AWS Startups Blog
Cluster-Based Architectures Using Docker and Amazon EC2 Container Service
In the first post of this series, we examined how Linux container technology, like Docker, can be used to streamline software development and testing. The lightweight portability of Docker containers makes it very easy to deploy code in a way that minimizes the issues that arise due to slight differences between development, test, stage, and production environments. In the second post, we illustrated how the characteristics of Docker-based application development and deployment mesh very nicely with the modern, distributed systems architecture known as “microservices.” We also briefly touched upon the need to deploy container-based architectures using some sort of container framework. As the number of containers grows, it becomes increasingly difficult to manage manually, and this is where services like the Amazon EC2 Container Service (ECS) can really help.
In this post, we’re going to take a deeper dive into the architectural concepts underlying cluster computing using container management frameworks such as ECS. We will show how these frameworks effectively abstract the low-level resources such as CPU, memory, and storage, allowing for highly efficient usage of the nodes in a compute cluster. Building on some of the concepts detailed in the earlier posts, we will discover why containers are such a good fit for this type of abstraction, and how the Amazon EC2 Container Service fits into the larger ecosystem of cluster management frameworks.
Sharing Resources in a Compute Cluster
Before we taker a deeper dive into ECS, it’s helpful to review a few key concepts of cluster-based computing. Simply put, a compute cluster is a multi-tenant computing environment consisting of servers (called “nodes”) whose resources have been pooled together and are used to execute processes. A collection of processes that are executed together is called a task, and a collection of tasks executed together is called a job. In most cases, the author of a job need not know (or care) about which node(s) in the cluster actually execute the underlying processes defined in the tasks that make up the job. To enable this behavior, the nodes in a cluster must be managed by some sort of cluster management framework. Figure 1 depicts the components that comprise the typical cluster management framework:

Let’s look at each of these components individually. The Resource Manager is responsible for keeping track of resources like memory, CPU, and storage that are available at any given time in the cluster. Each executing task consumes some of the available resources, and it’s up to the Resource Manger to keep track of this information. The Task Manager is responsible for the task execution lifecycle. This component is usually implemented as a state machine. Finally, the Scheduler is responsible for scheduling tasks for execution. It must contain algorithms for managing dependencies between the tasks that comprise a job, as well as algorithms for assigning tasks to nodes in the cluster based on the resources required to execute the task. In many ways, the scheduler is the most important component of the cluster management framework — and, as we’ll see later, this has important implications to the architecture of the EC2 Container Service.
A cluster management framework such as the one depicted above provides a very useful abstraction of the low-level details for executing tasks in a shared computing environment. To run a job, a programmer simply needs to express the job — often through a config file or shell script — as a collection of tasks and then submit the job to the scheduler for execution. The cluster management framework will take care of everything else, including check-pointing and re-queuing of failed tasks. Because different teams within an organization may share a cluster, prioritization can be used to tell the scheduler which jobs to execute before others. Cluster resources can be subdivided so that no one team can saturate the cluster with their jobs such that other teams are starved of resources.
Moving Beyond “One Size Fits All” Scheduling
This simple-but-effective cluster management has worked really well for decades. But there are some problems that have become exacerbated in recent years. A cluster management framework can efficiently allocate resources and schedule tasks, but only if all users of the cluster “play by the same rules.” This means that all jobs have to be submitted through the same scheduler. Jobs that are run using different schedulers in different cluster management frameworks won’t be subject to the same set of rules governing prioritization and resource utilization.
In recent years, in part due to the popularity of parallel computing frameworks like Hadoop and Spark, it has become much more common to run multiple frameworks on a single cluster. This means that the monolithic architecture used by traditional cluster management frameworks, in which resource management is coupled with scheduling, no longer works. If you want to run Spark jobs along side Hadoop YARN jobs on the same cluster, both Spark and YARN need to be aware of the resources available on the cluster. In addition, these jobs can’t conflict with one another if executed on the same node. They need to be run in isolation.
These requirements have led to the following architecture, in which scheduling and the execution environment has been decoupled from the resource and task management components of the cluster manager:
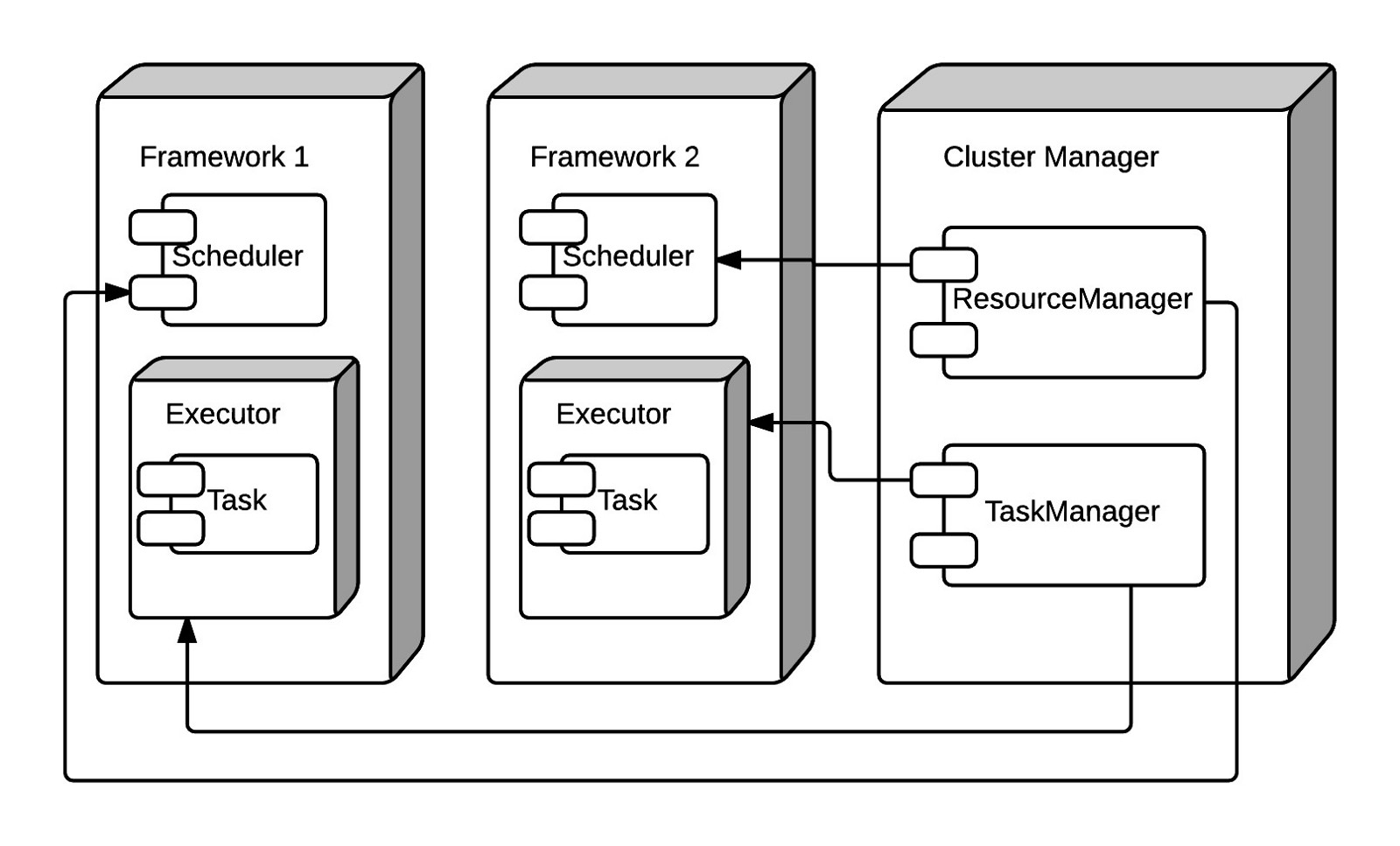
This architecture defines a “framework”, which includes a scheduler and an execution environment. The scheduler components from different frameworks interact with the same cluster manager, which is responsible for the task lifecycle as well as resource management. To ensure that tasks execute in isolation from one another on a node, tasks are launched into an execution environment, which is typically a type of container. With frameworks like YARN and Spark, the container is a JVM. But it can also be a Linux container execution environment, like Docker.
In order for this architecture to support concurrent scheduling, the schedulers in each framework must have some way of knowing the available resources in the cluster. There are several design patterns that can be employed for this. The first is called “two level pessimistic scheduling“ and it works as follows:

In this model, the cluster manager offers up resources like CPU and memory to a scheduler. The scheduler then makes a choice: it can decide whether it wants to execute task(s) using the offered resources, or reject the offer because the offered resources don’t meet the constraints of the tasks that the scheduler has in it’s queue. There are two important characteristics of this pattern:
- Each scheduler only sees a sub-portion of the state of the resources on the cluster in the form of an offer.
- The concurrency model is pessimistic — offers are not made to other schedulers until a pending offer is accepted or rejected.
The second pattern for sharing cluster resource availability to a scheduler is called “shared state optimistic scheduling” and it works as follows:
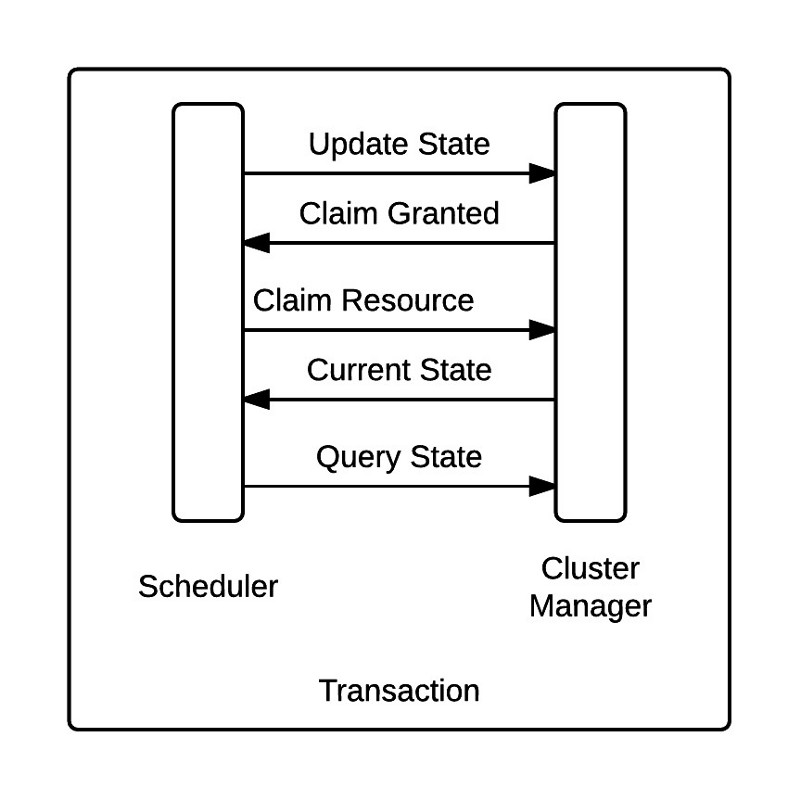
In this model, all schedulers can see the current state of the cluster at all times. Each scheduler periodically queries the current cluster state, and makes a claim for any available resources. The scheduler then updates the cluster state with the newly claimed resources in an atomic transaction. In the event of a conflict (i.e. two schedulers lay claim to the same resource) only one transaction will succeed. Because all schedulers see all available resources at all times, this model is optimistic, as resources are never locked while being offered to a scheduler.
In practice, the shared state optimistic scheduling model has proven to be far more versatile than two-level pessimistic scheduling. Research has show that the pessimistic method, which is used by the Apache Mesos cluster management framework, performs best when jobs execute quickly. But it is common to run both short and long running jobs (called “services”) on the same cluster. For this use-case, the shared state optimistic scheduling model works much better.
EC2 Container Service Architecture
Now that we’ve reviewed the key components of a modern, cluster management framework, we can clearly define what the EC2 Container Service is: A cluster management framework that uses optimistic, shared state scheduling to execute processes on EC2 instances using Docker containers. The architecture of ECS is as follows:
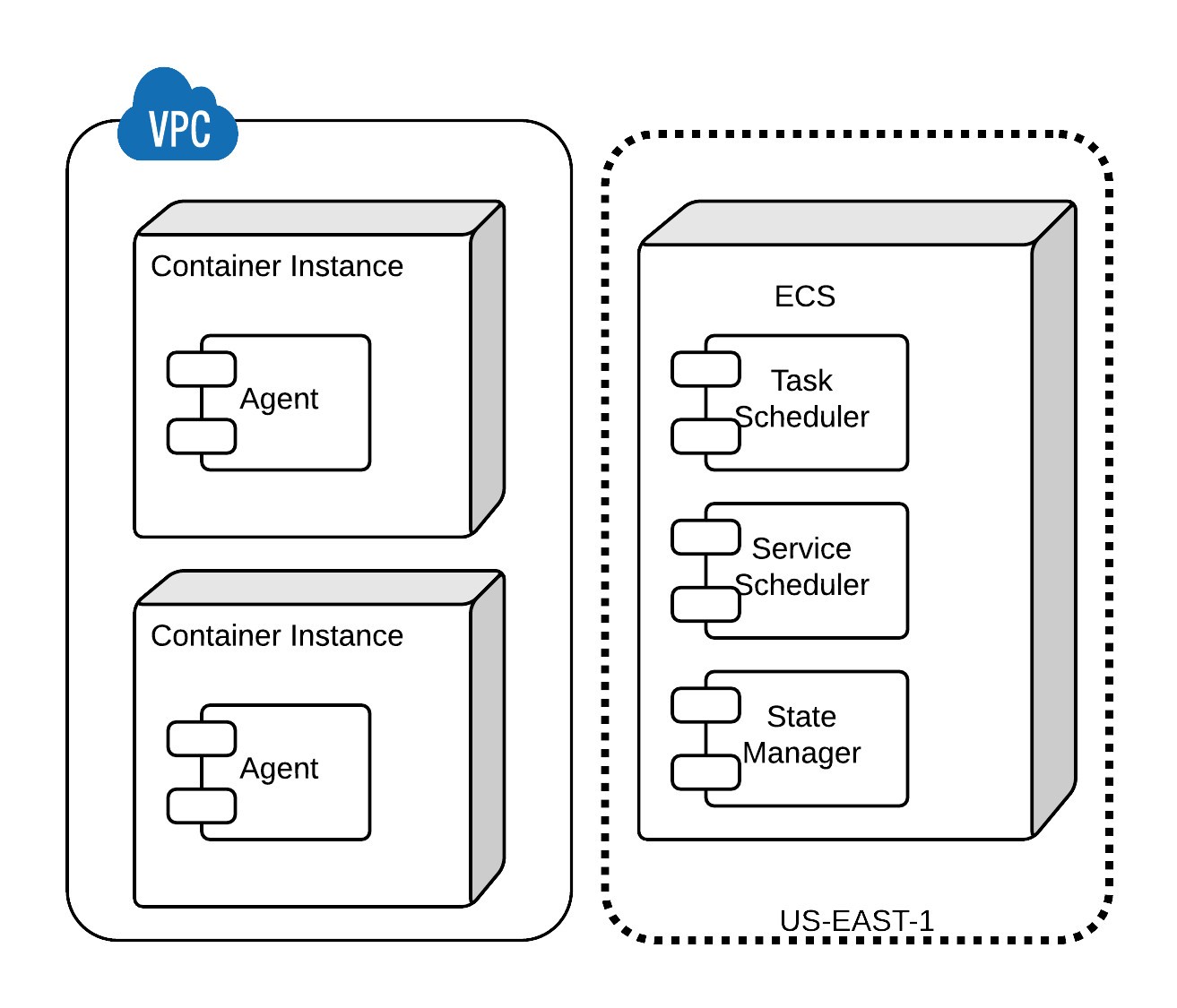
This architecture has some important characteristics:
- The container instances comprising the cluster live in the customer’s VPC and are controlled and secured entirely by the customer.
- Container instances communicate with the ECS service through an “agent,” which is a Docker container running on the instance. This is automatically included in the Amazon ECS-Optimized Amazon Linux AMI.
- ECS includes shared state, optimistic schedulers for short running tasks and long running services.
- Task and service state management is provided by a fully ACID compliant, distributed datastore.
Like other managed services in AWS, such as Amazon DynamoDB, the ECS takes care of many of the challenges in running a distributed system. Customers need not worry about monitoring the health and availability of “master” nodes that provide the scheduling and resource management capabilities. Instead, this is all handled transparently by ECS itself. In addition, ECS provides a robust solution to the very challenging problem of storing state information in an ACID compliant way in a distributed system. Finally, ECS is designed to scale horizontally and for high availability. The net effect of all this is that customers can focus on building their distributed applications using Docker containers without getting bogged down with operational complexity.
That being said, ECS is both extensible and interoperable. The service is designed to participate in the larger container-based cluster management ecosystem. One of the more powerful properties of a shared-state optimistic scheduler is that it is “backwards compatible” with other scheduling models, like two-level pessimistic scheduling. This means frameworks compatible with popular cluster management systems like Apache Mesos can work just as well with ECS. If you’re using a framework like Marathon to execute tasks on a Mesos-managed cluster, you can use that same framework to execute tasks on an ECS-managed cluster. Extensibility is achieved through the service API: a low-level API that can be used as a foundation for building higher-level services on top of it.
Conclusion
In this post, we took a detailed look at the architecture of ECS, and how this helps solve many of the more challenging problems when running container-based applications and services on a shared compute cluster. In the next post, we’ll show these concepts in action by walking through an example of how to actually run a Docker-based application in ECS.