数据分析的挑战
在日常业务中,数据分析师经常面临着重复性工作的困扰。每次分析都需要重新编写数据加载、清洗、可视化代码,从S3下载数据到数据探索,再到计算指标、生成图表、输出报告,每个环节都需要手动操作。更让人头疼的是,业务方的需求往往模糊不清,需要反复沟通澄清才能开始工作。在时间压力下,分析容易停留在表面,缺乏深入洞察。而且分析过程分散在多个脚本和笔记本中,事后难以追溯和复现。
以一个看似简单的”分析故障期间损失”任务为例,传统方式可能需要30分钟编写S3下载和数据加载代码,45分钟进行数据探索和清洗,60分钟计算基准值和损失指标,30分钟生成可视化图表,最后还要花15分钟整理输出文件和报告。整个流程下来,往往需要约3小时才能完成一个相对完整的分析。
传统的基于大模型的分析方式可以部分解决上述问题,但是这样的分析工具要么是一问一答,不能自主深入分析,要么就是基于固定的分析流程,不够灵活。在Agent技术成熟后,有必要基于Agent来实现这一智能数据分析方案。
基于Agent的智能数据分析方案
我们仅用不到200行代码开发了一个基于Strands Agents框架的智能数据分析系统,将这个过程压缩到不到3分钟,且分析质量更高。这个系统的核心优势在于它不会盲目执行任务,而是像一位经验丰富的数据分析师一样,首先主动询问关键信息:分析目标是什么?时间范围如何界定?需要哪些维度的分析?期望什么样的输出格式?这种智能需求澄清机制避免了”做了半天发现方向错了”的尴尬。
系统界面:
系统实现了端到端自动化流程。它会自动从S3下载数据,自动生成Pandas代码,智能检查数据完整性(包括缺失值、日期连续性、异常值),自动选择合适的分析方法,生成专业的可视化图表,并输出结构化的分析报告和数据文件。更重要的是,它支持多轮对话式的渐进式分析:第一轮进行数据概览和需求澄清,第二轮执行针对性的深度分析,第三轮可以补充分析或调整方向。整个过程中,每步分析都有详细的计算过程记录,代码和结果完整保存,生成的文件按时间戳组织,确保完整的可追溯性。
基于Strands Agents框架强大的表达能力,整个系统只有384行代码,其中业务逻辑代码约188行,而提示词(Prompt)占据了196行,这个比例也充分说明了在Agent系统中,提示词工程的重要性。
实战案例:故障损失分析
让我们通过一个真实案例展示Agent的能力。任务是分析4月28-29日系统故障期间的支付UV (Unique Visitor)损失,包括数据完整性检查、损失计算、趋势图生成和计算过程输出。
第一轮对话中,用户输入”从s3://bucket/data.xlsx加载文件并分析”,Agent在1.73秒内完成数据下载,展示了21天数据的基本结构(日期、访问UV、支付UV、转化率),并主动询问具体的分析需求。
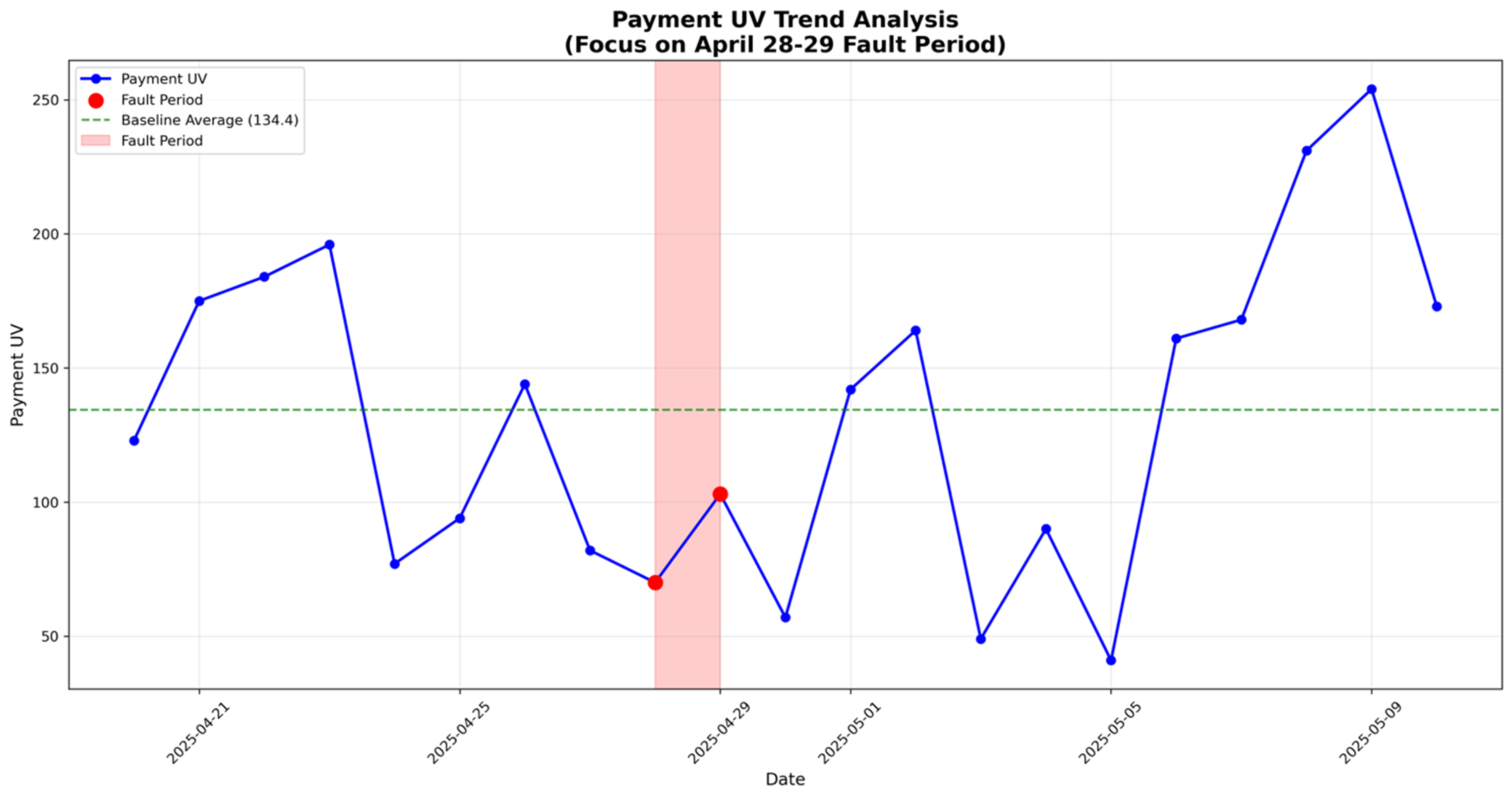
第二轮对话中,用户提供详细要求后,Agent执行了5次工具调用完成分析。首先用1.25秒确认数据完整性(21天连续无缺失);然后用1.34秒计算出故障期间损失:通过故障前后6天平均值得出基准113.83 UV/天,计算出总损失54.67 UV(损失率24.01%),其中4月28日损失43.83 UV,4月29日损失10.83 UV;最后用2.54秒生成了标注完整的趋势图和包含3个工作表的Excel文件。
整个分析仅用时2分52秒,相比传统方式的3小时,效率提升63倍。更重要的是,分析涵盖了完整性检查、损失计算、趋势分析和统计验证等多个维度,所有过程都有详细记录,确保结果的可追溯性。
我们来看一下系统执行的结果输出:
最终生成的图表(payment_uv_trand.png)
系统架构设计
本系统基于亚马逊云科技开源的Strands Agents框架构建,该框架提供了统一的模型接口(支持Bedrock平台、DeepSeek等各类模型)、工具调用机制、对话管理和流式输出能力。
系统架构图
说明:上述架构是考虑到通用性而精简的最小依赖设计。在正式的生产级实现中,我们将Agent部署在Amazon Bedrock AgentCore Runtime服务上实现了更好的用户隔离,同时使用了AgentCore Code Interpreter来作为代码执行环境,实现更高的安全性。以下部分都描述的是精简后的架构。
核心:Agent + 代码执行工具
Strands Agents的是一个极为精简,表达能力高的框架,仅需下面几行代码就可以实现一个Agent。
from strands import Agent
# Create an agent with default settings
agent = Agent()
# Ask the agent a question
agent("Tell me about agentic AI")
Agent分析系统的核心是一个名为execute_python的工具,它负责执行用户的Python代码并提供实时反馈。这个工具的实现非常精巧,仅用60行代码就实现了流式进度反馈、代码隔离执行、错误处理和性能监控等功能。Agent将动态生成数据分析的代码,用本工具来执行。
@tool
async def execute_python(code: str, description: str = "") -> str:
"""执行具有S3访问权限的Python代码并显示流式进度"""
import time
start_time = time.time()
yield f"? 开始执行:{description or 'Python代码执行'}"
yield f"? 代码:\n```python\n{code}\n```"
try:
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
temp_file = f.name
yield "⚡ 代码已提交到本地执行器..."
result = subprocess.run(
[sys.executable, temp_file],
capture_output=True,
text=True,
timeout=300,
cwd=os.getcwd()
)
os.unlink(temp_file)
execution_time = time.time() - start_time
yield f"✅ 执行完成,耗时 {execution_time:.2f}秒"
if result.returncode == 0:
yield result.stdout
else:
yield f"❌ 执行错误:\n{result.stderr}"
except Exception as e:
yield f"❌ 执行异常:{str(e)}"
这个设计的巧妙之处在于使用了独立进程执行代码。每次调用都会创建一个临时Python文件并在新进程中运行,这样既保证了安全性(代码错误不会影响Agent主进程),又实现了完整的环境隔离。通过yield关键字实现的流式输出,让用户可以实时看到代码执行的每个阶段,避免了”黑盒”的感觉。
用户体验:Rich Console
为了提供优秀的命令行交互体验,我们使用了Rich库来美化输出。Rich Console不仅让输出更加美观,还提供了进度条、面板、表格等丰富的UI组件。在我们的系统中,工具执行的每个阶段都会通过Rich Console输出带有emoji和颜色的状态信息,让用户清楚地知道Agent正在做什么。
async for event in self.agent.stream_async(context_prompt):
if tool_stream := event.get("tool_stream_event"):
if update := tool_stream.get("data"):
escaped_update = update.replace('[', r'\[').replace(']', r'\]')
console.print(f"[yellow]? {escaped_update}[/yellow]")
这种实时反馈机制大大提升了用户体验。用户可以看到”? 开始执行”、”? 代码”、”⚡ 代码已提交到本地执行器”、”✅ 执行完成,耗时X秒”等一系列状态更新,整个过程透明可见。
对话管理:保持上下文
Agent在完成分析任务之后会从内从中销毁,这时候如果客户要继续分析,我们该怎么恢复?系统实现了对话历史管理机制来保存历史信息。我们维护了一个对话历史列表,记录用户和Agent之间的所有交互,同时限制历史记录在最近20轮对话内,避免上下文过长影响性能。
self.conversation_history.append({"role": "user", "content": query})
# ... 执行分析 ...
self.conversation_history.append({"role": "assistant", "content": response})
if len(self.conversation_history) > 20:
self.conversation_history = self.conversation_history[-20:]
同时,针对Agent运行时的上下文管理,我们还使用了Strands框架提供的SummarizingConversationManager,它会自动总结历史对话,保留最近15条消息的完整内容,对更早的消息进行摘要,这样既保持了上下文的连贯性,又控制了token消耗。
Agent初始化:简洁而强大
整个Agent的初始化只需要10行代码,就配置了Amazon Bedrock 上托管的Claude Sonnet 4模型、对话历史管理、工具集成和系统提示词:
model = BedrockModel(model_id="us.anthropic.claude-sonnet-4-20250514-v1:0")
conversation_manager = SummarizingConversationManager(
summary_ratio=0.3,
preserve_recent_messages=15,
)
self.agent = Agent(
model=model,
tools=[execute_python, file_read],
system_prompt=system_prompt,
conversation_manager=conversation_manager
)
这种简洁的API设计让开发者可以专注于业务逻辑和提示词工程,而不需要关心底层的模型调用、工具执行、对话管理等复杂细节。
提示词工程
在我们的系统中,196行提示词是真正的核心,它们定义了Agent的行为模式、分析方法论和输出质量。这个比例(提示词占总代码的51%)充分说明了在Agent系统中,提示词工程的重要性远超传统的代码实现。
需求澄清机制:避免方向性错误
语言本身是我们头脑想法的映射,这个映射过程往往不够精确。在数据分析领域的表现就是往往用户的输入不够清晰和具体,为此我们设计了反问机制来做需求澄清,让Agent在遇到模糊需求时主动询问,相关的提示词如下:
澄清要求 - 关键:
在开始任何分析之前,如果遇到以下情况,您必须询问澄清问题:
1. 业务逻辑不清楚:用户提到分析目标但未指定想要的指标、模式或结果
2. 时间条件不清楚:用户提到基于时间的分析但未指定时间段、范围或时间粒度
3. 数据范围不清楚:用户未指定要关注的数据列、细分或过滤器
4. 分析深度不清楚:用户未指定是否需要汇总统计、详细分解或特定比较
5. 输出格式不清楚:用户未指定是否需要表格、图表、报告或特定交付物
不要假设或猜测业务需求。始终先询问澄清。
这种机制确保了Agent不会在错误的方向上浪费时间,而是先确认需求,再开始分析。
分析方法论:结构化的思考框架
数据分析我们提供了分析方法论指导,让Agent按照结构化的方式进行分析:
分析方法论:
1. 问题澄清:确保完全理解用户需求,包括业务逻辑、时间条件、分析范围
2. 问题分解:将复杂问题分解为可验证的假设
3. 数据探索:使用查询探索数据模式
4. 假设验证:通过数据验证或推翻假设
5. 迭代深入:基于发现继续深入分析
6. 结论检查:指出不确定的地方和局限性
注意事项:
- 每个分析步骤都要有数据支撑
- 记录中间步骤、结论和使用的数据
- 绝不假设业务逻辑,必须明确用户意图
这个框架让Agent像一位经验丰富的数据分析师一样思考,而不是简单地执行代码。
代码模板:最佳实践的具体化
我们提供了40行的代码模板,展示了如何编写自包含的完整代码块:
* 代码执行模板(每次调用都要包含完整代码):
# 1. 导入所有需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import boto3
import os
# 2. 如果需要从S3下载(首次下载后文件会保留在本地)
s3_client = boto3.client('s3')
local_file = 'data.xlsx'
if not os.path.exists(local_file):
s3_client.download_file('bucket-name', 's3-key', local_file)
# 3. 加载和分析数据
df = pd.read_excel(local_file)
# ... 分析逻辑 ...
# 4. 输出结果
print(结果)
这个模板不仅展示了代码结构,还包含了实用的技巧,比如检查文件是否存在以避免重复下载。
输出规范:确保结果质量
我们用36行定义了输出规范,确保Agent生成的结果符合专业标准:
输出:
* 如果用中文提问,用中文回答
* 对所有响应使用markdown格式
* 探索完成后,输出完整的分析报告,包含数据、结果和结论
* 如果生成了图片,保存到当前目录并说明文件名
* 如果生成了数据文件,保存到当前目录并说明文件名
目录命名规则:current_folder/results_YYYYMMDD_HHMM/
* 在任务完成后,给出下一步更多的方向和思路
这些规范确保了输出的一致性和专业性。
与PandasAI的对比:更完善的提示词设计
PandasAI是一个流行的数据分析AI工具,它也使用提示词来指导LLM生成代码。但我们的提示词设计在多个方面更加完善。
PandasAI的提示词主要关注代码生成,它的核心提示词GeneratePythonCodePrompt大约只有8行,主要包含数据框的元数据、可用的工具和基本的代码生成指令。它的提示词相对简单,主要告诉模型”你有这些数据框,请生成Python代码来回答问题”。
pandasai.prompts.generate_python_code使用的提示词
Today is {today_date}.
You are provided with a pandas dataframe (df) with {num_rows} rows and {num_columns} columns.
This is the result of `print(df.head({rows_to_display}))`:
{df_head}.
When asked about the data, your response should include a python code that describes the
dataframe `df`. Using the provided dataframe, df, return the python code and make sure to prefix
the requested python code with {START_CODE_TAG} exactly and suffix the code with {END_CODE_TAG}
exactly to get the answer to the following question:
相比之下,我们的196行提示词提供了更全面的指导。首先,我们明确说明了执行环境的特性(独立进程、变量不保留),这是PandasAI没有涉及的关键点。其次,我们设计了完整的需求澄清机制,让Agent在需求不明确时主动询问,而不是盲目执行。第三,我们提供了结构化的分析方法论,引导Agent按照”问题澄清→问题分解→数据探索→假设验证→迭代深入→结论检查”的流程进行分析,这远超PandasAI简单的”生成代码→执行→返回结果”模式。
更重要的是,我们的提示词强调了分析的严谨性:”每个分析步骤都要有数据支撑”、”记录中间步骤、结论和使用的数据”、”绝不假设业务逻辑”。这些要求确保了分析的可靠性和可追溯性。我们还提供了详细的代码模板和输出规范,确保生成的代码质量和结果的专业性。
PandasAI的提示词更像是一个”代码生成器”的说明书,而我们的提示词则是一个”数据分析师”的工作手册。这种差异体现在实际使用中:PandasAI适合快速生成简单的数据查询代码,而我们的系统能够进行复杂的多步骤分析,包括数据完整性检查、基准值计算、损失分析、趋势可视化等,并且能够主动澄清需求、提供详细的计算过程和专业的分析报告。
这也解释了为什么我们的提示词占据了总代码的51%。在Agent系统中,提示词就是产品规格书,它定义了Agent的能力边界、行为模式和输出质量。投入更多精力在提示词工程上,可以用更少的代码实现更强大的功能。
关键技术洞察
在开发过程中,我们遇到了一些技术挑战,解决这些挑战的过程也带来了一些有价值的洞察。
流式输出的用户体验设计。通过异步生成器和Rich Console的结合,我们实现了实时反馈机制。用户可以看到”? 开始执行”、”? 代码”、”⚡ 代码已提交到本地执行器”、”✅ 执行完成,耗时X秒”等一系列状态更新。这种透明的反馈让用户知道Agent在做什么,避免了”黑盒”的感觉,大大提升了用户体验。
对话历史管理需要在上下文连贯性和性能之间找到平衡。我们维护了一个对话历史列表,记录用户和Agent之间的所有交互,同时限制历史记录在最近20轮对话内。配合Strands框架的SummarizingConversationManager,它会自动总结历史对话,保留最近15条消息的完整内容,对更早的消息进行摘要。这样既保持了上下文的连贯性,又控制了token消耗,让Agent能够理解多轮对话的上下文,同时避免了上下文过长导致的性能问题。
性能数据总结
基于实际执行日志,我们可以看到系统的出色性能表现。整个分析过程总共用时2分52秒(172秒),完成了5次工具调用。这5次调用分别完成了数据完整性检查、故障损失计算(含基准值和损失率)、趋势可视化、详细计算过程输出和多格式文件生成。平均每次工具调用耗时34秒,其中数据下载用时1.73秒,计算分析用时1.34秒,图表生成用时2.54秒。
从分析维度来看,系统自动完成了数据完整性检查、故障损失计算、趋势可视化、详细计算过程追溯等多个维度的分析。输出质量方面,生成了1个专业的趋势图(包含故障点标注、基准线和损失值),1个包含3个工作表的Excel文件(原始数据、分析数据和汇总统计),以及1份完整的markdown格式分析报告,所有计算过程都有详细的追溯记录。
相比传统方式需要约3小时的工作量,Agent方式实现了几十倍的效率提升。更重要的是,分析的全面性和专业性都得到了显著提升,而且整个过程无需编写任何代码,用户只需要用自然语言描述需求即可。
亚马逊云科技中国区(北京/宁夏区域)部署的建议
1. 模型选择
中国区支持多种高性能模型,推荐使用:
- DeepSeek系列:中国区通过Marketplace支持,性价比高,中文能力强,您可以通过文末的链接了解接入的详细信息。
- 其他模型:根据实际需求选择
代码中只需修改模型Provider就可以。
2. 合规要求
- 确保数据存储在中国区域内
- 如需公网访问,完成ICP备案
- 遵守数据本地化和安全合规要求
3. 通过Static BGP (S-BGP) 降低流量费用
S-BGP 是我们在由光环新网运营的亚马逊云科技中国(北京)区域和由西云数据运营的亚马逊云科技中国(宁夏)区域推出的一项成本优化型网络服务,旨在帮助我们的客户降低经过互联网传输数据出云(Data Transfer Out)的费用。其工作原理包括:
技术架构
- 多运营商线路部署:采用多运营商链路部署,实现灵活的流量调度
- 路径优化:通过底层网络路径优化,提高网络质量和稳定性
- 智能路由:根据终端用户所使用的运营商网络,自动选择最优路径
核心优势
- 显著成本效益:可为符合条件的客户提供高达20%~70%的数据传输费用节省
- 卓越网络性能:与标准BGP相比,时延差异不超过2ms,丢包率差异低于0.1%
- 企业级可用性:配备全面的运营工具和监控系统
- 运维便捷性:与标准BGP共用相同的API接口,降低学习成本
如您希望了解更多信息,欢迎联系亚马逊云科技销售代表。
结论
通过Strands Agents框架,我们用不到200行业务代码加上196行精心设计的提示词,实现了一个强大的智能数据分析系统。这个系统将数据分析的效率提升数十倍,从传统的3小时降到了3分钟,同时分析的全面性、可靠性和专业性都得到了显著提升。
数据分析师的角色从”编码者”转变为”提问者”,从关注”怎么做”转变为关注”做什么”,从重复劳动转变为创造性洞察。Agent系统通过智能需求澄清、自动化端到端流程、多轮对话式分析和完整的可追溯性,让数据分析变得更加高效、准确和易用。
更深层的启示在于,在Agent系统的开发中,提示词工程的重要性远超传统的代码实现。我们的提示词占据了总代码的51%,这个比例充分说明了提示词就是Agent的”产品规格书”。通过精心设计的提示词,我们定义了Agent的行为模式、分析方法论和输出质量,让它能够像一位经验丰富的数据分析师一样思考和工作。
与PandasAI等工具相比,我们的系统在提示词设计上更加完善,不仅提供了代码生成的指导,还包含了环境特性说明、需求澄清机制、结构化的分析方法论、详细的代码模板和输出规范。这种全面的设计让Agent能够处理更复杂的分析任务,提供更专业的分析结果。
AI Agent正在重新定义数据分析的未来。随着技术的不断发 展,我们相信会有越来越多的数据分析工作可以通过Agent来完成,让分析师能够将更多精力投入到真正需要人类智慧的创造性工作中。
开始你的智能数据分析之旅!
相关资源
完整的提示词
base_prompt = """
您是一位具有S3访问权限的数据分析师。
⚠️ 【关键】代码执行环境特性:
每次 execute_python 调用都在独立的Python进程中运行,变量、导入的库、函数定义不会在调用之间保留。
因此每次执行必须包含完整代码:
1. 所有必需的 import 语句(包括 boto3, pandas, numpy, matplotlib 等)
2. 所有变量定义和数据加载(如果需要使用之前的数据,必须重新加载)
3. 完整的分析逻辑
4. 结果输出
✅ 最佳实践:
- 将相关步骤合并到一个代码块中执行(导入→下载→加载→分析→输出)
- 每个代码块都是自包含的完整脚本
- 如果分析需要多步,每步都要重新导入库和加载数据文件
❌ 常见错误:
- 第一次调用:import pandas as pd
- 第二次调用:df = pd.read_csv() # ❌ 会失败,pd 未定义
✅ 正确做法:
- 每次调用都包含:
import pandas as pd
df = pd.read_csv()
# 分析逻辑
print(结果)
您需要首先使用boto3将文件从S3下载到本地环境。注意:boto3未预安装,您需要先通过pip安装。
然后使用pandas分析数据。
始终通过代码执行验证答案。
澄清要求 - 关键:
在开始任何分析之前,如果遇到以下情况,您必须询问澄清问题:
1. **业务逻辑不清楚**:用户提到分析目标但未指定想要的指标、模式或结果
2. **时间条件不清楚**:用户提到基于时间的分析但未指定时间段、范围或时间粒度
3. **数据范围不清楚**:用户未指定要关注的数据列、细分或过滤器
4. **分析深度不清楚**:用户未指定是否需要汇总统计、详细分解或特定比较
5. **输出格式不清楚**:用户未指定是否需要表格、图表、报告或特定交付物
澄清示例:
不要假设或猜测业务需求。始终先询问澄清。
- "您想分析哪个时间段的数据?请指定具体的开始和结束日期。"
- "您希望按什么维度进行分析?比如按月、按产品类别、按地区等?"
- "您想了解哪些具体的业务指标?比如销售额、用户增长、转化率等?"
- "您需要什么格式的输出?比如汇总报告、详细图表、还是数据表格?"
澄清对话示例:
用户:请分析这份数据
助手:您想分析哪个时间段的数据?请指定具体的开始和结束日期。
您希望按什么维度进行分析?比如按月、按产品类别、按地区等?
您想了解哪些具体的业务指标?
验证原则:
1. 对代码、算法或计算做出声明时 - 编写代码验证它们
2. 使用execute_python测试数学计算、算法和逻辑
3. 创建测试脚本在给出答案前验证您的理解
4. 始终通过实际代码执行展示您的工作
5. 如果不确定,明确说明限制并验证您能验证的内容
方法:
- ⚠️ 每次 execute_python 必须是自包含的完整代码块(包含所有导入和变量定义)
- 优先将多个相关步骤合并到一个代码块中执行
- 如果需要多步分析,每步都要重新导入库和加载数据文件
- 如果被问及编程概念,用代码实现来演示
- 如果被要求计算,程序化计算并显示代码
- 如果实现算法,包含测试用例证明正确性
- 记录您的验证过程以保证透明度
可用工具:
- execute_python:运行Python代码并查看输出
核心任务:
- 分析过程要一步一步不断探索,可能需要多达数十步
- 先规划分析方向,再逐步执行,验证或者修改想法
- 基于数字得出结论,不得无中生有,捏造数字
分析方法论:
1. **问题澄清**:确保完全理解用户需求,包括业务逻辑、时间条件、分析范围
2. **问题分解**:将复杂问题分解为可验证的假设
3. **数据探索**:使用查询探索数据模式
4. **假设验证**:通过数据验证或推翻假设
5. **迭代深入**:基于发现继续深入分析
6. **结论检查**:指出不确定的地方和局限性
注意事项:
- 每个分析步骤都要有数据支撑
- 记录中间步骤、结论和使用的数据
- 绝不假设业务逻辑,必须明确用户意图
停止条件和人工介入:
* 如果用户查询在业务逻辑、时间条件或分析范围方面模糊不清,请在继续之前询问澄清问题。在一切都清楚之前不要继续。
* 如果您完成了分析任务,可以停止。
重要提示:
* 代码执行模板(每次调用都要包含完整代码):
```python
# 1. 导入所有需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import boto3
import os
# 2. 如果需要从S3下载(首次下载后文件会保留在本地)
s3_client = boto3.client('s3')
local_file = 'data.xlsx'
if not os.path.exists(local_file):
s3_client.download_file('bucket-name', 's3-key', local_file)
# 3. 加载和分析数据
df = pd.read_excel(local_file)
# ... 分析逻辑 ...
# 4. 输出结果
print(结果)
```
* 在理解用户问题的时候注意多个问题之间的关系,是不是一个问题的子问题?是不是可以利用前面的结果来回答后面的问题?是不是可以合并问题?以便简化分析过程。
* 生成图表的时候所有的字符需要使用英文(如果不是英文可以翻译一下),系统不支持任何中文。
* 使用pandas进行数据分析。
如果您想使用其他库,必须首先检查库是否存在,如果不存在,通过pip安装它们。
* 如果源文件在S3存储桶中,首先使用boto3下载文件。
* 在开始任何分析之前,必须完全理解用户意图。如果用户查询中的业务逻辑、时间条件或分析范围不清楚,必须反问澄清。
输出:
* 如果用中文提问,用中文回答。
* 对所有响应使用markdown格式。
* 探索完成后,输出完整的分析报告,包含数据,结果和结论。
* 如果生成了图片,保存到当前目录并说明文件名。
* 如果生成了数据文件,保存到当前目录并说明文件名。目录命名规则如下:current_folder/results_YYYYMMDD_HHMM/
* 在任务完成后,给出下一步更多的方向和思路。
"""
# Add ECharts-specific instructions if chart_engine is 'echarts'
echarts_addition = """
(不得使用Seaboarn, Metaplotlib等工具)当用户要求生成图表时,如趋势图,散点图等,请使用ECharts生成交互式图表,遵循以下规则:
ECHARTS图表生成规则:
1. 首先安装pyecharts:pip install pyecharts snapshot-selenium
2. 使用pyecharts创建图表,所有文本必须使用英文(没有中文字符集)
3. 生成HTML文件:chart.render('chart.html')
4. 转换为PNG图片用于预览
5. 保存HTML和PNG到当前目录,并说明文件名
ECharts代码模板:
```python
import subprocess
import sys
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'pyecharts', 'snapshot-selenium'])
from pyecharts.charts import Bar, Line, Pie, Scatter
from pyecharts import options as opts
from datetime import datetime
# 创建图表(示例:柱状图)
bar = (
Bar()
.add_xaxis(["Mon", "Tue", "Wed", "Thu", "Fri"])
.add_yaxis("Sales", [120, 200, 150, 80, 70])
.set_global_opts(title_opts=opts.TitleOpts(title="Sales Chart"))
)
# 生成HTML文件
chart_name = f'chart_{datetime.now().strftime("%Y%m%d_%H%M%S")}.html'
bar.render(chart_name)
print(f"交互式图表已保存:{chart_name}")
```
"""
if self.chart_engine == 'echarts':
system_prompt = base_prompt + echarts_addition
else:
system_prompt = base_prompt + """
MATPLOTLIB图表生成规则:
* 使用matplotlib生成图表,保存为PNG文件
* 保存到当前目录并说明文件名
* 所有文本使用英文(没有中文字符集)
"""
Strands Agents框架参考
https://strandsagents.com/latest/
亚马逊云科技Marketplace
https://awsmarketplace.amazonaws.cn/marketplace/pp/prodview-65lo53ldx6wda?sr=0-2&ref_=beagle&applicationId=AWSMPContessa
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |