亚马逊AWS官方博客
利用 Amazon Neptune 分析社交媒体馈送信息
Original URL: https://amazonaws-china.com/cn/blogs/database/analyzing-social-media-feeds-using-amazon-neptune/
从各类媒体应用当中生成的数据,一直是帮助组织了解客户情感并收集产品反馈的高价值资源。这类数据也可用于向客户推荐新的产品与服务。更重要的是,这类数据在内容上具备高度关联性,且很难在关系数据库中进行存储与提取。这是因为关系数据库并不会直接存储关系,而是通过表之间的外键关联。在使用关系数据库进行查询时,我们需要执行大量连接操作——此类连接操作不仅难以编写、执行效率低下,还往往需要随着数据模型的变化而持续更新。在这一使用场景下,我们可以利用图数据库直接表达并查询数据关系,借此在应用程序当中更快构建起高连接度数据。本篇文章将从具体用例出发,向您介绍如何利用专用型图数据库对社交媒体馈送内容进行分析。
在本文中,我们将逐步了解如何利用Amazon Neptune处理一套示例社交媒体数据集。Amazon Neptune是一项全托管图数据库服务,其强大的设计功能足以存储来自社交媒体等高连接度数据集内的数十亿种关系。Neptune支持当前流行图模型 Property Graph和W3C的RDF。利用二者分别对应的Apache TinkerPop Gremlin与SPARQL两种查询语言,您将得以轻松对高连接度数据集执行查询。
我们还将共享本案例中用于合并社交媒体馈送内容的程序(访问amazon-neptune-samples 以获取),并进一步展示如何在Neptune中分析这些数据。您可以使用这款实用程序生成数百万个顶点(节点)与边(关系),并将结果加载至您的Neptune集群当中。本文中用到的实用程序代码将全面涵盖社交媒体数据集合并方法、Neptune API的使用、数据提取以及社交媒体图查询等具体操作。值得一提的是,该GitHub repo中的程序代码具备全面可扩展性,开发者朋友可通过修改JSON配置文件灵活变更顶点与边的数量及类型。
下图所示,为该实用程序生成的数据集关系中的图数据模型。图中的圆圈代表顶点,带方向的箭头则表示边。各顶点的标签与属性以方框形式注明。边同样拥有自己的标签,由带方向箭头上的单词表示。各边可拥有一个或者多个属性。

该示例数据集与真实世界中的社交媒体源高度相似。例如,在Twitter数据集当中,用户实体被表示为顶点,用户与关注者间的关系则表示为边。用户顶点可具有Username、City以及Birth Date等属性,而关注关系则拥有Follows since及Weight等属性。Posts与Tweets也构成独立的顶点,二者与User顶点形成发布关系。组织可以借此洞察各类活动,借此识别出用户/关注者行为、受欢迎程度,并通过整体图中的顶点与边结构为特定产品或服务提供建议。
解决方案概述
该解决方案包含以下几个步骤,用于生成、加载并查询数据:
- 克隆之前提到的GitHub repo。
- 利用repo中的Neptune java实用程序生成社交媒体示例数据(图数据由Amazon S3提供)。
- 利用Neptune Loader将数据加载至Neptune当中。
- 使用Apache TinkerPop Gremlin客户端执行图数据库的查询和更新。
以下架构图所示,为解决方案中涵盖的组件及四个操作步骤。
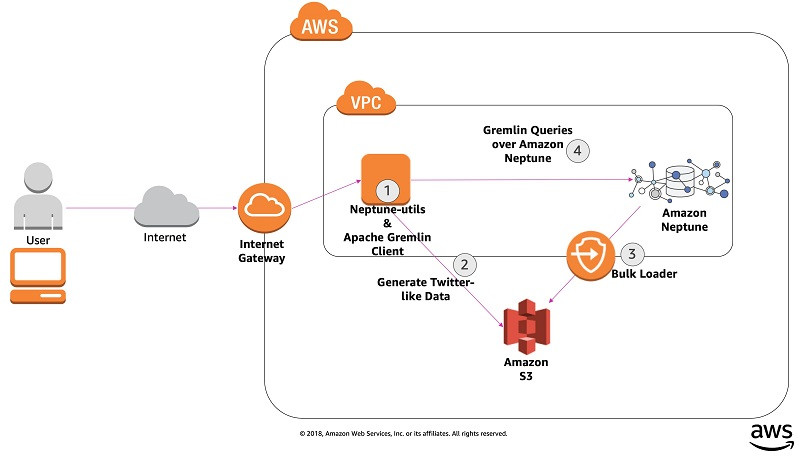
启动AWS CloudFormation堆栈
在开始使用这套解决方案之前,我们首先需要通过Launch Stack与Launch Stack AWS CloudFormation模板启动AWS CloudFormation堆栈。利用模板完成堆栈创建后,程序将自动配置以下基础架构与应用程序组件:
- 单节点Neptune集群(默认数据库实例类型为
r4.large,您可在堆栈创建过程中任意变更)。 - 存储着CSV格式数据的S3桶。
- 将对S3有只读访问权限的IAM角色,附加至Neptune集群。
- 创建S3 VPC端点并将其附加至Neptune集群的VPC。
- 具有实例配置文件的Amazon EC2 实例,可帮助您面向S3执行读取与写入。
- 在EC2实例上安装并配置Java与Maven,用于访问创建完成的Neptune集群。
- 安装并配置Apache TinkerPop Gremlin客户端,用于查询存储在Neptune集群中的图数据。
以下截图所示,为通过第一条AWS CloudFormation模板链接配置VPC时的“Specify”堆栈细节信息部分。在本文中,首个堆栈将被命名为neptune-util-vpc。

以下截图所示,为利用第二个AWS CloudFormation模板创建VPC内部资源时的SPecity堆栈详细信息。

以下截图所示,为Specify堆栈细节页中的其他详细信息。本文将用于保存CSV文件的S3存储桶命名为nep-ej-n500。

以下截图所示,为Specify堆栈细节页面中的其他详细信息。其中neptune-util-vpc中VPCStack字段的值来自先前的AWS CloudFormation模板。

在两个AWS CloudFormation堆栈的状态都显示为Complete之后,连接到通过Cloud Formation模板创建的EC2实例并运行以下步骤。
克隆GitHub repo
在这一步中,我们需要在EC2实例上克隆 amazon-neptune-samples GitHub repo,这是为了让Neptune Java实用程序能够正确生成并加载类似Twitter的社交媒体数据。使用AWS CloudFormation执行中的EC2密钥对以接入EC2实例。
在接入EC2实例时,您可能还需要经由SSH完成连接。关于更多细节信息,请参阅利用SSH连接您的Linux实例。
要克隆此repo,您需要完成以下步骤:
- 在AWS CloudFormation控制台上,选择Outputs。
- 复制
EC2BastionHostName的值。 - 在以下代表中,将host-name 替换为
EC2BastionHostName的值。
- 输入以下代码即可克隆该GitHub repo:
mvn package
生成示例图
在neptune-social-media-utils文件夹中输入以下代码。将其中的s3-bucket部分替换为您在启动neptune-social-media-util-template AWS CloudFormation模板时提供的S3存储桶名称。这里的bucket-folder 可以是您在S3存储桶内创建的任意文件夹名称。
./run.sh gencsv csv-conf/twitter-like-w-date.json <s3-bucket> <bucket-folder>
这条命令将在EC2实例本地文件系统的/tmp 文件夹中生成类似Twitter的合并社交媒体数据,并将结果自动上传至您以参数形式指定的S3存储桶处。
将图数据加载至Neptune中
Neptune提供一款实用程序,可将来自外部文件的数据直接加载至Neptune Database实例中。利用这款实用程序,您可避免手动执行大量 INSERT语句、 addVertex 以及 addEdge步骤或者其他API调用操作。这款实用程序名为Neptune Loader,若需了解更多细节信息,请参阅向Amazon Neptune中加载数据。
在启动先前的AWS CloudFOrmation模板时,您已经创建出一个S3 VPC端点,因此Neptune集群可以通过私有网络实现S3访问。
要使用Neptune Loader,大家首先需要创建并添加一个IAM角色,借此保证集群能够向S3发出GET请求。具体方式如下:
- 在AWS CloudFormation控制台中,记住Outputs选项卡中“NeptuneIAMRole”键所对应的值。
- 在Neptune控制台上,选择Clusters。
- 选定您所创建的Neptune集群。
- 在Actions菜单中,选择Manage IAM Roles。
- 从“Add IAM roles to this cluster”处,选择您在第一步中记住的角色。
- 选择“Add role”。
当状态由Active 变为 Done后,返回Clusters仪表板。
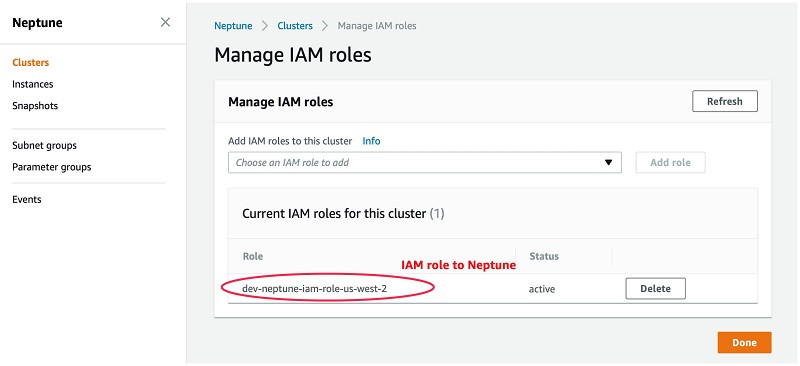
以下截图所示,为Manage IAM roles页。本示例中用于Neptune的IAM角色名称为dev-neptune-iam-role-us-west-2。
现在,您可以将S3存储桶内的数据加载至Neptune集群当中了。具体操作如下:
- 在AWS CloudFormation控制台上,选择Outputs。
- 复制NeptuneEndpointAddress、NeptuneEndpointPort以及NeptuneIAMRole的值。 这些值将在下一步中的neptune-cluster-endpoint、port以及iam-role-arn等位置使用。
- 在 neptune-social-media-utils文件夹中输入以下代码,将s3-bucket-name/folder-name替换为上条./run.sh命令中的对应部分:
./run.sh import <neptune-cluster-endpoint> <port> <iam-role-arn> <s3-bucket-name>/<folder-name> <aws-region-code>
例如,您的实际运行代码可能如下所示:
./run.sh import mytwitterclst.cluster-crhihlsciw0e.us-east-2.neptune.amazonaws.com 8182 arn:aws:iam::213930781331:role/s3-from-neptune-2 neptune-s3-bucket/twitterlikeapp us-east-1
此实用程序会在内部通过Neptune Loader将数据批量加载至Amazon Neptune当中。
如果您打算直接使用Neptune Loader进行数据加载,则可使用以下curl 命令示例:
curl -X POST -H ‘Content-Type: application/json’ https://<amazon-neptune-cluster-endpoint>:8182/loader -d ‘{“source”: “s3://bucket-name/bucket-folder/”,”format”: “csv”,”iamRoleArn”: “arn:aws:iam::<account-number>:role/<role-name>”,”region”: “us-east-1″,”failOnError”: “FALSE”}’
现在,我们已经可以对加载至Neptune中的数据集执行查询了。
运行远程交互查询
在AWS CloudFormation模板的启动过程中,我们已经完成了EC2实例的创建,及该EC2实例上的Apache TInkerPop Gremlin客户端安装与配置工作。
.
要运行远程交互查询,首先需要配置Apache Gremlin Console以接入Neptune数据库实例。
完成后,您可以运行以下查询:
[ec2-user@ip-172-31-59-189 bin]$ cd /home/ec2-user/apache-tinkerpop-gremlin-console-3.4.1/home/ec2-user/apache-tinkerpop-gremlin-console-3.4.1/bin[ec2-user@ip-172-31-59-189 bin]$ bin/gremlin.sh \,,,/ (o o)—–oOOo-(3)-oOOo—–plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphgremlin> :remote connect tinkerpop.server conf/neptune-remote.yaml==>[neptune-cluster-endpoint]/172.31.23.188:8182gremlin> :remote console==>All scripts will now be sent to Gremlin Server – [neptune-cluster-endpoint]/172.31.23.188:8182] – type ‘:remote console’ to return to local mode
gremlin>
您可以从各User顶点中选择一个示例用户,利用它执行查询。具体参见以下代码示例:
gremlin> g.V().has(‘User’,’~id’,’1′).valueMap()
==>{name=[Brenden Johnson]}
要了解哪些人关注了该用户,请输入以下代码示例:
gremlin> g.V().has(‘name’, ‘Brenden Johnson’).in(‘Follows’).values(‘name’)==>Jameson Kreiger==>Yasmeen Casper==>Maverick Altenwerth==>Isabel Gibson
…
要了解有哪些关注者转发了该用户的Tweets,请输入以下代码示例:
gremlin> g.V().has(‘name’, ‘Brenden Johnson’).in(‘Follows’).as(‘a’).out(‘Retweets’).in(‘Tweets’).has(‘name’, ‘Brenden Johnson’).select(‘a’).values(‘name’).dedup()==>Quentin Watsica==>Miss Vivianne Gleichner==>Mr. Janet Ratke
…
若需参考关于搜索与插入查询的更多示例,请参阅GitHub repo中的 twitter-like-queries.txt文件。
修改您的JSON文件
本文展示了如何创建一套简单数据集,并将其加载至Neptune当中。要变更生成的顶点与边的数量及属性,您可以修改twitter-like-w-date.json文件中的对应部分(位于csv-conf/文件夹下)。我们为您提供多个针对微型、小型、中型以及大型数据集的JSON配置文件示例,您可以利用这些配置文件生成数据集并运行交互式查询。
总结
时至今日,社交媒体数据集已经成为各类组织分析客户情绪、识别关系并提供业务建议的高价值素材。本文简要介绍了如何利用Apache TinkerPop Gremlin分析经过合并的社交媒体馈送内容。您可以使用同样的方法对Neptune集群上的应用程序进行负载测试,或者在大型数据集上对查询性能进行基准测试。如果您对本文的内容有任何建议或意见,欢迎在评论中留言分享。