项目背景
飞书深诺是中国领先的出海数字营销企业,专注为中国企业提供一站式海外数字营销解决方案,每年管理300亿人民币广告预算,服务近10万家企业出海,产品销往全球230多个国家和地区。其中Datahub 是飞书深诺技术产品事业群数据中台部门,依托飞书深诺独家资源构建的行业大数据底座,多年来为公司多部门提供支撑服务。电商广告行业分类作为数据基础能力建设的一部分,在行业benchmark、账户/站点/签约主体的行业判断等场景中起到关键作用。
Amazon Bedrock 是一项完全托管的服务,通过 API 提供来自Amazon、 AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI 等领先人工智能公司的高性能基础模型(FM),并提供通过安全性、隐私性和负责任的人工智能构建生成式人工智能应用程序所需的一系列广泛功能。
2024年以前,飞书深诺广告分类的技术方案主要依托于自行训练的深度学习模型。为提升模型学习效率并降低模型迭代成本,2024年起,从传统深度学习模式切换为多模态大语言模型识别模式,采用由 AWS 提供的 Claude Sonnet 3.5/3.7 以及Nova模型,达成了同步降本和准确识别的目标。
解决方案设计
广告分类任务
广告分类任务涉及分析各种广告素材(图像、视频、文本)并将其分类到特定的行业类别中。这有助于更好地理解市场细分、竞争对手分析和有针对性的广告策略。
而广告素材来源于不同的广告客户,有着不同的类型与风格。广告素材由于投放的渠道,投放的展示位置不同,有着不同的类型和尺寸大小。为了方便下游业务系统进行分析,需要对这些不同的广告素材进行统一处理,因此需要引入统一的分类类目,然后使用多模态模型对广告素材进行处理,归类到统一的分类类目中。
详细解决方案
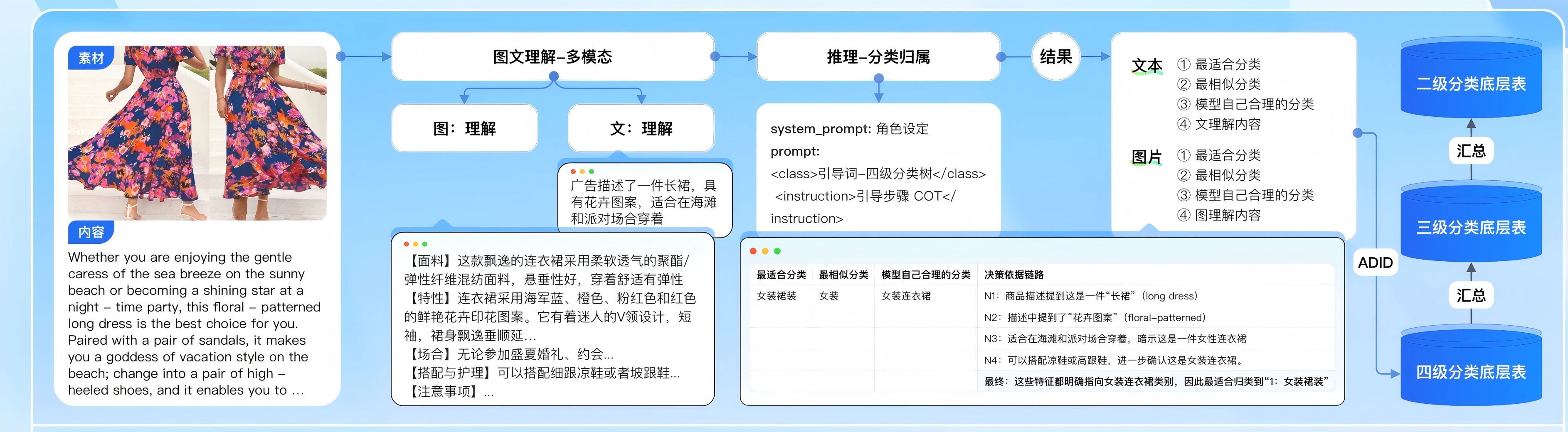
我们的解决方案采用三阶段流水线架构,充分发挥AWS生成式AI服务的优势,实现从原始素材到精准分类的全流程自动化处理。这种三阶段架构设计既保证了处理效率,又确保了分类精度,为飞书深诺的广告业务提供了强有力的技术支撑。
第一阶段:数据输入与预处理
广告系统的入口环节,系统首先接收来自客户的多样化广告素材,包括视频、图片和文本等不同类型。随后,通过智能路由技术自动识别并分类这些素材的类型,为每种素材确定最合适的处理路径。接下来,系统对各种格式的素材执行标准化预处理操作,如视频长度调整、格式转换、尺寸调整、或文本规范化等,最终将所有素材转化为统一的数据格式,为后续的分析和处理阶段奠定基础。
Amazon Nova模型系列对于图片和视频的要求
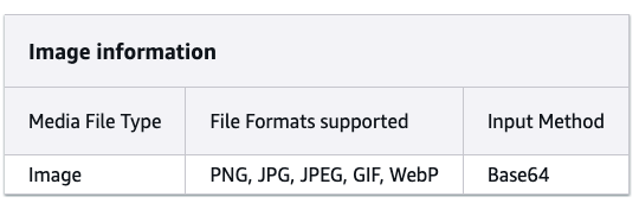
Amazon Nova 模型配备了新颖的视觉功能,使该模型能够理解和分析图像和视频。提供的图像或视频质量越高,模型准确理解媒体文件中信息的机会就越大。确保图像或视频清晰,且没有过多的模糊或像素化,以保证更准确的结果。如果图像或视频帧包含重要的文本信息,请确认文本清晰且不要太小。避免仅仅为了放大文本而剪掉关键视觉上下文。
Amazon Nova 模型允许您在有效载荷中包含多张图像。总有效载荷大小不能超过 25 MB。Amazon Nova 模型可以分析传递的图像并回答问题、对图像进行分类以及根据提供的说明汇总图像。
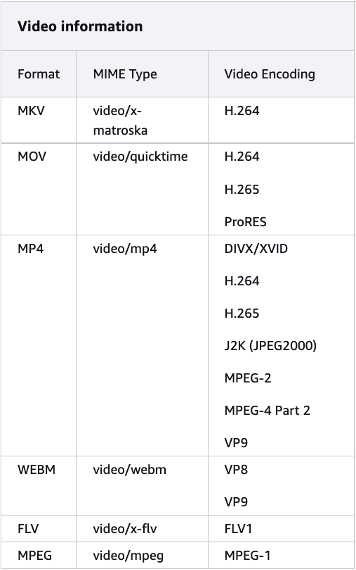
Amazon Nova 模型允许您在有效载荷中包含单个视频,可采用 base64 格式提供,也可以通过 Amazon S3 URI 提供。使用 base64 方法时,总有效载荷大小必须在 25 MB 以内。但是,您可以指定 Amazon S3 URI 来理解图像、视频和文档。使用 Amazon S3 让您能够利用该模型处理更大的文件和多个媒体文件,而不受整体有效载荷大小限制约束。Amazon Nova 可以分析输入视频并回答问题、对视频进行分类,并根据提供的说明汇总视频中的信息。
针对不满足Nova处理条件的图片或视频,可先进行预处理,将其格式化为Nova可接受的媒体格式和大小。例如,使用FFmpeg对本地文件进行预处理的示例代码如下:
Python
import ffmpeg
import os
def transform_video(file_name):
# 获取文件大小(以字节为单位)
file_size_bytes = os.path.getsize(file_name)
# 将文件大小转换为合适的单位(例如 MB)
file_size_mb = file_size_bytes / (1024 * 1024)
print(f'视频文件大小为: {file_size_mb:.2f} MB')
# 指定新的输出文件路径和名称
output_filename = os.path.splitext(os.path.basename(file_name))[0] + '_proccessed.mp4'
output_path = "media/" + output_filename
# 检查输出文件是否已存在
if os.path.isfile(output_path):
# 如果文件存在,则删除旧文件
os.remove(output_path)
# 如果视频文件过大,超过25MB,则压缩一下
if file_size_mb > 25:
print(f'视频文件大于25MB,需要压缩\n')
try:
probe = ffmpeg.probe(file_name)
# 检查视频流是否存在
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print(f"{file_name} does not contain a video stream.")
else:
# 获取视频分辨率
video_width = video_stream['width']
video_height = video_stream['height']
print(f"Original Video resolution: {video_width}x{video_height}")
# 计算新的分辨率(长宽各为原来的一半)
new_width = video_width // 2
new_height = video_height // 2
# 设置ffmpeg流
stream = ffmpeg.input(file_name)
# 设置视频编码器和分辨率
stream = ffmpeg.filter(stream, 'scale', new_width, new_height)
stream = ffmpeg.output(stream, output_path, vcodec='libx264', acodec='aac', f='mp4', crf=23, preset='veryfast')
# 运行 FFmpeg 命令
ffmpeg.run(stream, overwrite_output=True)
print(f'视频压缩成功,输出文件: {output_path}')
except ffmpeg.Error as e:
print(f"Error: {e.stderr}", e.stdout)
# 如果视频格文件编码为 Nova不支持的类型,尝试转为 Nova 支持的编码H264
else:
print(f'视频文件大小OK,直接转成H264')
# 设置ffmpeg流
stream = ffmpeg.input(file_name)
stream = ffmpeg.output(stream, output_path, vcodec='libx264', acodec='aac', f='mp4')
# 运行ffmpeg命令
ffmpeg.run(stream)
print(f'Video converted to H.264 and saved as {output_path}')
# 返回新的处理后的文件全路径
return output_path
第二阶段:多模态理解
在第一阶段,使用多模态大语言模型对广告素材内容进行描述,接收视频、图片、文本三种主要类型的素材。大语言模型能够处理并理解这些内容,并生成内容描述与总结文本。
Amazon Nova模型能够处理文本、图像、视频等多种模态的数据,可以直接输出综合描述。系统能够识别这些不同类型的素材,并进行初步的内容理解和特征提取。我们可以将广告素材直接输入到Nova模型对视频、图像内容进行理解。
Nova通过sdk可以能够直接处理视频片段,例如针对本地视频理解,使用到的参考提示词和示例代码如下:
Python
import base64
import boto3
import json
def video_understanding(file_name):
# Create a Bedrock Runtime client in the AWS Region of your choice.
client = boto3.client(
"bedrock-runtime",
region_name="us-east-1",
)
MODEL_ID = "us.amazon.nova-lite-v1:0"
# Open the image you'd like to use and encode it as a Base64 string.
with open(file_name, "rb") as video_file:
binary_data = video_file.read()
base_64_encoded_data = base64.b64encode(binary_data)
base64_string = base_64_encoded_data.decode("utf-8")
# Define your system prompt(s).
system_list= [
{
"text": "You are a expert to understand advertising video materials."
}
]
# Define a "user" message including both the image and a text prompt.
message_list = [
{
"role": "user",
"content": [
{
"video": {
"format": "mp4",
"source": {"bytes": base64_string},
}
},
{
"text": "Please understand and describe the information in the video, focusing on the product info to classify the product. Within 100 words."
},
],
}
]
# Configure the inference parameters.
inf_params = {"maxTokens": 3000, "topP": 0.1, "topK": 20, "temperature": 0.3}
native_request = {
"schemaVersion": "messages-v1",
"messages": message_list,
"system": system_list,
"inferenceConfig": inf_params,
}
# Invoke the model and extract the response body.
response = client.invoke_model(modelId=MODEL_ID, body=json.dumps(native_request))
model_response = json.loads(response["body"].read())
# Pretty print the response JSON.
print("[Full Response]")
print(json.dumps(model_response, indent=2))
# Print the text content for easy readability.
content_text = model_response["output"]["message"]["content"][0]["text"]
print("\n[Response Content Text]")
print(content_text)
return content_text
针对视频文件过大(大于25MB),或者文件已保存在AWS S3中的视频,可直接指定其来源为S3,无须本地再下载,直接读取S3并理解的示例代码如下:
Python
import base64
import boto3
import json
def video_understanding_for_s3(s3_uri):
# 创建 STS 客户端
sts_client = boto3.client('sts')
# 获取账户 ID
account_id = sts_client.get_caller_identity()['Account']
# Create a Bedrock Runtime client in the AWS Region of your choice.
client = boto3.client(
"bedrock-runtime",
region_name="us-east-1",
)
MODEL_ID = "us.amazon.nova-lite-v1:0"
# Define your system prompt(s).
system_list = [
{
"text": "You are a expert to understand advertising video materials."
}
]
# Define a "user" message including both the image and a text prompt.
message_list = [
{
"role": "user",
"content": [
{
"video": {
"format": "mp4",
"source": {
"s3Location": {
"uri": f"{s3_uri}",
"bucketOwner": f"{account_id}"
}
}
}
},
{
"text": "Please understand and describe the information in the video, focusing on the product info to classify the product. Within 100 words."
}
]
}
]
# Configure the inference parameters.
inf_params = {"maxTokens": 300, "topP": 0.1, "topK": 20, "temperature": 0.3}
native_request = {
"schemaVersion": "messages-v1",
"messages": message_list,
"system": system_list,
"inferenceConfig": inf_params,
}
# Invoke the model and extract the response body.
response = client.invoke_model(modelId=MODEL_ID, body=json.dumps(native_request))
model_response = json.loads(response["body"].read())
# Pretty print the response JSON.
print("[Full Response]")
print(json.dumps(model_response, indent=2))
# Print the text content for easy readability.
content_text = model_response["output"]["message"]["content"][0]["text"]
print("\n[Response Content Text]")
print(content_text)
return content_text
第三阶段:多模态分类
系统对预处理完成的素材进行深度分析,将广告图片内容与相应的广告语文本进行智能关联和联合分析,从而获取更全面的语义理解。随后,这些关联数据通过标”四级分类模型”的精细化处理流程,层层递进地进行类别划分和特征提取,最终生成详尽的视频理解内容文本,完成对广告素材的全方位分类标注 ,为后续的精准投放奠定数据基础。
四级分类模型
电商广告素材存在多种品类,以及大类中包含多级子分类的嵌套分类结构,为了跟各主流电商平台衔接,同时便于SKU管理,现将所有素材统一归为四级分类:
| category_level1_name_ch |
category_level2_name_ch |
category_level3_name_ch |
category_level4_name_ch |
| 商品 |
服装 |
女装 |
女装裙装 |
| 商品 |
服装 |
女装 |
女装T恤 |
| 商品 |
服装 |
女装 |
女装外套/大衣 |
| 商品 |
服装 |
女装 |
女装裤装/牛仔裤 |
| 商品 |
服装 |
女装 |
女装西服/套装 |
| 商品 |
服装 |
女装 |
女装衬衫 |
| 商品 |
服装 |
女装 |
女装毛衣/卫衣 |
| 商品 |
服装 |
女装 |
女装睡衣/家居服 |
| 商品 |
服装 |
女装 |
女装丝袜/袜子 |
| 商品 |
服装 |
女装 |
女装-其他 |
| 商品 |
服装 |
男装 |
男装T恤 |
| 商品 |
服装 |
男装 |
男装西服/套装 |
| 商品 |
服装 |
男装 |
男装衬衫 |
| 商品 |
服装 |
男装 |
男装裤装/牛仔裤 |
| 商品 |
服装 |
男装 |
男装外套/大衣 |
| 商品 |
服装 |
男装 |
男装毛衣/卫衣 |
| 商品 |
服装 |
男装 |
男装睡衣/家居服 |
| 商品 |
服装 |
男装 |
男装袜子 |
| 商品 |
服装 |
男装 |
男装-其他 |
针对原始的分类,需要对其格式化,以便于后续输入给LLM进行处理。以下为两种常见的处理方式:
多级分类-带ID号
JSON
[
{
"category_id": "1",
"name": "服装",
"children": [
{
"category_id": "1-1",
"name": "女装",
"children": [
{
"category_id": "1-1-1",
"name": "女装裙装"
},
{
"category_id": "1-1-2",
"name": "女装T恤"
},
{
"category_id": "1-1-3",
"name": "女装外套/大衣"
},
{
"category_id": "1-1-4",
"name": "女装裤装/牛仔裤"
},
{
"category_id": "1-1-5",
"name": "女装西服/套装"
},
{
"category_id": "1-1-6",
"name": "女装衬衫"
},
{
"category_id": "1-1-7",
"name": "女装毛衣/卫衣"
},
{
"category_id": "1-1-8",
"name": "女装睡衣/家居服"
},
{
"category_id": "1-1-9",
"name": "女装丝袜/袜子"
},
{
"category_id": "1-1-10",
"name": "女装-其他"
}
]
},
...
多级分类-不带ID号
JSON
[
{
"name": "服装",
"children": [
{
"name": "女装",
"children": [
{
"name": "女装裙装"
},
{
"name": "女装T恤"
},
{
"name": "女装外套/大衣"
},
{
"name": "女装裤装/牛仔裤"
},
{
"name": "女装西服/套装"
},
{
"name": "女装衬衫"
},
{
"name": "女装毛衣/卫衣"
},
{
"name": "女装睡衣/家居服"
},
{
"name": "女装丝袜/袜子"
},
{
"name": "女装-其他"
}
]
},
...
由于LLM已具备很强的理解能力,以上两种方式对于LLM的理解精度无较大差异。”多级分类-带ID号”的方式,由于保留了ID号,便于同除LLM之外的其他业务代码相衔接;”多级分类-不带ID号”的方式则更简洁,便于节省LLM input token数。可按照实际需求灵活选择。
因Claude Sonnet系列模型具备更强的逻辑推理能力,因此使用Claude 3.7 Sonnet模型做最后的分类处理。同时,考虑到四级分类在每次调用LLM时,都不会变,因此可以考虑利用Bedrcok Prompt Caching功能,将其分类列表进行缓存,以便加快推理速度,同时节省大量的input token消耗。
使用Claude 3.7 Sonnet模型做分类的参考提示词和示例代码如下:
Python
from botocore.config import Config
import json
import re
#role 方式初始化bedrock
config = Config(read_timeout=1000) # second
bedrock_runtime = boto3.client('bedrock-runtime', config=config)
def generate_message(bedrock_runtime, model_id, system_prompt, messages, max_tokens):
body=json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"temperature": 0.1,
"top_k": 20,
"top_p": 0.9,
"system": system_prompt,
"messages": messages
}
)
# print(body)
response = bedrock_runtime.invoke_model(body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())
return response_body
def video_classify(content):
# 打开文件并读取4级分类格式化好的JSON数据
with open('category_no_id.json', 'r', encoding='utf-8') as f:
data = json.load(f)
# 将JSON数据转换为字符串,并去除所有空白字符
category_json = re.sub(r'\s+', '', json.dumps(data, ensure_ascii=False,separators=(',', ':')))
prompt=f'''
<class>
{category_json}
</class>
<instruction>
1. 你的任务是将给定的广告视频描述<video_description>,准确分类到<class>预定义的1级,2级和3级类别中。
2. 从上述<class>类别中选择最匹配的1级,2级和3级子类别,需要1,2,3级分类都需要给出,如果无法确定分类,回答"0"。
3. 请回复完整分类,包括ID,不需要其他解释。
4. 直接给出答案,无需前言。
</instruction>
<output_format>
服装|女装|女装裙装
</output_format>'''
text_video = f'''
<video_description>
{content}
</video_description>
'''
# 使用prompt caching功能,将不变的分类列表caching住
prompt_final = [{"type": "text","text": prompt, "cache_control": {"type": "ephemeral"}}, {"type": "text","text": text_video}]
# model_id='anthropic.claude-3-5-sonnet-20240620-v1:0'
model_id = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
system_prompt = "你是一个专业的广告视频内容分类机器人,专门负责分析和分类广告视频。"
max_tokens = 1000
user_message = {"role": "user", "content": prompt_final}
messages = [user_message]
# print(messages)
response = generate_message(bedrock_runtime, model_id, system_prompt, messages, max_tokens)
print(response)
return response['content'][0]['text']
结果评估
通过以上方案,我们进行了一系列实验验证,使用多模态Nova Pro模型进行视频理解 + Claude 3.7 Sonnet进行标签分类,并与之前传统的机器学习方法进行了对比。在探索大型模型能力边界的过程中,我们得出了一个关键结论:大型模型并非无所不能。它们能够将成绩较差的偏科学生提升至中上等水平,使他们的表现更加均衡,但不能直接将差学生转变为顶尖学生。
实验数据显示,在图像处理方面,同样的图像和视频样本,在Claude 3.7模型下的识别准确性从传统机器学习方法的44.5%提升至85%。此外,Claude 3.7在推理任务上也表现出明显的准确性提升,特别是在复杂推理能力方面。
为验证这些发现的稳定性,我们收集了一个月内的 1.1万条数据进行验证,这些数据包括了各种各样的商品细分品类。在随机抽取的103个分类中,约90.3%(93个)呈现上升趋势,仅9.7%(10个)呈现下降趋势,进一步证实了大型模型在涉及众多商品品类的分类任务中,无须任何提前训练,在绝大部分的分类任务中,表现都优于传统机器学习方法,表现出很好的准确率与稳定性。
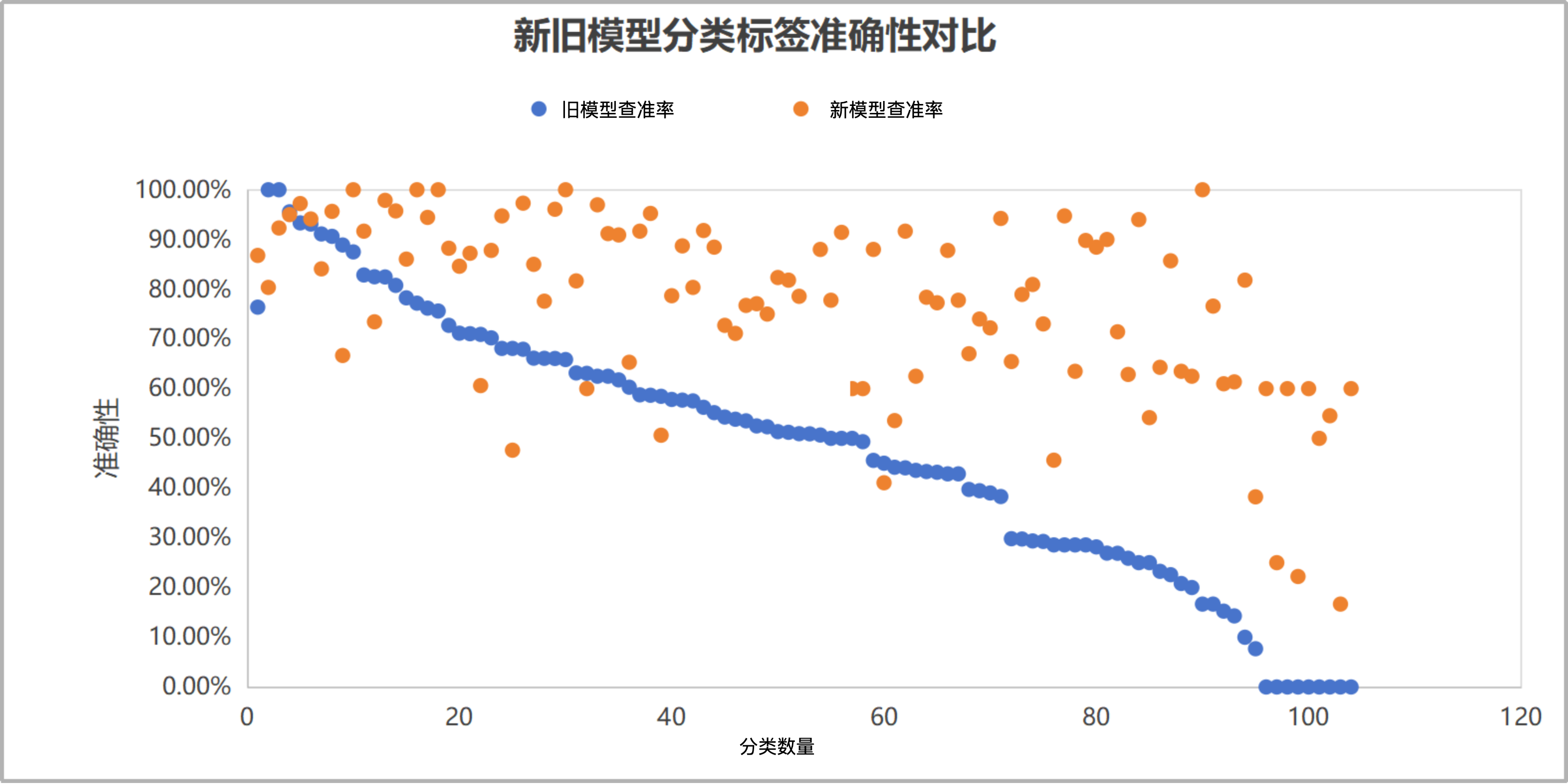 |
| 准确率(60%以上) |
|
准确率(30%~60%) |
准确率(低于30%) |
| 四级分类 |
旧模型 |
新模型 |
|
四级分类 |
旧模型 |
新模型 |
|
四级分类 |
旧模型 |
新模型 |
| 准确率 |
76.39% |
86.79% |
准确率 |
49.50% |
76.81% |
准确率 |
16.90% |
65.34% |
| 健康检测设备 |
100.00% |
80.36% |
耳环/耳钉/耳挂 |
58.75% |
91.67% |
男装外套/大衣 |
29.82% |
65.45% |
| 情趣/计生用品 |
100.00% |
92.31% |
办公家具 |
58.67% |
95.24% |
卡车/货车 |
29.76% |
78.95% |
| 假发 |
95.56% |
95.00% |
面部护肤 |
58.46% |
50.63% |
男装西服/套装 |
29.37% |
80.95% |
| 婴童鞋 |
93.33% |
97.22% |
普通眼镜 |
57.83% |
78.69% |
女装裤装/牛仔裤 |
29.27% |
73.02% |
| 亲子套装 |
93.10% |
94.12% |
女装睡衣/家居服 |
57.69% |
88.71% |
工具配件 |
28.57% |
45.61% |
| 香水 |
91.11% |
84.09% |
泳衣 |
57.53% |
80.36% |
女装西服/套装 |
28.57% |
94.74% |
| 滑雪装备 |
90.63% |
95.65% |
卫浴装置/配件 |
56.25% |
91.80% |
手提包 |
28.57% |
63.49% |
| 男装袜子 |
88.89% |
66.67% |
钱包/手包/腰包 |
55.17% |
88.46% |
婴儿日用品 |
28.57% |
89.80% |
| 卡牌玩具 |
87.50% |
100.00% |
婴儿服饰 |
54.29% |
72.73% |
本册纸张 |
28.17% |
88.46% |
| 纹身 |
82.86% |
91.67% |
女鞋 |
53.85% |
71.11% |
男装睡衣/家居服 |
26.92% |
90.00% |
| 塑形/塑身衣 |
82.50% |
73.44% |
男鞋 |
53.52% |
76.74% |
其他男士运动服 |
26.89% |
71.43% |
| 墨镜 |
82.46% |
97.87% |
面部彩妆 |
52.50% |
77.08% |
男装T恤 |
25.89% |
62.86% |
| 美甲 |
80.77% |
95.74% |
项链/吊坠 |
52.33% |
75.00% |
联网设备 |
25.00% |
94.00% |
| 婴童家具 |
78.26% |
86.05% |
户外灯饰 |
51.35% |
82.35% |
女装毛衣/卫衣 |
25.00% |
54.17% |
| 腰带/腰带配件 |
77.19% |
100.00% |
办公收纳 |
51.22% |
81.82% |
专业照明 |
23.26% |
64.29% |
| 婴儿车 |
76.19% |
94.44% |
电瓶车/摩托车 |
50.94% |
78.57% |
供水/供暖配件 |
22.58% |
85.71% |
| 发饰 |
75.61% |
100.00% |
客厅家具 |
50.91% |
64.52% |
相机/单反 |
20.81% |
63.49% |
| 模型玩具 |
72.73% |
88.24% |
平板电脑 |
50.67% |
88.00% |
卫浴用品 |
20.00% |
62.50% |
| 餐厨家具 |
71.15% |
84.62% |
家用纺织品 |
50.00% |
77.78% |
其他特种车辆 |
16.67% |
100.00% |
| 游泳/潜水装备 |
71.05% |
87.23% |
室内健身器材 |
50.00% |
91.43% |
手持加工工具 |
16.67% |
76.60% |
| 女装丝袜/袜子 |
70.91% |
60.61% |
照明灯具-其他 |
50.00% |
60.00% |
其他女士运动服 |
15.25% |
60.98% |
| 彩妆工具 |
70.21% |
87.80% |
户外家具 |
49.33% |
60.00% |
女装T恤 |
14.29% |
61.36% |
| 毛绒玩具 |
68.09% |
94.74% |
耳机 |
45.57% |
88.00% |
首饰套装 |
10.00% |
81.82% |
| 运动鞋 |
68.09% |
47.62% |
电脑配件 |
45.00% |
41.07% |
DIY玩具 |
7.69% |
38.24% |
| 笔记本电脑 |
67.92% |
97.30% |
餐厨用品 |
44.19% |
53.57% |
车载安全座椅 |
0.00% |
60.00% |
| 卧室家具 |
66.13% |
85.00% |
婴童床品 |
44.07% |
91.67% |
灯具配件 |
0.00% |
25.00% |
| 文具 |
66.10% |
77.59% |
口腔护理 |
43.56% |
62.50% |
高尔夫车 |
0.00% |
60.00% |
| 投影仪 |
66.07% |
96.08% |
桌面灯 |
43.33% |
78.38% |
家电配件 |
0.00% |
22.22% |
模型可持续性保障
在模型上线后,我们需要持续关注模型的运行状况,要达到如下目标:
- 自动化监控:减少人工干预,通过机器实时检测异常。
- 长期稳定性:确保线上结果的可靠性,避免因数据更新造成偏差。
- 快速响应:发现异常时能自动告警或触发回滚机制。
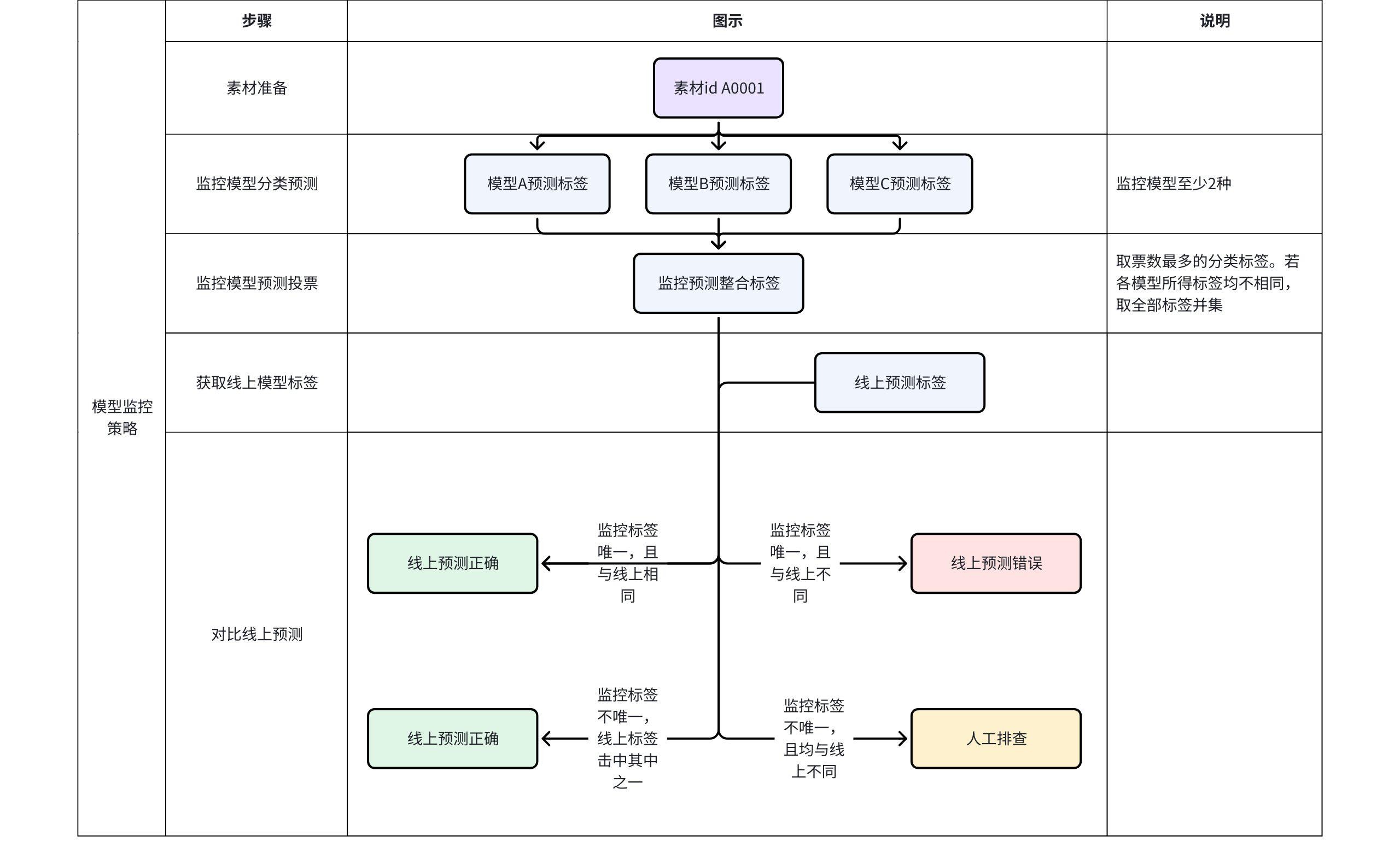
我们采用ABB(A-B-B)监控策略,通过部署一个主模型(A)和两个次模型(B1、B2)来确保分类结果的可靠性。这种策略基于模型集成的思想,通过多模型一致性检查来提高整体系统的准确性和稳定性。
| 情况名称 |
条件 |
含义描述 |
准确性级别 |
推荐行动 |
| 完全一致 |
A = B1 = B2 |
所有模型输出相同,高度可靠。 |
高 (准确性①) |
无需操作 |
| 主次部分一致 |
A = B1 ≠ B2 或 A = B2 ≠ B1 |
主模型与一个次模型一致,但另一个次模型不同;部分可靠。 |
中 (准确性②) |
可选人工审查 |
| 次一致但主不同 |
A ≠ B1 = B2 |
次模型一致,但与主模型不同;主模型可能错误。 |
低 (不准确③) |
人工排除(必须审查) |
| 完全不一致 |
A ≠ B1 ≠ B2(所有输出互异) |
所有模型输出都不同,高度不一致;主模型可能错误或数据问题。 |
低 (不准确④) |
人工排除(必须审查) |
通过以上策略,实现不同类型素材,可以调用在各自类型上表现最佳之模型,以达到强强联合的效果。
总结与展望
飞书深诺通过引入基于 Amazon Bedrock平台提供的Claude与Nova多模态生成式AI解决方案,成功实现了电商广告分类的技术升级。实验数据验证了基于生成式AI解决方案的卓越性能,准确率从传统机器学习方法的44.5%提升至85%,在1.1万条数据的验证中,90.3%的分类呈现上升趋势。特别是Amazon Nova模型在视频理解方面的出色表现,以及Claude 3.7 Sonnet在复杂推理任务上的优异能力,为项目成功提供了关键支撑。通过ABB监控策略,系统运行稳定性得到了有效保障,同时实现了降本增效的双重目标。
未来,飞书深诺将继续深化与AWS的合作,探索Amazon Bedrock平台更多前沿AI能力,进一步打造垂直行业专家模型,完善基于AWS的MLOps流程,增强多模态内容理解能力,为客户提供更高性价比、可扩展、少干预的智能内容理解中台,助力中国企业在全球市场取得更大成功。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |