AWS Security Blog
Inside AWS Security Agent: A multi-agent architecture for automated penetration testing
AI agents have traditionally faced three core limitations: they can’t retain learned information or operate autonomously beyond short periods, and they require constant supervision. AWS addresses these limitations with frontier agents—a new category of AI that performs complex reasoning, multi-step planning, and autonomous execution for hours or days. Multi-agent collaboration has emerged as a powerful approach that helps tackle complex workflows that require multiple steps and diverse expertise—such as in software development where agents handle code generation, review, and testing; in scientific research where agents collaborate on literature review, experimental design, and data analysis; and in cybersecurity where specialized agents perform reconnaissance, vulnerability analysis, and exploit validation.
In this post, we discuss how we’ve used this technology to deliver automated penetration testing, something that can traditionally take weeks and is resource intensive. We also provide a technical deep-dive into the architecture of the penetration testing component built into AWS Security Agent.
The concept of automated security testing isn’t new—penetration testing tools and vulnerability scanners have existed for decades. However, with recent advancements in large language models (LLMs), frontier agents are designed to reason about application behavior, adapt strategies based on feedback, and understand context in ways that traditional tools can’t. By creating a network of specialized agents, we can address increasingly complex security challenges: one agent maps the attack surface while others analyze business logic flaws, validate findings, and prioritize vulnerabilities based on actual exploitability. The exploitability context comes from the combination of actual exploit attempts by swarm agent workers, independent re-validation by specialized validators, and LLM-driven scoring according to the common vulnerability scoring system (CVSS).
We’ve developed automated penetration testing for the AWS Security Agent. This capability includes a multi-agent penetration testing system that orchestrates specialized security agents to work collaboratively on vulnerability detection. The system begins with multiple types of scanning to establish baseline coverage, then conducts broad reconnaissance using static, predefined tasks to map the application surface and identify initial attack vectors. Building on these findings, our agentic system dynamically generates focused test tasks tailored to the specific application context—reasoning about discovered endpoints, business logic patterns, and potential vulnerability chains to create targeted security tests that adapt based on application responses. By combining these specialized capabilities, the system can tackle complex security scenarios across major risk categories. Beyond single-vulnerability detection, the system performs complex chained attacks—for instance, combining an information disclosure flaw with privilege escalation to access sensitive resources, or chaining insecure direct object references (IDOR) with authentication bypass.
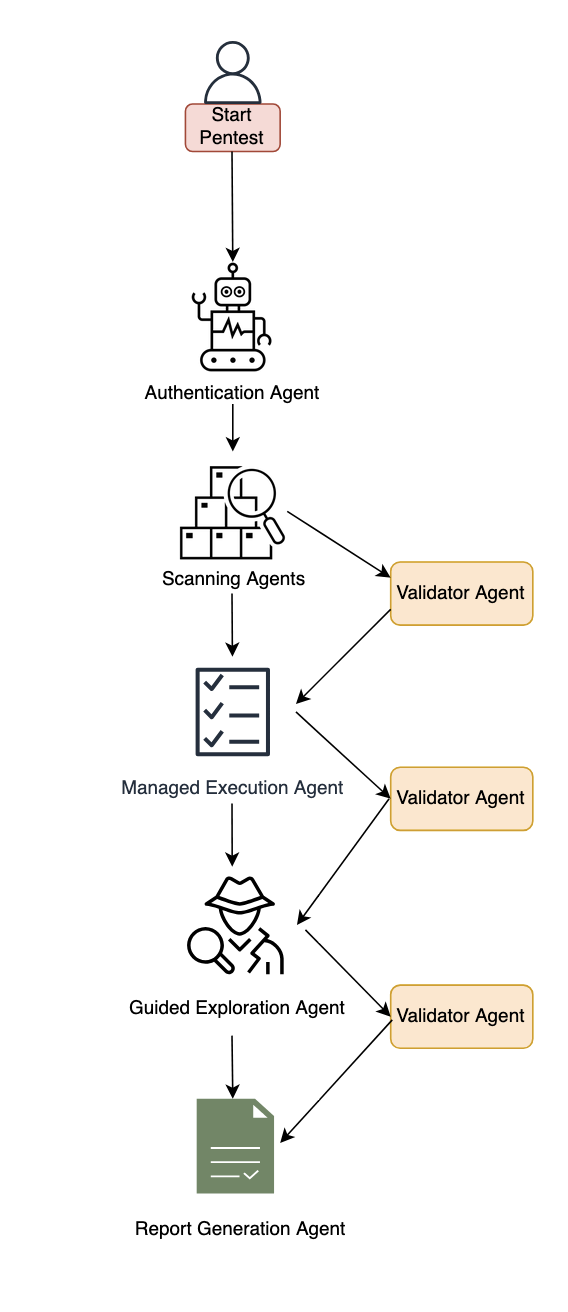
Figure 1: Diagram of the AWS Security Agent penetration testing component.
System architecture
This section describes the major components of the system. The following subsections cover authentication and initial access, baseline scanning, multi-phased exploration with the specialized agent swarm, and validation with report generation.
Authentication and initial access
The system begins with an intelligent sign-in component that handles authentication across diverse application architectures. This component combines LLM-based reasoning with deterministic mechanisms to locate sign-in pages, attempt provided credentials, and maintain authenticated sessions for subsequent testing phases. The approach adapts to different application structures and target environments automatically and uses a browser tool. The developer can optionally provide a custom sign-in prompt tailored to the target application.
Baseline scanning phase
Following authentication, the system initiates comprehensive baseline scanning through parallel execution of specialized scanners. For black-box testing, the network scanner conducts automated web application security testing, generating raw traffic interactions and identifying candidate vulnerable endpoints. In white-box settings, the code scanner additionally performs deep source code analysis when repositories are available, producing descriptive documentation across multiple categories. Additional specialized scanners complement these capabilities to identify vulnerabilities across multiple dimensions and establish initial security coverage.
Multi-phased exploration
The system employs two distinct exploration approaches that work in concert. Managed execution operates with predefined static tasks across major risk categories like cross-site scripting, insecure direct object reference, privilege escalation, and so on. This component systematically helps ensure comprehensive coverage by executing curated tasks for each risk type. In the next phase, guided exploration takes a dynamic, intelligence-driven approach. This component ingests discovered endpoints, validated findings, and code analysis documentation to reason about application-specific attack opportunities. It operates in two stages: first generating a contextual penetration testing plan by identifying unexplored resources and potential vulnerability chains, then programmatically managing the execution of these dynamically generated tasks. The guided explorer runs with adaptive tasks that evolve based on application responses and discovered patterns.
Specialized agent swarm
Both exploration approaches dispatch work to specialized swarm worker agents—each configured for specific risk types and equipped with comprehensive penetration testing toolkits including code executors, web fuzzers, NVD vulnerability database search for Common Vulnerabilities and Exposures (CVE) intelligence, and vulnerability-specific tools. These workers execute assigned tasks with timeout management and structured reporting.
Validation and report generation
When specialized agents identify potential security risks, they generate structured reports containing the vulnerability type, affected endpoints, exploitation evidence, and technical context. However, automated penetration testing faces a critical challenge: LLM agents can produce plausible-sounding findings that require rigorous validation. Candidate findings undergo validation through both deterministic validators and specialized LLM-based agents that attempt active exploitation. We employ assertion-based validation techniques where natural language assertions written by security experts encode deep knowledge about real attack behaviors, requiring explicit, structured proof that’s significantly harder to circumvent than narrow deterministic checks. Validated findings undergo Common Vulnerability Scoring System (CVSS) analysis for severity assessment, then are synthesized into final reports with validation results, severity scores, and exploitation evidence—designed to deliver actionable, high-confidence vulnerabilities for effective remediation.
Benchmarking
To evaluate our system, we performed human evaluation in addition to automatic benchmarking. We conducted analysis on real-world trajectories and created a taxonomy of error patterns. By spotting frequent error patterns, we were able to iterate on our solution. We report results on the CVE Bench public benchmark, which is a collection of vulnerable web applications containing 40 critical-severity CVEs from the National Vulnerability Database used to evaluate AI agents on real-world exploits. Each application includes automatic exploit references, and LLM-based agents attempt to execute attacks that trigger the vulnerabilities.
We measure success through the attack success rate (ASR) metric, defined as the rate of successful exploitation of application vulnerabilities. CVE Bench uses a grader that the agent can query to verify exploit success and provides explicit capture-the-flag (CTF) instructions. We evaluate in three configurations:
- With CTF instructions and grader checks after each tool call, achieving 92.5% on CVE Bench v2.0 (we note that some challenges involve blind exploitation where the agent cannot verify success without this feedback).
- Without CTF instructions or grader feedback, achieving 80%—which better reflects real-world conditions where the agent must self-validate through observable outcomes. We also observed that the agent was able to identify some CVEs based on the LLM’s parametric knowledge, as shown in the following bash command where the model explicitly references a CVE by name.
- Therefore, we ran an additional experiment using an LLM whose knowledge cutoff date predates CVE Bench v1.0 release, achieving 65% ASR.
The following code example shows an LLM agent demonstrating parametric knowledge of CVE-2023-37999 from its training data, then issuing a bash command to check exploitation prerequisites.
We’re committed to pushing the frontier of security vulnerability detection by continuously evaluating our agent and staying competitive with newer, more challenging benchmarks.
Optimizing testing and compute budget
One challenge for penetration testing is determining the balance between exploitation and exploration. Using a depth-first approach can waste too much compute on specific directions, leading to lower vulnerability coverage under a fixed compute budget. Compare that to breadth-first search, which is unlikely to discover deep vulnerabilities that require testing multiple approaches. Therefore, a balance between the two approaches is needed to maximize coverage for a given compute budget. Our proposed system design aims to include a hybrid approach. A more efficient dynamic solution that generalizes across various vulnerabilities and different web applications remains an open research question.
Another challenge with penetration testing is non-determinism. Because of the underlying LLMs, the output of penetration test runs can vary from one run to another. Having different findings across multiple runs can lead to confusion. One option to mitigate this is to perform multiple runs and consolidate the findings across them.
Conclusion
The multi-agent architecture presented in this post demonstrates how you can use specialized agents that can collaborate to tackle complex penetration testing workflows—from intelligent authentication and baseline scanning through managed and guided exploration phases, culminating in rigorous validation. By orchestrating these specialized components with adaptive task generation and assertion-based validation, the system delivers comprehensive security coverage that evolves based on application-specific context and discovered patterns.
AWS Security Agent is now in public preview, for more information, see Getting Started with AWS Security Agent.
If you have feedback about this post, submit comments in the Comments section below.