now creates more problems that it solves. It used to be difficult to perform centralized concurrent searches, but now (ask Google) that isn’t the case anymore, is it?
Your mobile phone has more computing power than all of NASA in 1969. NASA launched a man to the moon. We launch a bird into pigs.
— George Bray (@GeorgeBray) March 22, 2011
So let’s say you’re enjoying the off-line search. You downloaded the latest index (it is continuously updated on the server, so your local index continually becomes obsolete), found a place without Internet (I used to say “got on the plane,” but even that doesn’t work anymore), run a chart search, and found a fantastic chart. Now what? You still can’t download the chart.
Also, did I mention that your local index is probably out of date, and you need to update it every time you want to search?
So here we come to the real problem with Helm index implementation: scalability. Helm has one index file for the entire repository. It contains a list of all the charts, the metadata about each chart, the list of all the versions for each chart, and the metadata about each version. That’s a lot of text,and much duplication. We ran some benchmarks, and they don’t look good when you have many charts:

As you can see, the memory consumption of the client parsing the downloaded index skyrockets when you have many charts, and that’s due to some issues:
- The client parses the YAML file, creates a JSON object out of it, and works with that.
- One index for everything. It’s just huge.
- There are tons of duplications. Metadata for each version repeats itself.
Let’s examine some of the actions that can be taken to fix the problem:
Fix #1 – Compress
Let’s gzip the index in transit. It won’t help the processing time (actually, the unzipping will add to the processing time), but it will dramatically shrink the size of the index in transit (by an order of magnitude, actually). But, hey, didn’t we say we’d reduce the processing load?! We’ll get to that in a second, but be aware that, no matter what anyone says, latency still exists. If we can reduce the payload size tenfold with such an easy fix, let’s do it!
Now back to reducing the processing time and load.
Fix #2 – Stop Converting Too Much
Let’s not transfer in YAML and then convert to JSON. We get that JSON is easier to parse than YAML, so maybe we should just transfer a gzipped JSON to begin with.
Fix #3 – Divide and Conquer
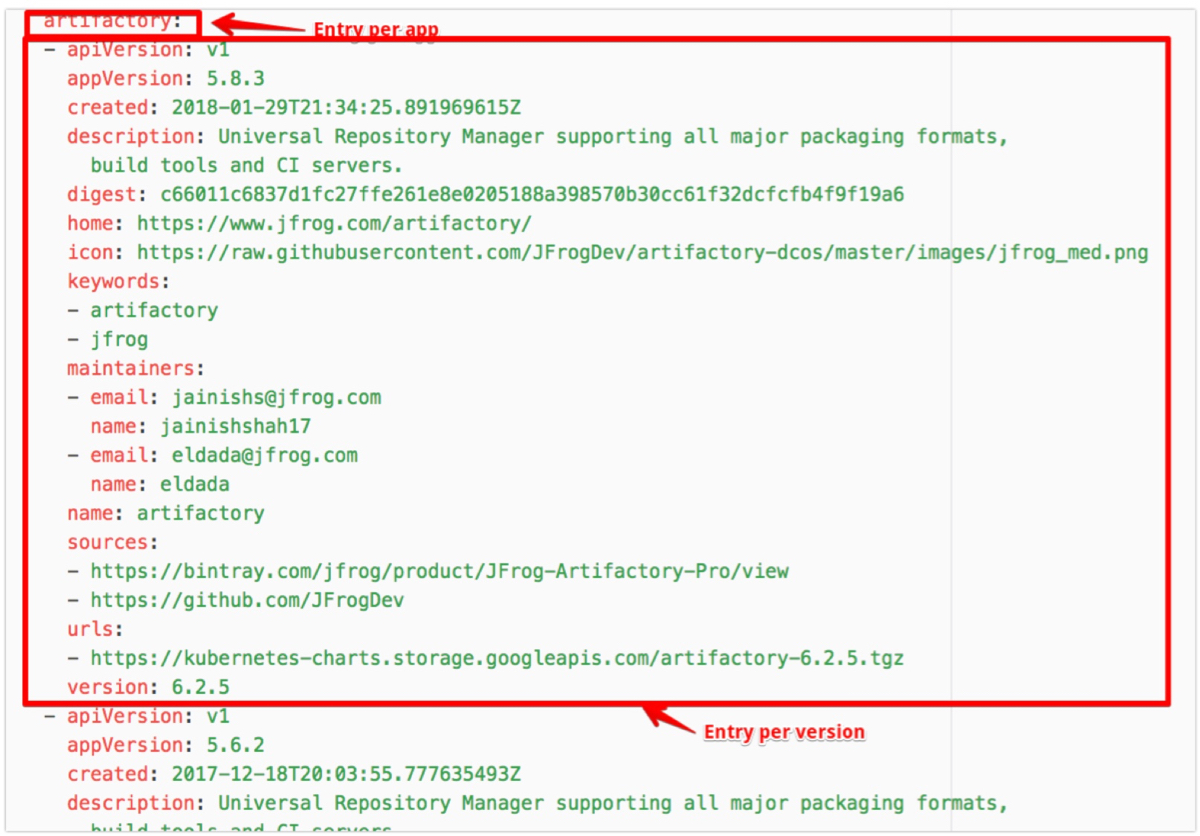
Let’s break down the index into a structure that will allow downloading and parsing it in tiny bits, instead of downloading and parsing one massive file:
- Main index: list of apps (with the latest version)
- `artifactory:5.8.3`
- App index: list of versions (and app-level metadata)
- `description`
- `maintainers`
- `keywords`
- `sources`
- Version index: the details of the version
- `appVersion`
- `created`
- `digest`
- `url`
To search for a chart, you only need to download and parse the top level index which, since it doesn’t contain any metadata, is small. To describe a chart and get the list of versions, other than the latest, only the app index needs to be downloaded and parsed. This is small because it only contains metadata about one chart, plus a list of versions. And, finally, when we want to download a chart, we’ll download and parse the metadata about that particular version of the chart, with the URL to download, a digest to verify, etc.
Welcome to layouts
We have just created ourselves a complication. Such a divided index requires a repository layout. Having a bunch of tar.gz and one YAML index in the root won’t cut it anymore. Now we need something like this:
repo
|---app
|---ver1
|---ver2
It’s not a big deal, the Helm repo client should encapsulate the repository structure, while the search, retrieve and push commands should be repo aware, right? However, Helm never had a push command. This wasn’t a problem since, without a layout, any curl upload does the right thing – you could just HTTP post the chart into the root of the repo. But after the introduction of layouts, not anymore.
The fix: adding the push command
There is much discussion going on about adding the push command. It will adequately encapsulate the change in transfer protocol (switching from YAML to compressed JSON) and the change in repository layout.
This work is underway as part of Helm 3; Matt Butcher describes a lot of improvements they plan to in the next major version. While the majority of changes are in the runtime and the templating parts of Helm, he mentions “performance-oriented changes for chart repositories,” and the official design proposal includes “A command to push packages to a repository.”
Community Rocks!
As you saw, Helm started off avoiding most of the downsides of other package managers. Yes, there is still room for improvement, but with the help of JFrog and other community members, as described in this blog post, we are about to fix the last technical problems standing between Helm and massive enterprise adoption. With the authentication issue being solved already, and the index optimizations, repo layout, and the push command additions in the works, we can expect Helm to be one of the most advanced package managers out there. There is still a lot to be done, of course. Helm makes it very easy to get started contributing. Just look for issues tagged with “good first issue” and join an amazing community.
 Baruch Sadogursky’s passion is speaking about technology. Well, speaking in general, but doing it about technology makes him look smart, and 17 years of hi-tech experience sure helps. When he’s not on stage (or on a plane to get there), he learns about technology, people and how they work, or more precisely, don’t work together.
Baruch Sadogursky’s passion is speaking about technology. Well, speaking in general, but doing it about technology makes him look smart, and 17 years of hi-tech experience sure helps. When he’s not on stage (or on a plane to get there), he learns about technology, people and how they work, or more precisely, don’t work together.
Baruch is a Head of DevRel and a Developer Advocate at JFrog, a CNCF Ambassador, a passionate conference speaker on DevOps, Java and Groovy topics, and is a regular at the industry’s most prestigious events including JavaOne (where he was awarded a Rock Star award), DockerCon, Devoxx, DevOps Days, OSCON, Qcon and many others. Follow him on Twitter (as he’s a very entertaining guy!) at @jbaruch.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.