AWS Startups Blog
Pillar on Optimizing Blockchain Data Processing with AWS
Guest post by Kieran Goodary from Pillar Project
Who we are
At Pillar, our business is cryptocurrency. Available for anyone to download is our cryptocurrency wallet app – Pillar Wallet – in both the App Store and Play Store. Users have the ability to buy, sell and exchange cryptocurrency assets. Our app also allows users to meet other cryptocurrency enthusiasts, allows you to send and receive cryptocurrency assets from your friends quickly and easily, utilize decentralized applications with Wallet Connect and more. It’s quite a fully-featured wallet. With this, it’s safe to say that we know blockchains, as the majority of our data is stored there. We work in a space that’s new and has untapped potential. It’s an exciting space to work within, but comes with some very serious challenges given the amount of data available, and being amassed on a daily basis. In order to ingest, process and ultimately make this data useful to users via the Pillar Wallet and our own backend systems – we must run our own services that take our business demands and return useful data.
The Problem
With untapped potential of blockchain technology and a fast growing user base with our Pillar Wallet app – comes the challenge of how to approach and extract value from various blockchains whilst supporting our growing community and their demands. We needed to process large amounts of incoming data, and fast. As humans, we’re immediately inclined to deviate to something that we already know – it’s incredibly hard to accept another method, especially when we don’t know much about it. So as a result, we went with what we know. We ran servers… lots of them. The thought process was simply: “boot it up on EC2”.
Web servers? EC2. Queues? EC2. Database? EC2. Sound familiar?
Most people can see the problem – we were wasting compute capacity, and this was ultimately costing money. As a startup, infrastructure costs and inefficiency contributes heavily to company expenditure. With many EC2 instances came inevitable problems maintaining the software running on the instances, and with these problems… came the requirement for (more) infrastructure engineers. The costs were racking up.
We were left with no choice. We needed to fundamentally change our thinking and the approach to our architecture. We changed the base of our architecture entirely to facilitate our vision: an ability to ingest ever increasing amounts of data from various blockchain networks with high durability, low latency, fault-tolerance, transferability and ultimately store this data in a useful, unrestricted way. There should be no limits.
The Solution and Architecture
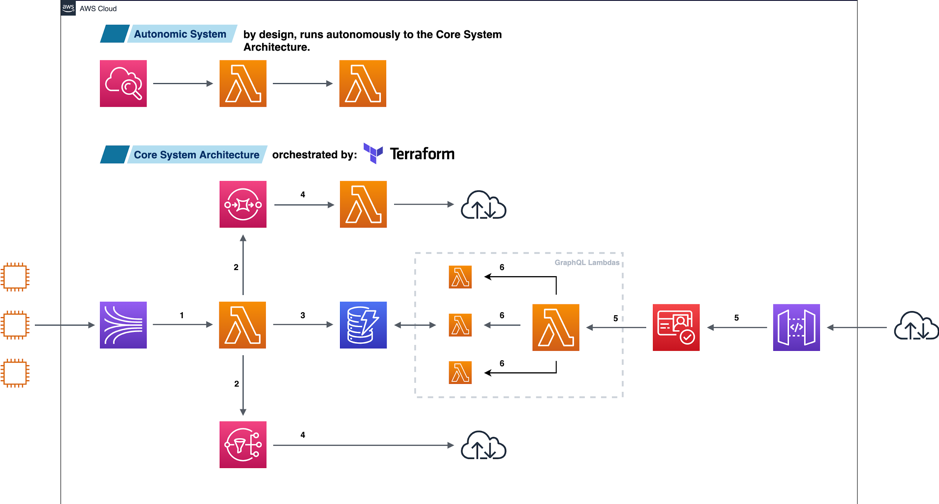
Let’s walk through each of the components above, from left to right.
The above simplified architecture diagram has three very distinct hallmarks:
1. The technology stack: Kinesis, Lambda, SQS, SNS, DynamoDB, Cognito and API Gateway – scale massively out the box. It’s nearly impossible to take this out. There’s not one component on there that is constrained by a hard upper limit, and this was a conscious decision. Let’s go through this point-by-point. Note that the numbers that are suffixed to each point below correspond to numbers in the diagram above.
● We have an event map from Kinesis to our “core ingestion” Lambda. This acts as our first contact for incoming data, and passes through some high-level business logic. 1
● Data is forwarded on to relevant service such as SQS and SNS. 2
● At the same time, we store this data for access later within DynamoDB. 3
● Our SQS queues are event-mapped to another “broadcaster” Lambda, which forwards data to any third party that doesn’t fall under AWS. Our SNS queues are managing and emitting live, more valuable data to our organization that requires real-time or mission critical data subscriptions. An example of this are specific Blockchain address transactions. 4
● Incoming data on the other side of our diagram above is sent from API Gateway, filtered through Cognito and arrives at a Lambda which is our Graph API entry point. 5
● This Lambda invokes other Lambdas that have data-specific concerns that are executed to process and build the response to the Graph API request. 6
We’ve all experienced outage anxiety – we’ve now reduced this to effectively zero. Our technology stack is now maintained, scales, durable and cost effective.
2. This architecture is now brilliantly cost efficient. Most of AWS’s more recent highly scalable services run on a pay-per-request or pay-per-compute model. If this system isn’t processing data – we’re not paying for it. Gone are the days where we’re paying for infrastructure that we’re not using, which immediately resulted in a dramatic decrease in our infrastructure costs.
3. Because of the design of the AWS API, it has given rise to the ability to build this as an autonomic architecture. We periodically check all components of the system using a method we call the “Architect / Mechanic” model. The “Architect” has a predetermined blueprint of how a system should look and behave. If anything is out of place, a message is dispatched to the “Mechanic” who will immediately fill in the gaps, or facilitate any jobs needed to repair the system. The autonomic components of this architecture don’t have any say in how the system behaves, and operates independently.
See the diagram below for an overview of how data flows from both ends of the pipeline:

The Savings
Make no mistake, this is a game changer. The massive computing scale being made available to you, combined with economies of scale, resulting in the ability to pass these savings on to the end-user by building out services that take advantage of this. Let’s look at a simplified example of our core data ingestion infrastructure.
Let’s assume, for example sake, we’re running everything at 80% utilization. We’re also assuming these are all on-demand, and running in the EU West 2 region (London):
Core Data Processing Cluster: 3x EC2 instances (t3 – 2x large)
Database Cluster: 2x EC2 Instances (t3 – large)
Pub/Sub Platform: 3x EC2 instances (t3 – large)
General Purpose SSD: 8x 1Tb (gp2)
1x VPC and 1x NAT Gateway pumping 24Gb of new Blockchain data a day
Total Cost: $2,343.82
It’s worth noting that in the above case, the specifications appear over provisioned. High-performance components such as the 8x 1Tb SSD drives and T3 large instances were, at the time, a naive attempt to get around performance bottlenecks we faced whilst ingesting around 1.5 million cryptographically heavy records a day.
Now let’s build out the same technical components, but using AWS-native services:
Lambda: 1.5 million requests a day (256Mb RAM, ~100ms execution time)
DynamoDB: On-demand, initial dataset of 10Gb, reading 1 million records a month, writing 6 million records a month, eventually consistent
SNS: Pumping an estimated 1 million records in and out via HTTP/HTTPS
SQS: FIFO queue, pumping 1 million requests, 1Gb in and 2 Gb out
Note: Our Blockchain mining infrastructure was moved to a third-party provider. Blockchain mining is an infrastructure art in itself, and we plan to revisit this very soon. Thus, NAT gateway costs are not included here. Blockchain data is sent to Kinesis via the AWS SDK. As a startup, this saved us a considerable amount of developer resources and headaches.
Total Cost: $22.50
You read that correctly. Re-architecting with AWS-native services dropped our monthly infrastructure charges by 95.9% over our “traditional” architecture. The efficiency of this re-architecture is evident in the cost – and this is with scalability, durability and fault tolerance built-in.
The Future
The future is exciting. We’ve opened up a world of opportunity and enabled a huge amount of potential by re-architecting with AWS. The aforementioned “untapped potential” is now simply: potential. We now have the ability to connect our data, live or at rest, to a plethora of other incredible services, whilst satisfying all business requirements.
Anyone who knows technology knows just how fast this industry moves. We live or die by our technology stack. Serverless computing is more a revolution than an evolution. It’s a major, not a minor or a patch. We’re no longer thinking about bottlenecks, but back pressure. We’re no longer thinking about computation time, but tuning the pipeline. Data is no longer lost, it’s merely held up, waiting for the green light. We’ve come a long way.
Visit our website at pillarproject.io, or download our Cryptocurrency Wallet app for: iOS, or Android.