亚马逊AWS官方博客
Amazon EMR on EC2 Step提交作业及和MWAA集成最佳实践
一、前言
Amazon EMR 是一个为大数据工作负载提供了全面,灵活,高度可扩展且极具备性价比的托管服务。Amazon EMR有Amazon EMR Serverless,Amazon EMR on EC2,Amazon EMR on EKS三个产品形态,他们Runtime统一,满足客户在不通场景下数据分析的工作负载。EMR on EC2托管了大数据生态最全面最流行的服务,比如: Spark、Flink、Trino、HBase、Hive、Hue等。EMR Serverless极大减轻了对于大数据作业运行的资源,日志,监控上的复杂运维工作,您只需要通过API或者控制台提交开发好的作业即可。EMR on EKS为K8S技术栈的客户提供了开箱即用的Spark,Flink运行时。本文将重点介绍EMR on EC2上使用Step API提交Spark,Flink作业的最佳实践,同时会介绍如何和亚马逊云科技的Amazon Managed Workflows for Apache Airflow(MWAA)作业流系统集成。
Amazon EMR on EC2在业务场景上可以使用两种模式。1. 瞬态集群 2.长期运行集群 两种模式都可以设置动态扩缩容,充分利用云的弹性来节省成本。瞬态集群适用于在一段时间内执行批处理作业,比如:数仓的批处理的ETL,大规模的回溯数据等场景。可以通过API直接创建集群,Step提交作业,作业运行完毕后集群自动或手动触发关闭。长期运行集群,适用于固定业务需求场景比如Flink实时计算任务,Trino的即席查询的需求等场景,需要说明的是长期运行集群可以使用EMR的弹性伸缩的能力,集群可以保留少量的计算几点,当有更多任务时,集群会自动弹性扩展。长期运行的集群我们同样可以使用Step API提交作业,无需登录到Master节点执行作业提交,也无需构建一个专门的Gateway节点做专门提交作业的节点。
本文所写的相关的内容,在亚马逊云科技中国区的北京和宁夏两个区域同样适用。
二、EMR Step实践
2.1 Step API基本说明
Step是EMR on EC2提供的向集群提交任务的API(可以使用AWS CLI,Python Boto3 API等)。我们往集群提交作业,一般有三种方式 1. Master节点或在Gateway节点提交作业,比如在节点直接运行spark-submit,flink run等命令。2. 通过开源的工具管理提交作业比如管理Flink作业的Dinky,具体可以参看这里使用 Dinky 进行 Flink 任务开发管理,可视化的调度管理DolphinScheduler基于开源工具构建EMR数据分析平台。3. 通过MWAA管理提交作业或者使用Step API直接提交作业,MWAA提供了原生和EMR Step集成的Operator。除此之外部分客户会开发构建自己的作业提交管理平台,这个不在本文讨论的范围。
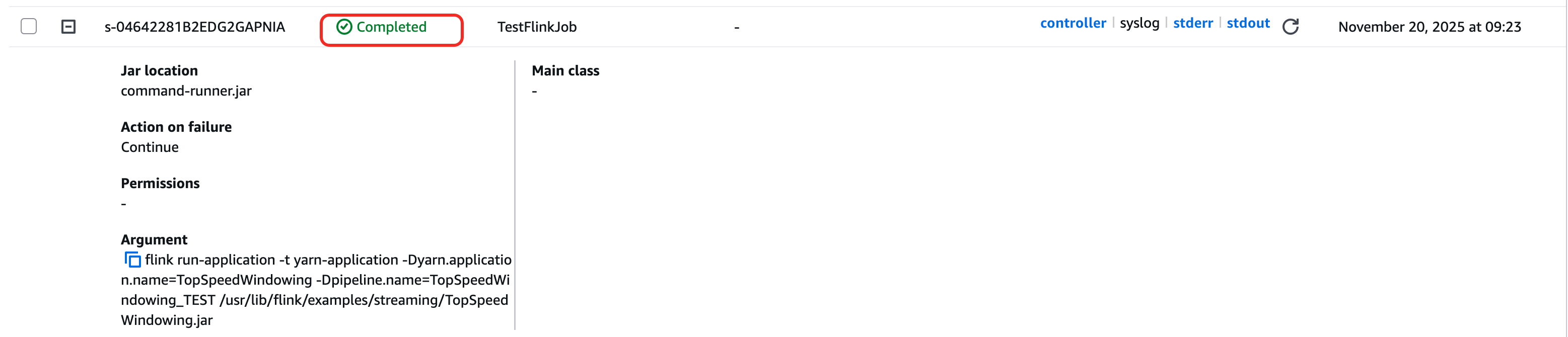
下面是是一个通过AWS CLI提交Flink作业的例子,我们从参数中可以看到EMR Step作业其实和我们正常运行Flink命令没有区别,只是这个命令通过Step提交时,在EMR上会通过JAVA执行一个common-runner.jar的程序,这个程序在Master节点中运行,会调用EMR Master节点本地的Flink命令,当这个命令成功执行完成,EMR Step本身的状态会变成Completed。
这里要重点说明的是Step本身状态是不能反应Flink作业本身的执行状态的。Step的状态是common-runner.jar这个程序调用的本地命令的执行状态。比如下面flink run-application 的命令已经成功执行,且对于flink run-application模式,Flink的机制是只要作业成功提交到yarn上,在yarn上分配到jobmanager的container,这命令就执行完了,对于common-runner.jar这个程序而言命令执行完成,退出状态码为0,成功支持完毕。所以Step的本身的状态就是完成状态。 假如你不是使用的flink run-application模式,而是使用flink per job模型提交作业,Flink的默认模式是attached mode,也就是作业提交到yarn上如果不加-d参数,客户端不会退出,会跟踪作业状态。这种模式下,对于Step而言,因为进程不退出,所以Step会是Running的状态,知道Flink作业完成或者失败。但这种模式有一个非常值得注意的问题,如果客户端进程不退出,就意味着有每个作业有两个JVM进程占用Master节点内容,如果并发的作业很多,Master内存会被占满,会有把Master节点压挂的风险。后边章节会讨论提交作业的最佳实践。
 |
 |
2.2 Step提交Spark作业最佳实践
在上边章节已经介绍过Step基本的运行原理。对于Spark作业而言,提交到YARN上之后,客户端进程是否退出是通过Spark提供的参数spark.yarn.submit.waitAppCompletion=true 这个参数的默认值是true,也就是会客户端不会退出,会跟踪yarn application的状态,这种情况下Step本身的状态是Running状态,直到spark客户端进程执行结束,如果spark作业执行失败,Step状态就是FAILED,如果支持成功就是Completed. 但问题如之前提到的一样,客户端进程不退出,就会占用Master节点内存,如果同时有多个作业运行很可能把Master节点打挂。而如果设置.waitAppCompletion为false,此时Step只要执行完提交命令,spark-submit命令正常执行结束,进程就会退出,step状态直接进入Completed状态,此时Spark作业依然在运行或者中间运行失败,无法从Step状态判断Spark作业状态。
因此对于Step提交Spark作业,我们根据场景可以选择使用不同的方式。如果我们Spark作业并发不多,同时想要直接通过Step API 获取作业真实的运行的状态,可以使用spark.yarn.submit.waitAppCompletion=true模式,但要注意Master节点的内容占用。 一般而言,对于一个作业而言,spark-submit客户端进程和strep common-runner.jar进程每个会占用700MB左右的内存,我们可以按照一个作业需要2GB的Master内存要计算,如果有10个作业同时运行,Master节点就需要至少20GB内存,另外要注意,Master节点上还有你安装的其它应用的内容占用,这里的10GB,只是针对10个并行的Step作业需要额外的10GB占用。另外如果我们的作业是临时作业,比如数据回溯,完全可以用API新创建集群,Master节点内容调大,作业运行完集群就关闭,而不使用当前集群,避免对当前集群造成影响。
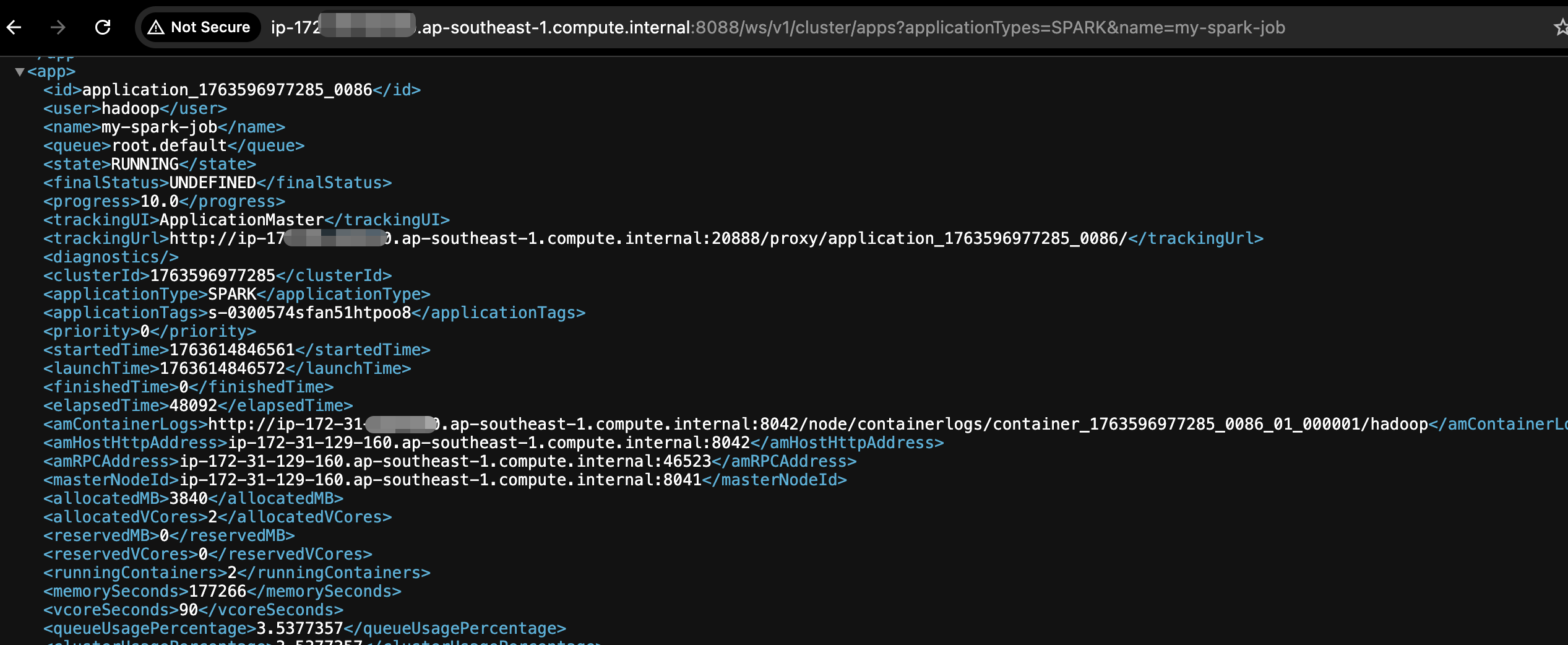
如果我们作业并发比较多,我们可以设置spark.yarn.submit.waitAppCompletion=false,此时作业的真正的执行状态就要通过YARN Rest API来获取了。 通过http://master_ip:8088/ws/v1/cluster/apps?applicationTypes=SPARK&name=my-spark-job获取Spark作业状态, 如果你能确保你的spark作业名字是唯一的,通过rest api找到指定作业名字的状态就可以。如果你不能保证作业名字唯一,指定名字会把所有相同名字的都查到。 这时可以使用唯一的application id获取作业状态,通过rest api指定application id, http://master_ip:8088/ws/v1/cluster/apps/application_id 。如何通过Step提交的作业找到对应的application id。在下面和MWAA集成的章节会说明。这里简单来说就是通过API请求Step提交的输出日志找到对应的Application id。
 |
2.3 Step提交Flink作业最佳实践
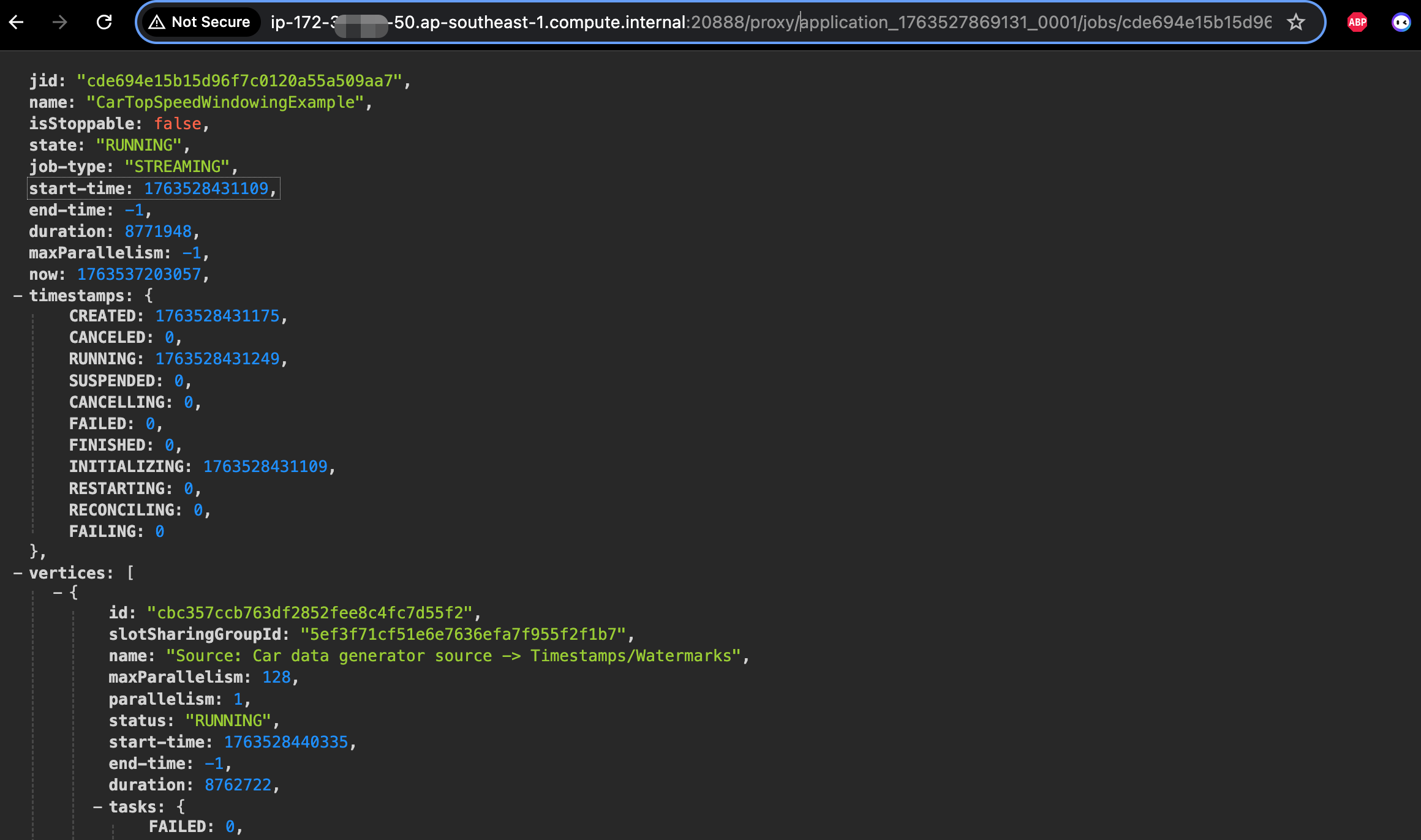
对于Flink作业而言,官方推荐的Flink提交的方式就是Application模式了,在Application模式下是没有attached模式的也就是设置execution.attached=true是不生效的。step提交之后,只要flink作业正常提交到yarn上有了driver container这个进程就退出了,step状态就是完成状态。 因此对于Flink作业的真实状态,通过yarn rest api获取到的作业才是正确的,也是推荐的方式。同时我们可以获取到flink rest api的所有作业的监控指标。flink job 指标通过yarn代理过去的flink restapi 获取http://application_master_id:20888/proxy/application_id/jobs/job_id 这里的application_master_id 通过yarn的rest api可以获取到ApplicationMaster地址。
 |
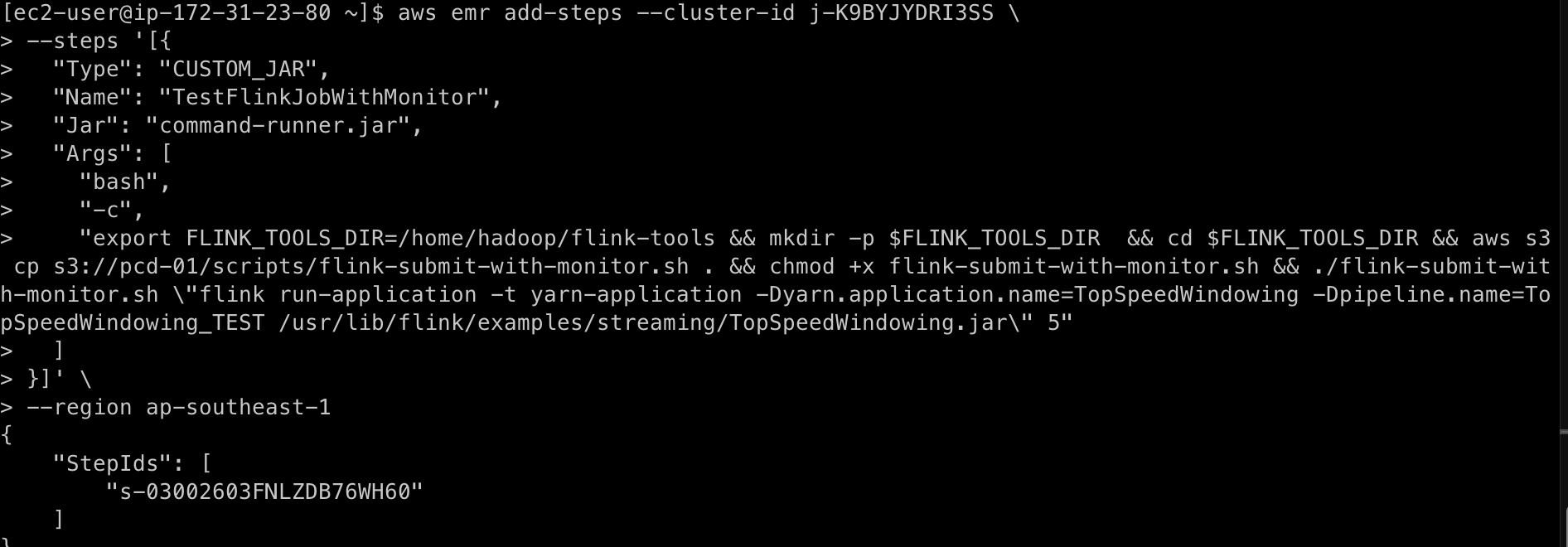
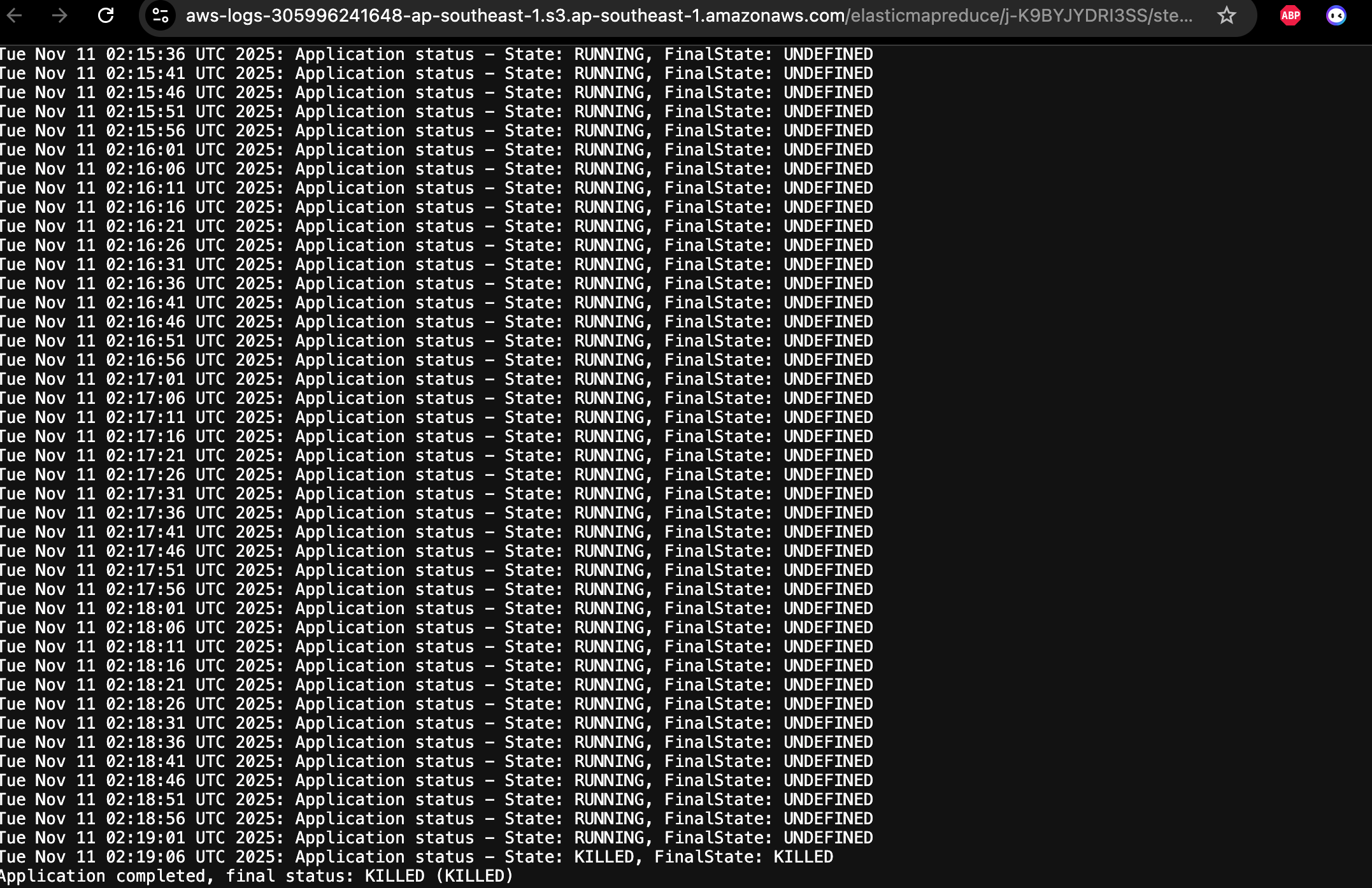
如果你确实需要通过step api获取作业的状态,你可以定制一个step提交作业的脚本。用这个脚本提交作业即可,下面是一个参考例子,但这种方式common-runner.jar进程需要占用Master节点内存,可以按照每个作业1GB计算,实际使用在500~700MBz左右,并行任务较多时,请注意设定Master节点内存。这个脚本的核心逻辑是提交执行作业后,周期循环请求yarn rest api获取作业状态。只有common-runner.jar这个进程会占用内存。
使用step提交作业,使用我们定制的脚本
- 提交作业
 |
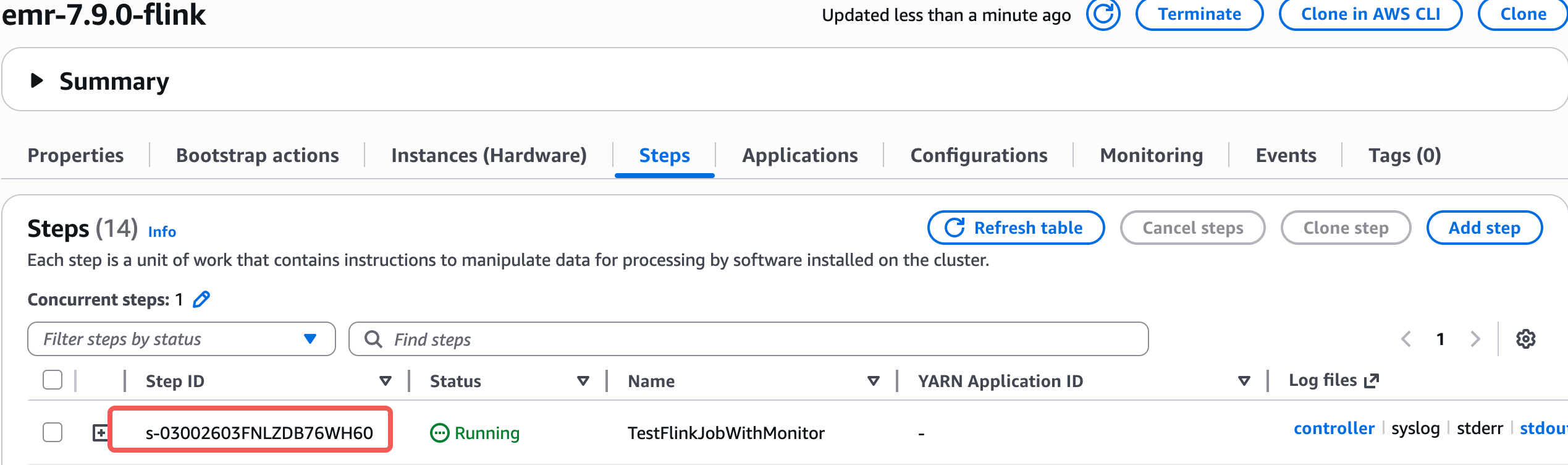 |
- kill掉作业后查看状态
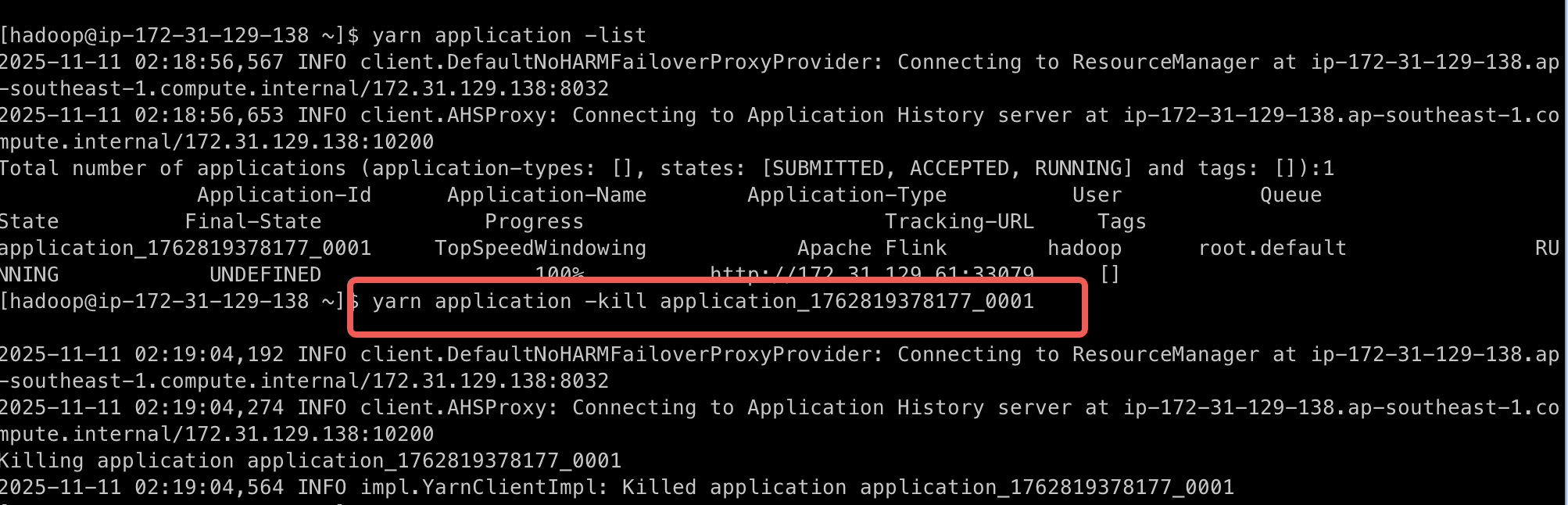 |
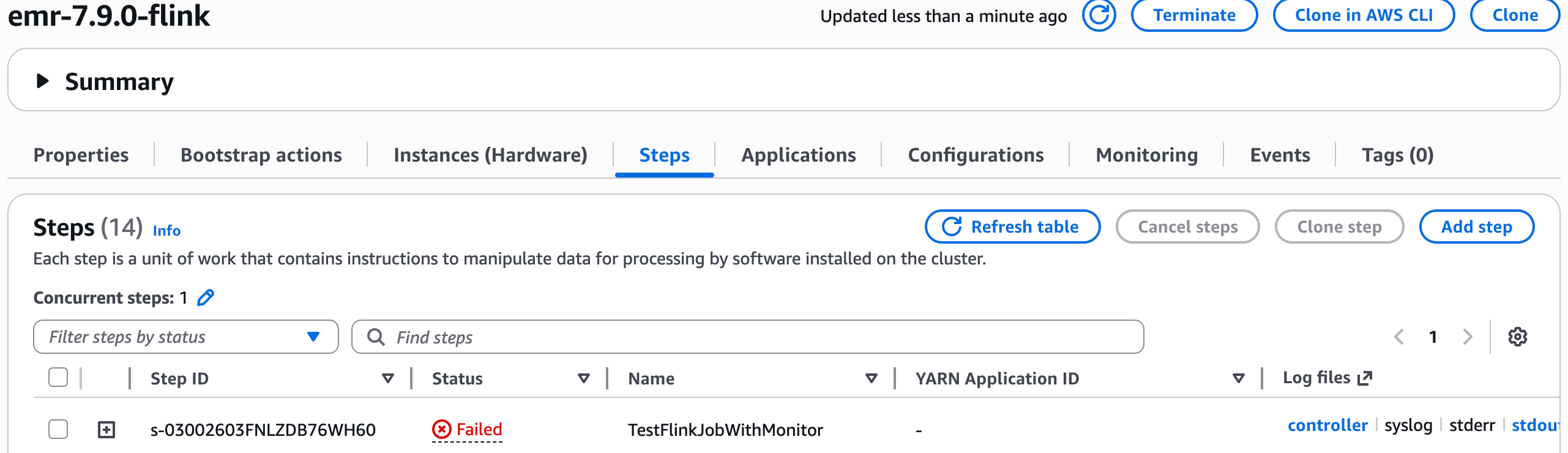 |
- 也可以看到相关作业日志
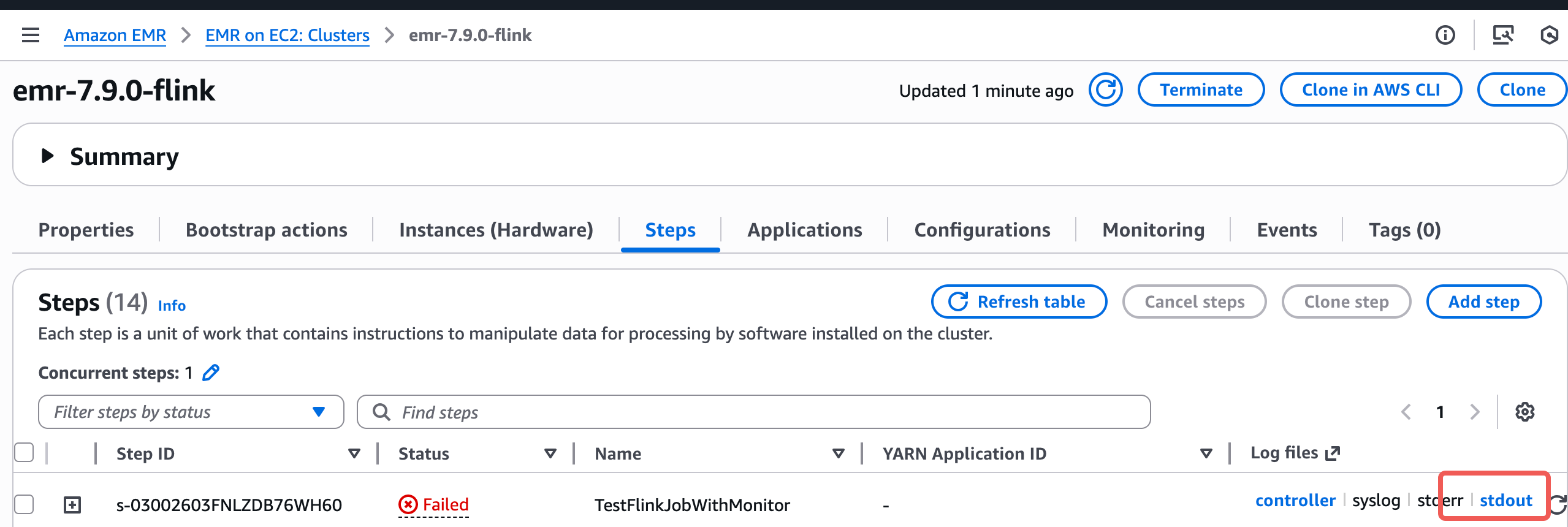 |
 |
三、EMR Step和MWAA集成
3.1 集成说明
MWAA本身已经提供EMR on EC2创建集群,提交Step作业等相关的Operator,Operator封装的就是EMR Step API。默认情况下如果提交Spark作业就是阻塞的,会等待客户端运行结束。如果您通过MWAA同时调度多个作业,尤其是在数据回溯的场景下,很可能会将Master节点打挂。 有三个建议,第一是数据回溯时直接通过MWAA创建新集群,MASTER设定大一些,满足咱们并发需求。 第二,EMR Step是可以控制并行度的,默认的并行度是1,也就同时只有一个作业能提交运行,这个作业的Step状态如果处理Running状态,其它通过Step提交的作业都会是在Pending状态,Pending状态的作业并不会在Master节点上有任何进程。我们可以按照需求设定Step的并发,Step最大并发是256. 第三,自定义一个MWAA提交作业的方法,设定`spark.yarn.submit.waitAppCompletion=false循环等待通过rest api获取作业状态,跟上文讲解的方式一致。这种模式也要注意step的并发,因为作业提交到yarn上需要时间通常1分钟内,如果一次性运行100个作业,可能瞬时的内存占用会很高,可以限定一下并发,但这个并发限定,基本不会影响真实作业的并行,因为提交之后step就完成了,马上就会调度下一个step.
3.2 代码实践
- 如下是一个带监控的DAG文件,注意下面dag中,monitor_emr_wrapper中的集群id和region 替换为你的region即可
- 这个dag中引入监控的python包
emr_ec2_job_status_analyzer,使用如下代码,保存为emr_ec2_job_status_analyzer.py,放到和dag同一目录下即可。
3.3 重要说明和运行结果
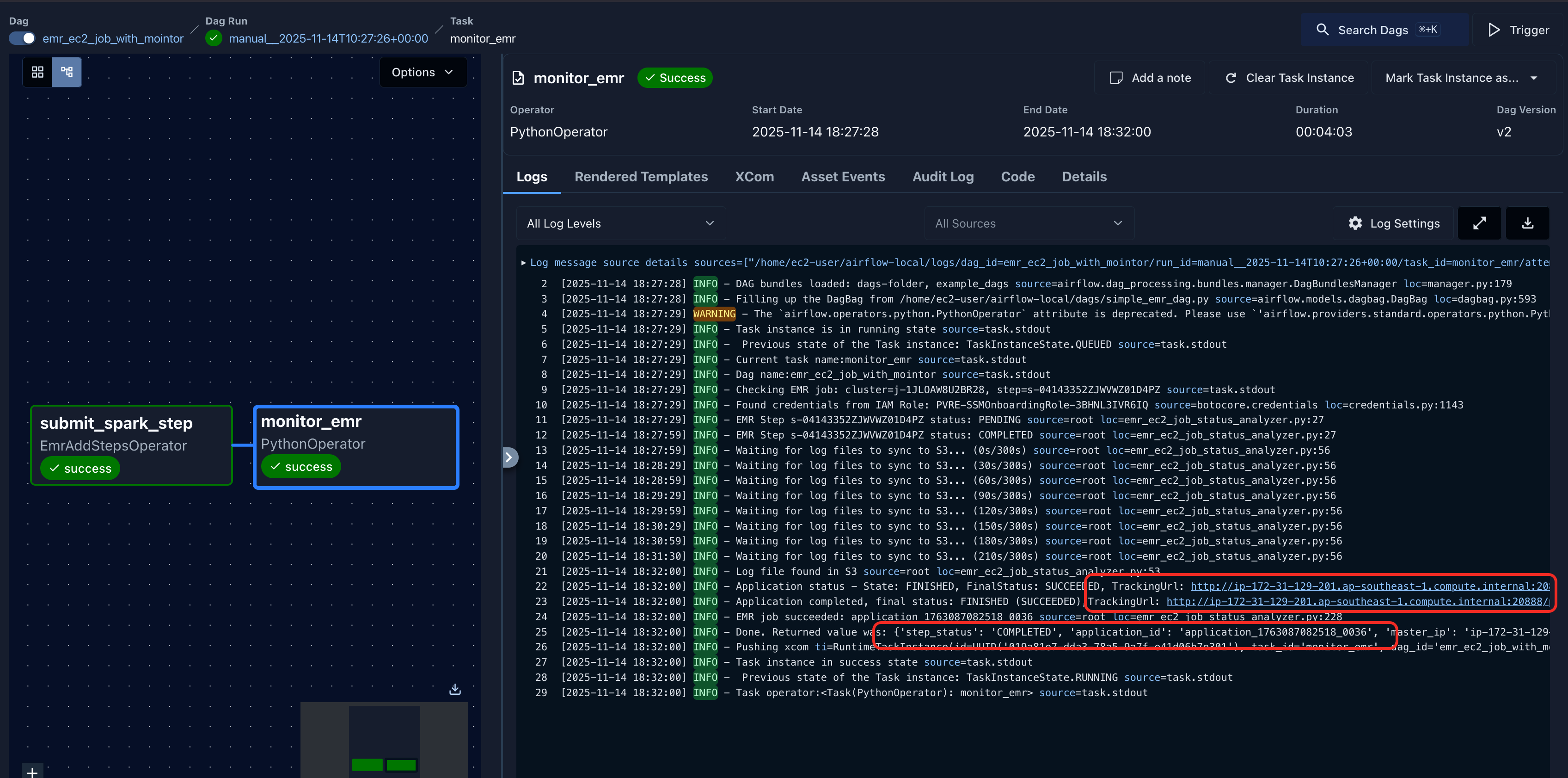
- 对当前DAG的运行流程做个说明
1. emr step提交spark作业后,获取到step id
2. step如果是完成状态, 根据step id去s3上找step的日志,从日志里面找application id,因为step日志同步到S3需要时间,一般作业提交后1到2分钟,最大应该在5分钟左右。代码里面设置了10分钟的默认日志检查时间,可以修改设置。这一步从日志获取application id和前文说明一样,如果能够保证每个作业的名字都唯一,可以不通过日志获取application id, 而是直接通过yarn rest api根据作业名字查找状态。
3. 获取到application id后,请求EMR api获取到master ip, 然后就可以请求yarn rest api 获取到这个applicaiton的状态
4. 根据application的真正状态,来判断这个task是否完成,如果完成task 成功,否则失败。
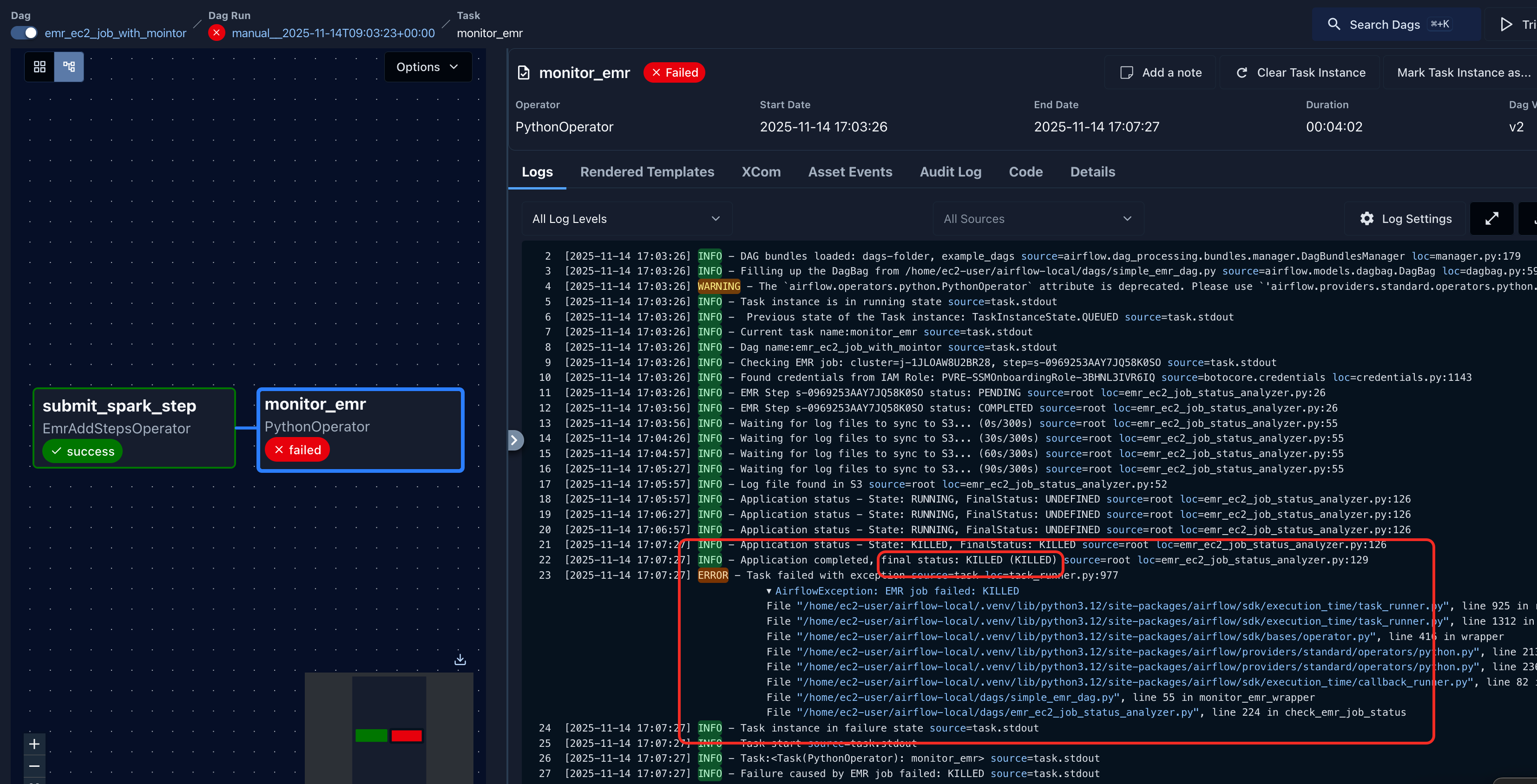
- EMR 作业通过airflow提交之后,因为是cluster模式运行,在airflow上点击取消task,是无法真正取消作业的,这点要理解。
- 在日志中可以点击Tracking URL跳转到这个作业的YARN WEB UI,查看作业详细信息
 |
 |
四、Static BGP(S-BGP)
截止到这里我们已经讲解完了相关EMR Step使用的最佳实践,上述方案在中国区同样适应。最后为我们亚马逊云科技推出的Static BGP(S-BGP)服务打个广告,他是专为中国区域(北京和宁夏)设计的一种成本优化型数据传输服务。通过这项服务,我们致力于帮助客户在保证网络性能的同时显著降低数据传输成本。 S-BGP 可为符合条件的客户提供高达20%~70%的数据传输费用节省。详细的内容可以点击这里
五、总结
本文详细介绍了Amazon EMR on EC2上使用Step提交Spark、Flink作业的最佳实践,以及如何与MWAA做集成。我们需要了解的是Step提交左右有同步执行和异步执行两个模式,对应客户端命令在提交作业后是否继续跟踪作业状态。Step的并发设定在同步模式下能够很好的控制Master资源使用,异步模式下能够降低瞬时对Master资源的消耗。MWAA和EMR有原生的集成,开源的Airflow也同样提供EMR集成的Operator,我们可以根据咱们业务的场景灵活的选择EMR Step的使用方式。最后亚马逊云科技中国区Static BGP(S-BGP)是帮助您节省数据传输成本的利器。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
