亚马逊AWS官方博客
AMD Yes! EC2 实例的新选择
今年6月4日那天我读到了同事Channy Yun的一篇博客“New – Amazon EC2 C5a Instances Powered By 2nd Gen AMD EPYC™ Processors”。这一下子勾起了我的兴趣,因为我看到了一个久违的字样 – “AMD 处理器”。记得最早使用AMD的处理器还是在1998年,那时候我从Tom’s Hardware 学到了一个小技巧,用铜丝将华硕T2P4主板CPU插座上的两个针脚短路,这样就可以完美的支持AMD 的K6处理器。对比价格高高在上的Intel Pentium II处理器,支持MMX 指令完美软解VCD的AMD K6 处理器无疑是“真香”了!不过此后的日子里,我几乎再没有在使用过AMD的处理器,直到我看到了这篇博客。
 |
 |
Intel和AMD的恩仇录
熟悉芯片发展史的人都应该听说过Intel 与AMD 近半个世纪的爱恨情仇的故事,而且这段故事也贯穿了CPU发展的全部历程。说起来,Intel 与AMD 都是“仙童的子孙”,两家公司的创始人都是出自仙童公司,正所谓同根同源更容易演绎相爱相杀。
1980年Intel发布了划时代的 8008 处理器,开启了PC的时代。更重要的是其处理器的指令技术,正是这套指令集奠定了今天 x86 系列微处理器指令集的基础。1982年,由于Intel 产能出现问题,于是授权 AMD 生产 8086 和 8088 处理器,由此AMD 开始涉足x86 处理器市场。在286、386的时代,AMD顽强的通过低价的策略占据了部分市场。而随着Intel Pentium 处理器的出现,Intel 终于成为与IBM、Sun、HP、DEL等比肩的处理器霸主。
在上个世纪90年代后半期,AMD在 Socket7 架构上推出了上面提到的大受欢迎的K6处理器,并且先于 Intel 提出了 100MHz 外频的处理器产品,性能表现非常优异。1999 年 AMD 抢先发布了 1 GHz 的处理器,进一步提升了竞争力。同一时期,Intel 也发布了多款 Pentium III,并向 Pentium 4 过渡。AMD 也不甘人后,发布 Athlon、 Athlon XP 等多款K7 系列的产品。这个阶段双方的产品你方唱罢我登场,在性能上交替提升是竞争最为激烈 的一段时期。AMD的产品具有性价比高的特点,帮助他们积累了大量的用户,尤其是价格敏感的DIYer用户。这场竞赛的一个高潮出现在了2003年,AMD在那一年发布了 K8 的 Athlon 64处理器,在历史上首次领先于他的老对手。
值得一提的还有现在广范使用的x86-64技术,有时也称做x64、AMD64或者Intel 64。这是x86 架构迈入64位的一次里程碑式的进步。这个架构不仅提供了64位的指令集,而且向后兼容16位、32位的x86 架构。而x86-64这个技术就是由AMD 设计并首先应用于Athlon 64 处理器。而在此之前,Intel 与HP一起推出了IA-64 架构。但由于其另起炉灶不与x86指令兼容,惨淡经营了数年之后,Intel 于2017年不得不终止了这个技术。X86-64 代表了AMD放弃了此前一直采用的跟随的策略,选择了务实的与x86兼容的64位的架构策略,突破了32位架构上存在了4GB内存的访问限制,一举奠定了今天x86-64在服务器市场上的成功。可以说,这些技术进步与商业上的成功 ,让AMD 一时风光无两。

不过,从2006年开始,Intel 采用了饱受争议的“Tick-Tock” 战略。所谓的Tick-Tock 指的是一年架构、一年工艺交替提升的策略。也是因为这个挤牙膏式做法,让Intel 获得了“牙膏厂”的绰号。正是在这一年Intel 采用了了 65nm 工艺的Core 2 处理器发布了。新的处理器效能增 长 40%,同时功耗减少 40%。这让 AMD 的 Athlon 好不容易取得的优势荡然无存。市场竞争的格局开始倾向Intel,并持续了十余年。雪上加霜的是,AMD于2006 年以花费54 亿美元收购显卡厂商 ATI,但是 CPU 和显卡市场上的双双失利得 AMD 在 2007 年开始进入低迷。也正是AMD这一时期的低迷,让他得到了Agriculture Machine Developers(AMD)的名号,由此“农企”的名字就在业内广为流传了。
2011 年,AMD剑走偏锋 推出了新的Bulldozer(推土机)架构。特点就是CPU的核显部分异常强大,试图通过差异化来进行竞争。自此,AMD 将技术重点放在 GPU,强调异构运算,从此与 Intel 走上截然不同的道 路。在服务器市场上AMD从此彻底的消失。相比之下从2009年开始,延续Tick-Tock 战略Intel 陆续发表了一系列新的架构 –
• 2011年,Sandy Bridge 架构,采用了32nm工艺
• 2012年,Ivy Bridge架构,工艺为 22nm
• 2013年,Haswell 架构,工艺为22nm 至 14 nm
• 2014 年,Broadwell 架构,工艺为14nm
• 2015年,Skylake 架构,采用14nm工艺
• 2016 年,Kaby Lake 架构,工艺为14nm
• 2017 年,Coffee Lake 架构,工艺为第二代14nm
• 2018 年,Cannon Lake 架构,工艺为14nm
在这一时期,由于市场策略的巨大成功,Intel 处理器在桌面市场的份额超过了80%,而在服务器市场更是几乎达到了100%的占有率。我们使用过的许多EC2实例例如C3、C4、C5等等都是采用了这一时期Intel 的处理器。

之后的故事又一次出现了戏剧化的反转。Intel 预计在2019 年发布Ice Lake 架构,这是第十代Intel 酷睿处理器,计划采用第二代10nm工艺制造。但由于10nm工艺出现的问题,Intel被迫在2019年发布了Comet Lake、 Cascade Lake架构,但在工艺上依然是千年不变的14nm。而这恰好给了AMD翻身的机会。在2018年底的发布会上,AMD 的CEO苏姿丰(Lisa Su)发布了全球首款7纳米数据中心处理器。对AMD来说,7nm数据中心处理器是一次突破,成为AMD在历史上首次超越英特尔,在处理器工艺上占据了领先地位。与此同时,2018年11月6日AWS宣布了采用新一代的m5a、r5a实例,宣布采用了2.5 GHz 的AMD EPYC处理器,价格比同类实例,也就是采用Intel 的实例,价格足足低了10%!
自AMD 的Zen架构发布以来,AMD在PC处理器市场的份额就不断攀升。除了AMD的Zen架构的出色的设计之外,还要归功于芯片代工厂在工艺制程方面超越Intel的因素有关。AMD处理器的代工厂台积电在2018年投产了7nm工艺,于是新一代的AMD处理器立刻全面采用了7nm工艺生产。2019年8月,AMD又适时的推出了针对服务器市场的EPYC 处理器。针对服务器市场,这一代的产品具有更高的核心数、更多的PCI Express通道、支持更大数量的RAM和更大的缓存。毫无意外,此后AWS陆续发布了采用AMD EPYC 处理器的m5a、r5a 、t3a与c5a等实例。回顾这一过程,自2017年AMD 发布Ryzen 处理器以来,通过Zen架构的迭代以及7nm工艺的加持,AMD 不仅在处理器单核的性能上直追Intel 并且在整体性能的测试上也不落下风,更重要的是其性价比要超过了他的老对手一头。到这个时候,这场处理器市场的恩仇录也终于迎来了新的高潮,当然后面的故事也许还要更精彩。就让我们拭目以待吧。

处理器的7纳米(nm)工艺为何如此重要?
首先,我们需要搞清楚“纳米”究竟是什么。纳米(nm)又称毫微米是长度的度量单位。具体地说,一纳米等于十亿分之一米的长度。更形象一点就是万分之一头发粗细的大小。我们所使用的计算机芯片中可以装载几十亿个晶体管,这就得益于先进的制程工艺。制程工艺越高级,晶体管的尺寸就越小,同样的芯片体积里,就能装下更多的晶体管。学习过计算机原理的人都会了解,晶体管是芯片运算的最小单元,晶体管的数量越多,芯片的运算能力就越强。并且晶体管越小,驱动它开关的能量就越低,所以耗电量就小,发热量就会低。可以说,芯片性能的提升、晶体管数量的增加、功耗/发热降低都依赖半导体工艺的提高。如此看来,我们只要逐步缩小晶体管的体积就好了,从22nm 、14nm、10nm、5nm…. 这不是自然而然的事情吗?

但是,半导体工艺在从14nm进入10nm制程的时候,就遭遇遇到了严峻的挑战。物理学的常识告诉我们,任何物理材料都存在物理极限。而当半导体制程越来越小的时候,芯片中就会出现了量子效应。表现就是晶体管作为0和1的电路开关,就会变得不稳定,随机性的结果导致芯片无法使用。而工艺达到10nm,这种效应就会显现,这就为芯片厂商的设计和制造带来了巨大的难度。这也就是为什么Intel 从Haswell 架构到Cascade Lake 架构的工艺制程始终停留在14nm 的原因。解决问题的思路有人寄希望在材料科学的进步。我们知道,传统的半导体产业是靠铜作为基础导电材料的,但是当工艺达到10nm之后,铜就会出现导电率不足的问题,“电阻-电容延迟时间”严重减低了半导体元件的速度。于是Intel就试图通过引入一种新的材料“钴(Co)”来解决这个问题。并且Intel早在2013年就已经投入“钴”材料的开发。
但是现实总是无情的,所谓的成功者不一定是那个勇于进取的一方。这一次胜利女神青睐的是相对保守的一方。激进的Intel 在新材料上遇到了重重阻力,而相对保守的台积电却在铜合金的方案上取得了成功,并与2017年年中推出实验产品,随后于2018年第二季度首先量产第一代7nm芯片。于是我们今天广泛使用的例如Apple 手机中的A12、A13处理器、安卓手机中的高通的Snapdragon 855 以及我们提到的AMD 的处理器等等都成为了这个工艺进步的受益者。顺便提一句,在上一篇博客“云上ARM实例应用优化之我见”文中提到的AWS Graviton 2 处理器也是采用的台积电7nm工艺。台积电过去3年在制程工艺上一路狂飙,今天的台积电更是凭借着在5 nm上的绝对优势冲刺至全球市值前十的公司榜单之上。相较之下,Intel在10 nm上连续受挫,而在最新的报道中,7nm工艺良率更是低于预期导致相关芯片上市至少会推迟到2022年。
从理性上,我们知道“摩尔定律”的失效只是早晚的问题。但从感性上,我们还是希望这一天晚一点到来吧。

2016 年-2020年, Intel vs AMD 股价走势对比
采用 AMD EPYC处理器 的EC2 实例
AWS 云计算的用户总是在努力寻找应用程序性能和成本之间的平衡点。对于EC2这个云计算服务而言,我们经常面临这样两个挑战:
- 有限的选择
工作负载具有不同的特性和对于云计算基础设施不同的需求。有限的选择意味着用户可能无法正确调整工作负载的大小以优化性能和成本。 - 资源的闲置
在给定的服务器或EC2实例上,许多工作负载只使用处理器最大性能的一小部分。因此用户可能没有充分利用他们所拥有的资源。
对于EC2 使用上的优化,最为推荐的简单且有效的建议就是 “选择最适合的实例类型”。 采用AMD EPYC处理器的EC2实例,无疑将为众多的AWS用户提供更多的选择。这些实例允许用户调整工作负载的大小,同时提供了比可比实例低10%的成本。相信这将为工作负载的成本和性能的优化提供简单而直接的手段。
截止到目前,采用AMD 处理器的EC2 实例类型包括了可用于计算密集型的C5a、通用型的M5a、M5ad,内存优化的R5a、R5ad和可突增的通用实例T3a。
- 计算优化型C5a实例
C5a实例采用第二代 AMD EPYC 7002 系列处理器,运行频率高达 3.3GHz,最多支持96个VCPU (带有SMT的48个物理内核) ,可用于运行批处理、分布式分析、Web应用程序和其他计算密集型工作负载。
- 内存优化型R5a实例
采用AMD EPYC 7000 系列处理器,全内核睿频时钟速度达 2.5GHz,内存最多可达768Gib,可有效支持高性能数据库、分布式Web大规模缓存、中型内存数据库、实时大数据分析和其他企业应用程序。
- 通用负载型M5a实例
采用AMD EPYC 7000 系列处理器,全内核睿频时钟速度达 2.5GHz,提供计算、内存和联网资源三方面的平衡,适用于业务关键型应用程序服务器、企业应用程序的后端服务器、游戏服务器、缓存服务以及和应用程序开发环境。

- 通用负载型T3a实例
采用了AMD EPYC 7000 系列处理器,全内核睿频时钟速度达 2.5GHz,提供基本水准的 CPU 性能,并且能够在需要的情况下随时突增 CPU 使用率。可用于微服务、低延迟交互应用程序、中小型数据库、虚拟桌面、开发环境、代码存储库和业务关键型应用程序等场景。




采用 AMD EPYC处理器 的EC2 实例的性能表现
基于 AMD 的 EC2 实例于 2018 年 11 月首次推出,目前已经已扩展到 6 个实例系列(C5a、M5a、M5ad、R5a、R5ad 和 T3a),跨越超过 15 个AWS全球区域客户带来了高性能、高性价比的超强选择。借助AMD EPYC处理器的高核心数量带来的优势,为用户带来了“Amazon EC2产品组合中每x86虚拟CPU最低的成本”。尤其是最新发布的C5a 实例,由于采用了第二代AMD EPYC 处理器,在性能上有了巨大的提升。我们这里提到的第二代EPYC处理器的架构是升级而来的Zen 2。在性能方面的改进包括了这些方面:
- 改进了执行管线
- 浮点和Load/Store性能翻倍
- 处理器核心密度翻倍
- 单次运算能耗减半
同时还有安全上的加强。原本Zen架构就不受Intel架构专属漏洞Meltdown等的影响,在安全考虑上要强那么一点。新的Zen2架构则更进一步,在硬件上加强了Spectre漏洞的修复。有兴趣这个话题,可以参考我之前的博客“悬在云计算头上的达摩克利斯之剑 – 对于Meltdown 、Spectre事件的进展与思考”。还要强调的一点,这是首个支持PCIe 4.0的x86服务器CPU,PCIe 4.0带来64GB/s的双向带宽,相比PCIe 3.0提升了一倍,对于PCI设备的性能发挥起到了重要的作用。

采用第一代EPYC处理器的m5ad.4xlarge 实例

采用第二代EPY处理器的c5a.4xlarge 实例
在今年的7月4日,知名的开源基准测试套件Phoronix 在它的网站上发表了一篇性能测试的报告。在这个测试中,选择了第二代AMD EYPC处理器(7R32)的 c5a.16xlarge 、Intel Xeon Platinum 8175M处理器的m5.16xlarge、第一代AMD EYPC处理器(7571)的m5a.16xlarge等实例进行了测试比较。操作系统方面统一使用了Amazon Linux 2作为所有基准测试的环境。
1、 Linux 内核编译测试 (测试数字越小越好)
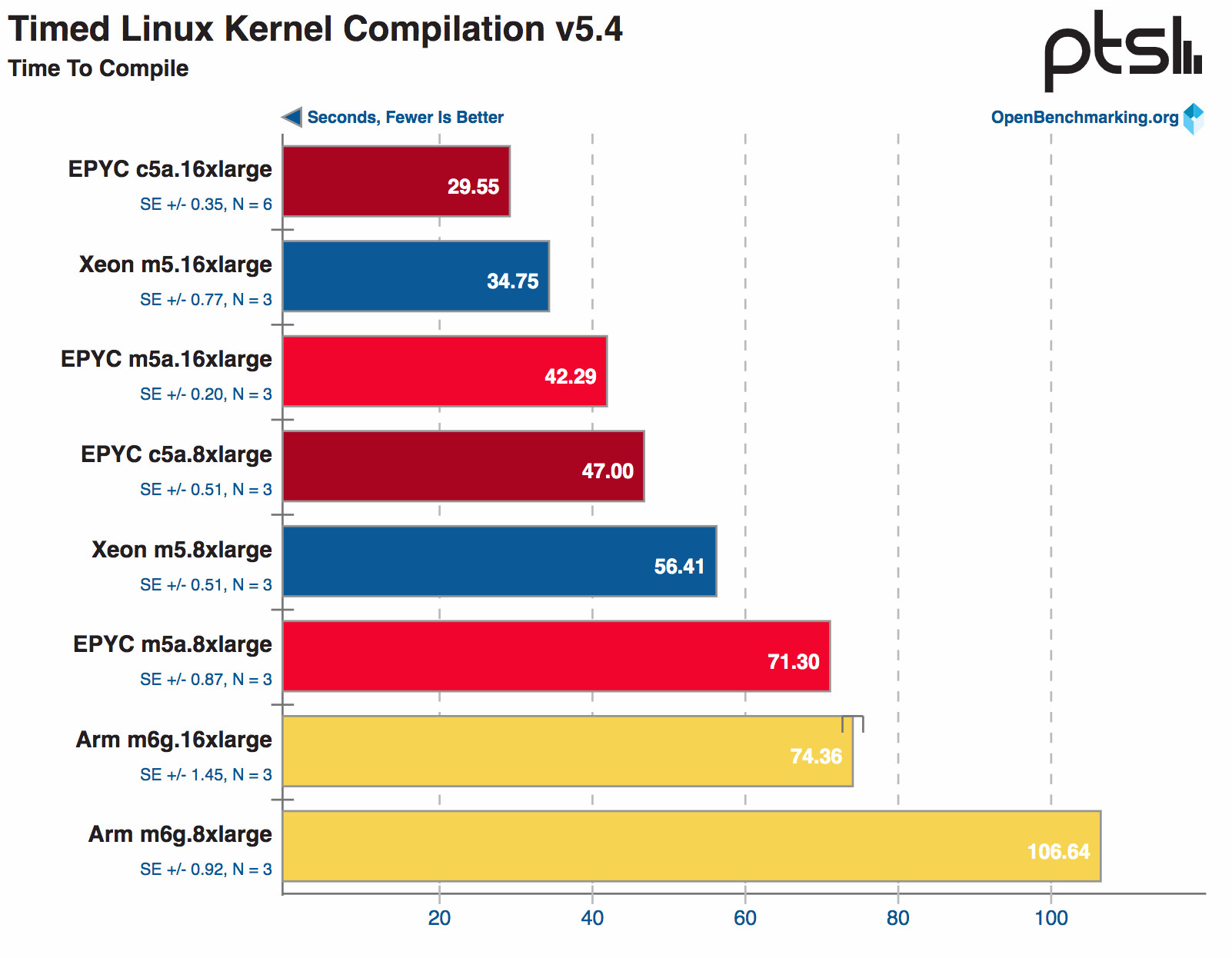
很明显,c5a.16xlarge 与c5a.8xlarge 表现的最为出色。需要说明的一点,在为x86_64构建Linux内核和为ARMv8构建Linux内核之间启用了不同的模块/选项,这就是m6g 稍微逊色的原因。
2、 PostgreSQL pgbench v12.0 测试(测试数字越大越好)

与PostgreSQL数据库的pgbench测试的项目中,采用了Intel Xeon处理器的m5.16xlarge 成绩最好,但是 c5a.16xlarge 实例落后不多。在内核数、线程数相同的情况下, c5a实例比采用上一代EPYC实例m5a提升很大。
3、 Redis v5.0.5 测试(测试数字越大越好)

众所周知Redis采用的是单线程模型,因此这个测试比拼的就是处理器的单线程性能。从结果来看,Intel 的Xeon 在单线程的性能方面稍有领先,但值得注意的是EPYC从第一代到第二代在单线程性能上的显著提升。
通过测试的结果我们能够发现,采用了最新EYPC 处理器的c5a.16xlarge实例的性能比上一代产品提高了40%,比Intel Xeon M5 Cascade Lake实例的性能高出5%。 如果我们考虑到之前提到了成本方面具有的10% 的优势,相信诸位应该会有一个清晰的判断了。
关于这个测试的细节还有很多,有兴趣的可以通过这个链接了解一下,“Benchmarks Of 2nd Gen AMD EPYC On Amazon EC2 Against Intel Xeon, Graviton2”
性能优化的一点建议
- GCC 8.2 以后通过 -march=znver1 支持AMD EPYC 7xx1 处理器。
- GCC 9.2 与GCC 10 增加了 -march= Znver2成提供了第二代EPYC 处理器的支持。如果仅仅针对本机优化,-march=native 也足以满足通常所需的优化。
- LLVM 9.0是第一个提供Znver2目标支持的LLVM版本。
- 随着第二代EPYC处理器的发布,AMD也发布了Linux 平台的优化编译器AMD Optimizing C/C++ Compiler(AOCC) ,这是基于LLVM / Clang的针对AMD处理器处理器而优化的编译工具。 与LLVM中相比,还进行了其他各种优化和改进。目前这个工具的版本是2.2,基于LLVM 10.0,下载工具的地址是https://developer.amd.com/amd-aocc/。对于需要针对C/C++ 以及Fortran 代码进行深度优化,这将是个不错的选择。其定位应与Intel C++ Compiler相类似。
最后还要说一句关于AVX-512 指令集的问题。AVX-512是Intel于2013年7月提出的针对x86指令集体系结构的256位高级矢量扩展SIMD指令的512位扩展。AVX-512 指令集其指令宽度扩展为 512bit,每个时钟周期内可打包 32 次双精度或 64 次单精度浮点运算,因此在图像 / 音视频处理、数据分析、科学计算、数据加密和压缩和深度学习等应用场景中,会带来更强大的性能表现,理论上可以使浮点性能翻倍,整数计算则增加约 33% 的性能。很不幸的是,目前只有Intel 的处理器支持这个指令集。而AMD的处理器仅仅支持AVX2 指令集。这就意味着,在特殊的工作负载下例如需要AVX-512 指令的支持,采用Intel 的处理器的EC2实例就是我们唯一的选择。
有意思的是,Linux Kernel 的创建者Linus Torvalds不久前在一封邮件中发表了这样一段言论 –
“我希望 AVX512 去死,然后英特尔就可以开始去解决实际问题了——而不是试图去创造神奇的指令,然后围绕它寻找基准测试结果让它看起来很好。…
AVX512 有很明显的缺点。我宁愿看到那些晶体管被用于其他更相关的事情。即使同样是用于进行浮点数学运算(通过 GPU 来做,而不是通过 AVX512 在 CPU 上),或者直接给我更多的核心(有着更多单线程性能,而且没有 AVX512 这样的垃圾),就像 AMD 所做的一样…
(在 CPU 上)AVX2 已经足够了。是的,我就是这么暴躁。
”
不仅仅是吐槽,Linus 身体力行在今年更新了自己使用的桌面电脑,用 AMD 的Ryzen 3950x处理器替换了原来的Intel Core i9 9900K。

也许未来AMD会 宣布支持 AVX-512,或者像传闻那样Intel放弃这套指令集?而我更期待的是预计今年年底发布的采用7nm升级工艺的AMD Zen3 的架构。也许明年我们将会有更多新的实例类型出现,能够确定的一点是这些实例一定是更快、更强、更便宜!