亚马逊AWS官方博客
SAP云上自适应跨可用区高可用方案
SAP云上跨可用区高可用架构现状
在SAP云上官方架构设计指引中,展示了如何利用其多可用区的技术优势、诸如Route 53、NLB等基础设施服务以及SAP或操作系统的高可用技术实现端到端的跨可用区高可用方案。

此架构优点是符合SAP与亚马逊云科技最佳实践的无单点故障跨可用区高可用方案,而且易于实现,只需要安装部署人员按照官方指引或者使用Amazon QuickStart/LaunchWizard就可以实现;但对于追求云上最佳用户体验的客户,其可能需要考虑如下问题:由于同区域内不同可用区之间的延迟必然远远高于同可用区内的延迟,如当可用区AZ2上的SAP应用实例与可用区AZ1上的HANA数据库主实例交互时,其运行的程序均会受到延迟的影响形成性能影响;这造成了终端用户或程序将有50%的概率获得比较明显的体验差异。

以上ABAPMeter的结果来自一套根据SAP云上官方架构设计指引设计在亚马逊云科技北京区域搭建的SAP系统,其中saptstapp01与数据库主节点放在同一可用区内,而saptstapp02位于与数据库主节点不同的可用区;可以看到由于跨可用区的网络延迟,saptstapp02的数据库访问性能(数据列Acc DB与E. Acc DB)比saptstapp01慢了近7倍,根据ABAPMeter的源码,此数值为循环200次简单数据库单行查询(SELECT SINGLE)的总时间;除了SAP官方推荐此数值应低于150ms(SAP Note 2879613)之外,值得一提的是不同节点数据库性能表现的差异将是造成终端用户日常体验差异的一个巨大隐患。
更进一步地分析,这种由延迟差异所造成的性能表现差异是由SAP应用的数据库访问特点造成的;SAP作为数据库交互密集型的应用,为其ABAP开发人员提供了OPEN SQL这样的数据库交互层,而其强大灵活的功能使得程序的数据库开发模式多种多样,具体来说,跨可用区的延迟将对如下几种程序编写模式产生显著影响。
- 使用游标逐行fetch大结果集
- 通过SQL一次性取出大结果集保存在内表(itab),然后对其进行循环,并在循环中再进行一次或多次数据库查询
- 密集型逐条插入/删除/修改
- 存在大量短小的数据库访问
实际上这些场景并不少见,而且根据上面的ABAPMeter测试结果来看,对于上述数据库密集型访问模式,传统高可用方案中不同可用区的SAP应用节点的处理性能差异将会接近7倍;虽然通过批量fetch,优化程序逻辑等方法可以缓解延迟造成的性能问题,但我们认为为了适配高可用架构来调整应用程序并不是一个好的选择,相反,这将成为在云上获得最佳表现的一个巨大阻碍。
自适应方案设计与解决思路
解决这个问题的最好方法,是将活动的SAP应用与SAP数据库主实例始终放在同一个可用区里,这样它们之间的交互就不会因为跨可用区的延迟受到影响,也避免了跨可用区流量造成的额外费用;但是这样做的问题也显而易见:SAP应用实例失去了天然的跨可用区的保护,一旦遇到可用区级的故障,需要额外的方案或人为介入来保障业务连续性。
以此为背景,在本博客中,我们会详述具备SAP系统跨可用区高可用冗余与最优延迟兼具的架构方案(SAP云上自适应跨可用区高可用架构)。
什么是自适应
本博客中最核心的“自适应”的目标是:在总体资源成本不增加的情况下,利用亚马逊云科技云原生服务,在云上构建一套SAP高可用系统架构,使得SAP的实际负载实例(ABAP/Java Server)以及SAP ASCS实例自动随着SAP HANA主实例所处之可用区进行平滑转换,从而移除跨可用区访问的延迟问题。
其方案架构概览如下图所示:
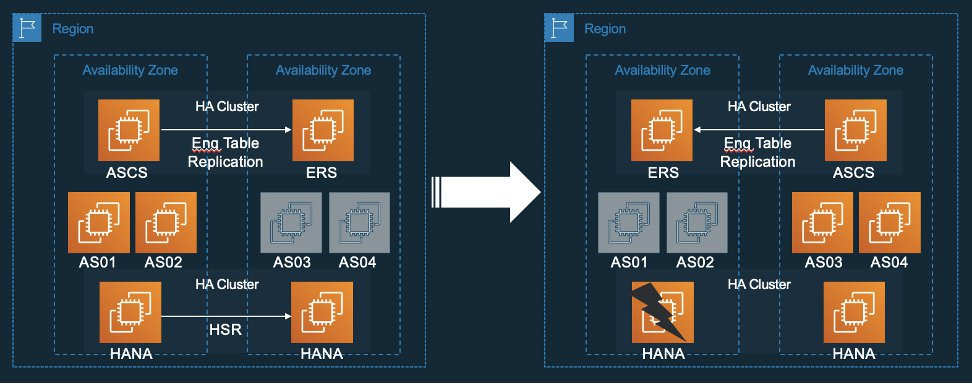
在此架构方案中,SAP应用实例AS01/02始终与HANA主实例所在可用区保持一致,在另一个可用区,预先准备好SAP应用实例AS03/04供自适应流程进行管理,二在自适应流程过程的最后,AS01/02将被正常关闭。
为了实现这个架构,需要实现以下三个核心功能:
- 可靠的事件总线、针对事件的处理流程以及关键事件的捕获
- SAP系统整体可用区转换的流程处理
- 使用SAP系统即代码思想(SAP as Code)控制SAP实例
接下来我们将会逐一介绍如何攻克这些核心点的设计思路
SAP Netweaver架构回顾
在介绍如何核心功能设计之前我们先快速回顾一下传统的SAP的高可用架构。
在SAP高可用最佳实践中,一个可靠的高可用集群处于最为重要的位置。纵观SAP的整体架构,要构造无单点故障的架构,对以下三个核心组件的保护至关重要。
- Global Filesystem(/sapmnt/<SID>等)
- SAP ASCS实例
- SAP HANA数据库实例
对于这些关键组件如何实现高可用可以参考SUSE的官方文档,总体来说,除了Global Filesystem这个可以使用云原生服务(Amazon EFS)提供支持的组件,对于SAP ASCS实例与SAP HANA数据库实例来说,EC2+集群软件是最好的选择,对此客户可以选择Windows的集群服务、也可以选择SLES与RHEL都支持的Pacemaker Linux高可用集群,或者像SIOS、Veritas等第三方集群件方案。我们将基于客户群体最为广泛的Pacemaker进行展开。
在Pacemaker中,SAP的应用实例与HANA实例均作为集群资源,集群将视资源状态、预设规则、资源分值与节点故障事件等作为触发条件对资源进行管理。在一套SAP高可用架构中,通常会存在包含SAP ASCS/ERS实例(也可以选择将SAP的ABAP/Java Server也放在这个集群里)与SAP HANA实例的两个核心的高可用集群,其中的SAP HANA集群负责着自适应方案最关心的SAP HANA主实例的切换。
可靠的事件总线、针对事件的处理流程以及关键事件的捕获
总体来说,要实现一套自适应的自动化流程处理框架,我们需要事件总线、流程引擎以及执行函数。
对于事件总线的选择,亚马逊云科技提供的云原生事件总线服务 – Amazon EventBridge能够完全满足我们的需要;同时其能够帮助我们集成云原生的流程引擎– Amazon Step Functions, 并最终集成执行函数Amazon Lambda。
由上面提到的SAP Netwever高可用架构我们可以知道,事件的来源可以通过持续监控SAP HANA(集群)的状态来获得,但是我们认为这不是最佳的选择,事实上SAP HANA集群本身已经在不断进行SAP HANA实例状态的检查了,我们认为最佳的方法是让集群负责推送其关键事件至我们的事件总线,从而形成事件驱动的特性。
基于集群件的功能扩展,Pacemaker原生提供事件通知的扩展功能,客户可以选择使用底层的alert功能或者自带的监控资源ClusterMon来进行。客户可以通过自定制可执行脚本的方式让alert或者ClusterMon调用,并在脚本中进一步使用awscli或者诸如boto3的sdk将重新封装的事件推送至由Amazon EventBridge的事件总线。
那么事件的内容具体如何获得呢?在Pacemaker触发alert时,其fork的调用进程的环境变量里会包含诸如以下等重要信息:
CRM_alert_kind
CRM_alert_version
CRM_alert_recipient
CRM_alert_node_sequence
CRM_alert_timestamp
CRM_alert_node
CRM_alert_desc
…
以此为基础,客户可以选择自己的方式将这些信息序列化并封装到事件中,一并传至事件总线;同时为了识别事件,客户可以客制事件头信息,诸如
{
"detail-type": [
"saptstdb01" <= 数据库节点Hostname
],
"source": [
"bcs-sac-adaptive-cluster" <= 事件来源标识
]
}
以帮助Amazon EventBridge Rule以及目标无服务器框架进行捕获。
当然为了让集群的EC2实例能够推送事件至EventBridge集群总线,可以使用EC2 Instance Role并确保附加诸如如下的Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "events:PutEvents",
"Resource": "<arn-of-the-event-bus>"
}
]
}
在事件总线的另一头,我们将配置合适的Event Rule来捕获从集群发来的事件,并过滤关键触发事件(SAP HANA的切换事件)来触发自适应跨可用区转换流程。
SAP系统整体可用区转换的流程处理
这个流程是整个架构方案的最关键所在。由于事件驱动,自适应的SAP系统可用区转换流程需要能够解决如下问题
- 能够应对事件乱序送达或者未送达情况
- 能够在转换过程中针对突发性事件(诸如SAP HANA实例切换失败)进行调整
- 能够保障应用实例可用区转换的效率
亚马逊云科技的Step Functions与Lambda提供了强大并且足够灵活的编排功能帮助客户克服以上三个难点(当然我们认为拥有一套SAP as Code框架将进一步地让整个过程变的更简单)。另外,使用Amazon SQS队列提供对事件信息的缓存也是关键;一是这样能够帮助缓解事件乱序的问题,二是流程本身将能随着新事件的到达进行推演与响应;从效率角度来说,等到整个SAP HANA主实例切换完成之后再对SAP系统进行调整是我们极力想要避免的情况,因为这样做会拉长整个的RTO时间,而在切换流程里穿插各种能够提前完成的事情(如EC2的启动)可以极大提升效率,再者如果出现中断性时间(如切换失败),流程也可以做到将系统架构回滚至理想状态并触发报警以避免不必要的资源浪费,这样就做到了真正的自适应。

在整个方案中,Cluster Event Poller是整个流程的大脑,在触发流程之后,其会根据新的事件类型决定下一步的操作,比如SAP HANA Overlay IP在某个节点的启动是触发流程的关键事件,在捕获到此事件后Poller会触发目标可用区SAP应用实例所在EC2的启动流程,在完成之后Poller会等待来自SAP HANA集群EC2节点的其他事件,如果收到了SAP HANA切换成功的事件,将继续触发启动SAP应用实例的启动,在收到到集群对SAP HANA主实例的监控成功事件后,流程将启动ASCS的切换。具体的参考流程如下图所示。

在转换完成之后,流程最终将处理另一个可用区资源的停止以节省资源,在以上示例中我们直接停止了原可用区中的SAP应用实例与EC2资源(如对应可用区可以访问);根据客户的实际需求,这个步骤是可以进行进一步优化的,其方向为:将SAP logon group与background job group的调整集成至此流程,并配合SAP的soft stop让整个过程变得更加顺滑。
在SLA的满足方面,我们将其分为两个场景

以SAP HANA主实例故障为例,相较于传统场景,自适应方案下的SAP系统不可用时间不会因为自适应场景变长。

而如果故障场景是整个可用区故障,相较于传统场景,自适应方案下的SAP系统不可用时间会比传统方案多1-2分钟(目标可用区SAP应用实例的启动时间),但从其对日常SAP系统性能的保障(完全移除跨可用区访问的7倍性能差异)等优点来看,以这个微小的延迟作为代价是可以接受的。
使用SAP系统即代码思想(SAP as Code)控制SAP实例
在自适应转换流程里,有着大量与SAP系统相关的操作步骤,比如SAP应用实例的启停与状态的预检,这往往都涉及相关操作系统命令的执行,而且具体的命令也与操作系统版本与对应SAP应用实例是否由集群件管理有着直接联系。
客户需要通过Amazon Lambda以及Amazon Systems Manager实现能够基于标签(tag)定位到具体SAP应用实例所在的EC2实例的方法;针对不同的SAP应用实例类型将其封装成程序对象进行操作将能够简化这些步骤,并且这将使流程将变得通用化;具体的思路是将SAP系统的SID、实例号以及实例角色等控制SAP实例所需要的信息作为元数据保存在SAP as Code框架能够访问的持久化服务中,在使用时将这些信息装载到对象中,并对其进行操作。
以下是亚马逊专业咨询服务团队SAP as Code框架的配置示例,有这些信息,SAP as Code框架便能生成SAP实例的代码对象,并对其进行操作
#SAP PAS
saptstas01:
Template: /sap/instances/sapapp
System: TST
Properties:
InstanceName: D00
InstanceNumber: 00
Role: PAS
EC2Instance: saptstapp01
saptstapp01:
Template: /ec2/instances/sapapp
定位SAP应用实例所在的EC2 Instance也很重要,我们同样可以通过上述SAP实例配置信息配合EC2 Tag最终定位目标EC2实例,以下为标签示例:

在定位到EC2实例后,我们可以对其执行操作系统级命令,我们建议选择安全可靠的Amazon Systems Manager Agent,并使用Amazon SSM的SendCommand在对应EC2实例中运行SAP实例的启停/监控命令。
示例:
要定位可用区A1中的SAP系统(TST)的PAS与AAS应用实例所在EC2实例我们需要
通过以下条件进行过滤得到实例信息
- bcs:sac:sap-sid:TST 等于 True
- bcs:sac:sap-role 包含 PAS 或者 AAS
- 实例子网所在可用区等于 AZ1
通过调用SSM SendCommand发送启停指令至目标EC2实例以控制对应的SAP实例,如
例如应用实例不由集群控制,可以围绕sapcontrol构建shell脚本完成对实例的控制
# sapcontrol -nr <SAPInstanceNumber> -function Stop
例如应用实例由集群控制,则可围绕crmsh或者pcs来控制pacemaker集群资源完成对实例的控制
# crm resource stop <目标pacemaker资源名>
自适应方案的架构变种
借助自适应方案的编排能力,我们甚至可以衍生出一些变种方案,以进一步提升自适应方案带来的价值
注:以下架构变种均保留了与自适应方案同样的低延迟访问特性
架构变种之一:弹性的传统数据库复制
在亚马逊云科技专业咨询服务团队的实际实施案例中,我们的SAP客户所使用的SAP系统不一定跑在SAP HANA数据库上,但这不妨碍我们帮助那些运行在传统数据库的客户获得SAP系统的自适应能力。
同时对于传统数据库来说,其存储资源往往在资源总成本构成中是最大的,运行于Oracle数据库之上的SAP系统,为满足动辄TB级别的数据文件与性能要求,必须配置大容量的高性能磁盘;而在一个主备双机环境中,其成本将翻倍;但作为备节点的数据库往往只承载数据写入的请求,因此备节点的I/O需求与主节点存在天壤之别(尤其是OLTP类型的系统);此时,如果我们利用Amazon EBS带来的磁盘类型弹性调整特性,在平时保持备节点的数据卷使用较低性能且满足写入需求的低成本磁盘,而只在切换时利用自适应流程对磁盘类型提升至高性能的gp3或者io1/io2,将为客户带来显著的成本降低。

主备库之间的复制技术可以选择数据库原生复制方案或者类似DRBD的块复制方案,并由集群管理,同时由于备库日志卷的写入要求可能较高,完全可以将体量较小的日志卷独立出来并配置高性能磁盘来满足分流复制的I/O写入压力。在此方案下,对于10TB的数据卷使用st1作为磁盘类型,每套SAP生产系统的日常的磁盘费用可以降低近25%。
这个架构变种的缺点是备库在拉起之后需要一段时间(通常为数小时)才能使得I/O性能恢复到最佳状态,考虑到I/O子系统的满负荷运行并不是常态,客户可以根据实际需求选择是否采用这个架构变种。
架构变种之二:重用SAP HANA备节点
在一套以SAP HANA作为数据库的SAP系统中,资源利用率最低的部分是其SAP HANA的备节点,为了切换过程本身的顺利完成以及切换之后SAP HANA能够正常运行,客户需要配置一台与SAP HANA主节点同等大小的EC2实例。对此SAP与亚马逊云科技提供了一个降低费用的选项Automatic Recovery & HSR without Data Preload (Warm Standby + Dev/QA);在关闭备节点的列存储preload参数后,可以将该SAP系统的DEV/QAS SAP HANA数据库运行于备节点上以最大化提升资源利用率;但在传统做法中,其最大的缺点是客户需要自己确保SAP HANA在切换前,这些DEV/QAS 的SAP HANA实例被关闭,从而避免切换过程的失败,这直接引入了不可控的人为介入并造成了RTO时间的极大延长。如果依托于自适应方案,这个过程完全可以被自适应流程自动化,并且停止DEV/QAS SAP HANA库的操作完全能与PRD SAP HANA备节点的接管过程并行触发,从而在获得成本节省的同时不必为RTO的延长妥协。

此架构变种可以显著提升SAP HANA备节点的资源利用率,对于一套典型的SAP环境(包含DEV/QAS/PRD以及HA),其将为客户带来近30%的TCO降低。
此架构变种的缺点便是使用preload off以后,切换时间相较于preload on会有所延长,同时SAP HANA备节点接管后,也会有一个预热过程以处理未能提前加载到内存的列存储数据。客户视情况选择是否采用此架构变种。
结语
在本博客中,我们介绍了SAP云上高可用的新设计思路,客户可以根据此博客的指引设计搭建属于自己的SAP云上自适应跨可用区高可用方案。当然目前亚马逊云科技专业咨询服务团队团队已在多个客户项目中落地并交付了此方案,在此我们欢迎客户联系自己的销售代表进行洽谈。
参考和帮助
Amazon Web Services SAP技术文档:https://docs.aws.amazon.com/sap/latest/sap-netweaver/net-win-high-availability-system-deployment.html
Amazon EventBridge官方链接:https://amazonaws-china.com/cn/eventbridge/
Amazon Lambda官方链接:https://amazonaws-china.com/cn/lambda/
Amazon Step Functions官方链接:https://amazonaws-china.com/cn/step-functions/
ClusterMon介绍:https://github.com/ClusterLabs/resource-agents/blob/master/heartbeat/ClusterMon
Pacemaker alert介绍:https://clusterlabs.org/pacemaker/doc/en-US/Pacemaker/1.1/html/Pacemaker_Explained/ch07.html
SUSE SAP高可用官方文档:https://documentation.suse.com/sbp/all/html/SLES4SAP-hana-sr-guide-PerfOpt-12_AWS/index.html