亚马逊AWS官方博客
构建在Amazon EMR之上的Apache Atlas展现数据目录和数据血缘
一、背景介绍
在数据驱动业务的时代,各行各业中不同体量的客户都意识到数据的重要性,但是面对日益增加的各式各样的数据,如何知晓这些数据是什么,什么时间,什么地方发生了变化,这个数据的拥有者又是谁,等等。只有清楚的知晓这些内容,才能让不同的业务部门利用到数据,也才能做到数据驱动业务。这个时候,数据的元数据管理与数据治理成为企业级数据湖的重要部分。本文聚焦于构建在Amazon EMR之上的Apache Atlas展现数据目录和数据血缘。
二、简要说明
Amazon EMR是是一个托管的Hadoop平台,可简化运行大数据框架(如Apache Hadoop和Apache Spark)的方式, 在亚马逊云科技的公有云平台上处理和分析海量数据。借助这些框架和相关的开源项目 (如 Apache Hive 和 Apache Pig)。您可以处理用于分析目的的数据和商业智能工作负载。此外,您可以使用 Amazon EMR 提取/处理/载入数据到其他亚马逊云科技的数据存储和数据库中,例如 Amazon Simple Storage Service (Amazon S3) 。
Apache Atlas最早由HortonWorks实现,用来管理Hadoop项目里面的元数据,进而设计为数据治理的框架。后来开源出来给Apache社区。以下是其架构图: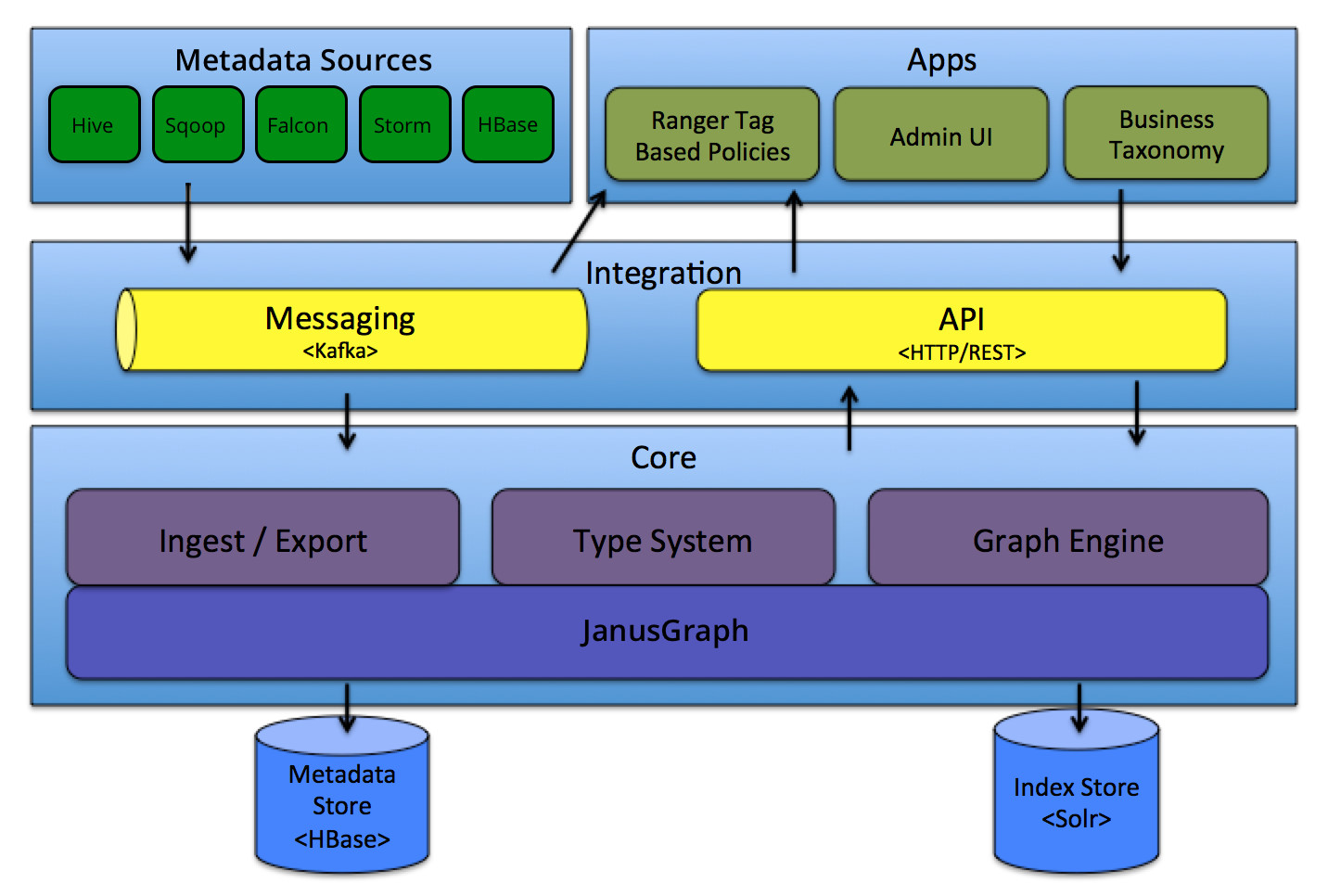
图片来源:https://atlas.apache.org/#/Architecture
该框架天然就支持横向扩展,能很好的和Hadoop平台中其他组件进行集成,非常适合在共有云上使用。
Apache Atlas的最核心部分就是类型管理系统(Type System),用户可以把数据资产进行类型定义,然后使用Ingest/Export模块进行元数据的导入、修改、删除等管理。和外界的接口可以通过Http/Rest API或使用Kafaka进行消息交换。数据对象存放在按照图的模式进行管理的JanusGraph图数据库中,具体JanusGraph又把元数据存放在HBase中,索引存放在Solr中。这样用户可以非常便捷和直观的通过层次图进行浏览,可以按照字符串进行精确的检索。
另外,Atlas为组织提供开放的元数据管理和治理能力,以建立其数据资产的目录。Atlas支持数据的分类,数据发现,数据血缘。它还提供了搜索关键元素及其业务定义的功能。
三、环境部署
此处我们会使用两种方式来创建Amazon EMR集群和安装Atlas,分别是手动创建Amazon EMR集群和安装Atlas,以及通过CDK来自动创建Amazon EMR集群和安装Atlas
(一)手动创建Amazon EMR集群和安装Atlas
1) 创建Amazon EMR集群
首先创建一个带有Apache Hadoop、Hive、HBase、Hue和ZooKeeper等应用的Amazon EMR集群。Apache Atlas使用Apache Solr进行搜索功能,使用Apache HBase进行存储。Solr和HBase都安装在持久的Amazon EMR集群上,作为Atlas安装的一部分。

下面的命令显示Amazon EMR集群的状况

如下图说明集群已经正常可用。
2) 创建额外的步骤
此步骤主要是安装Atlas的和kafka这样的依赖的组件。具体内容请查看Github 链接( https://github.com/jerryjin2018/Bigdata-Atlas/blob/main/apache-atlas.sh )
正常执行完成。

登陆到Amazon EMR集群master节点上,可以看到Atlas服务已经启动,并且监听在21000端口。
(二)通过CDK自动创建Amazon EMR集群和安装Atlas
可以参考链接 https://github.com/aws-samples/aws-cdk-emr-atlas
1) 准备前置条件
(1)你需要准备一个密钥对,将被赋给Amazon EMR集群中的EC2实例,在接下来步骤中的aws-cdk-emr-atlas/aws-emr-cdk目录中的app-config.yaml文件中进行配置
(2)你需要创建两个S3桶,并在app-config.yaml中配置为s3_log_bucket和s3_script_bucket

(3)将aws-cdk-emr-atlas/aws-emr-cdk放置到刚才为s3_script_bucket创建的S3桶,上面的例子中的jerry-cdk-emr-script-bucket
(4)EMR服务的IAM角色和工作流IAM角色将被自动创建
(5)一个带有公共子网的VPC将被自动创建
2) 创建Amazon EMR集群
亚马逊云科技Cloud Development Kit(CDK) 是一种开源软件开发框架,可让您使用熟悉的编程语言来定义云应用程序资源。
亚马逊云科技CDK利用编程语言的常见性和表达能力为应用程序建模。它为您提供名为结构的高级组件,使用经过验证的默认值预配置云资源,因此您无需成为专家也可构建云应用程序。亚马逊云科技CDK通过亚马逊云科技 CloudFormation以安全、可重复的方式预置您的资源。它还支持您编写和分享体现组织要求的自定义结构,帮助您更快启动新项目。
按照此链接( https://docs.aws.amazon.com/zh_cn/cdk/latest/guide/getting_started.html )
中的步骤,安装CDK和下载相关安装代码(此处以Amazon Linux 2环境为例)

注意修改一下aws-cdk-emr-atlas/aws-emr-cdk目录中app-config.yml文件的内容,主要就是替换你的亚马逊云科技的Account ID和对应EMR集群所在的区域。还有就是EMR的版本和S3桶的桶名和秘钥对,具体是如下5项你已经准备了的.

另外就是用如下命令将apache-atlas-emr.sh上传到为s3_script_bucket创建的S3桶,上面的例子中的jerry-cdk-emr-script-bucket

安装相应的依赖包和创建Amazon EMR集群和安装Atlas


创建Amazon EMR集群的过程
 下面的命令显示Amazon EMR集群的状况
下面的命令显示Amazon EMR集群的状况

登陆到Amazon EMR集群master节点上,可以看到Atlas服务已经启动,并且监听在21000端口。

(三)后续步骤
1) 创建浏览器代理
因为创建的Amazon EMR集群中服务(除了SSH服务)是不会直接对公网开放的,那如何从你的workstation访问这些服务了。可以通过“使用SSH动态端口转发与主节点之间的 SSH 隧道” https://docs.amazonaws.cn/emr/latest/ManagementGuide/emr-ssh-tunnel.html
和“配置浏览器代理以查看EMR主节点上托管的服务“ https://docs.amazonaws.cn/emr/latest/ManagementGuide/emr-connect-master-node-proxy.html
来访问。
2) 访问Atlas
通过亚马逊云科技Amazon EMR的页面,我们可以看到我们刚刚创建的EMR集群的信息。当我们选择”应用程序历史记录”选项时,我们可以看到On-cluster application user interfaces的信息,这里包含了EMR集群中的一些服务的访问地址。我们按照“HDFS 名称节点”的URL的格式,将端口换为21000,我们就可以访问Atlas的服务页面

在开启SSH动态端口转发情况下,访问Atlas的web界面(默认的用户名和密码都是admin),如下图:
Atlas 允许用户为他们想要管理的元数据对象定义一个模型。该模型由称为 “类型” (type)的定义组成。这些元数据对象也被被称为“实体”(entities)。由 Atlas 管理的所有元数据对象(例如Hive表)都使用类型进行建模,并表示为各种类型的“实体”(entities)。
Type:Atlas中的 “类型” 定义了如何存储和访问特定类型的元数据对象。类型表示了所定义元数据对象的一个或多个属性集合。如果您有开发背景,很容易将 “类型” 理解成面向对象的编程语言的 “类” 定义的或关系数据库的 “表模式”。
当我们在Atlas的SEARCH选项中的“Search By Type”中选择Asset再Search,可以看到我们目前什么内容也没有,因为数据目录中还没有数据:
四、数据目录和数据血缘
1) 创建实验数据一
Atlas安装包提供了两个例子数据。登陆到Amazon EMR的master节点上,我们先来看看这两个例子数据:
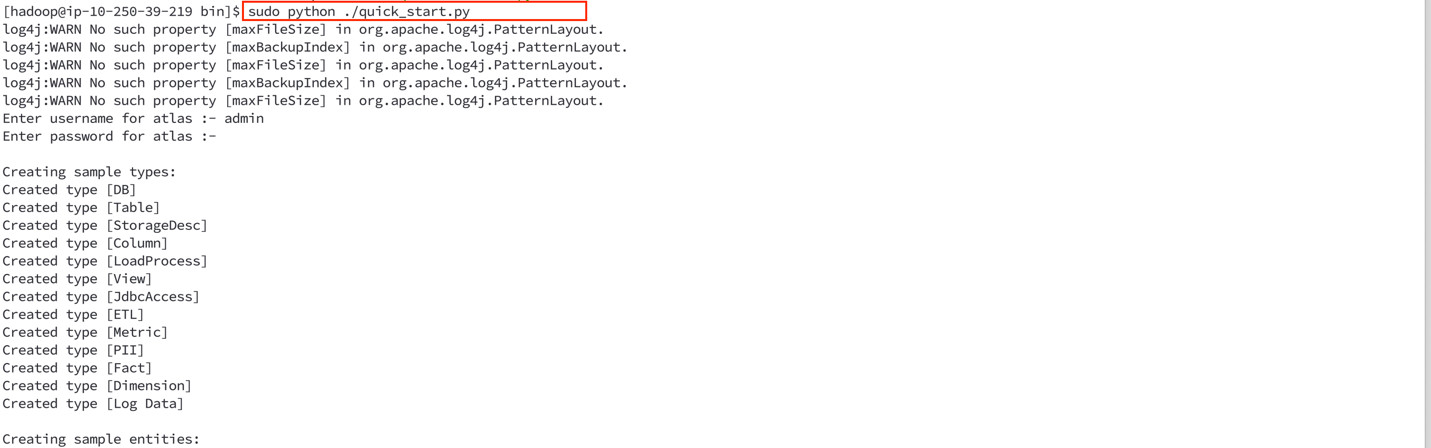
…

我们在Atlas中再Search Asset,看到了各种类型(Type)的“实体”(entities)。
Atlas 提供了一些预定义的系统类型,特别是如下的集中类型:
Asset:此类型包含名称,说明和所有者等属性
DataSet:此类型扩展了Referenceable和Asset 。在概念上,它可以用于表示存储数据的类型。在 Atlas 中,hive表,Sqoop RDBMS表等都是从 DataSet 扩展的类型。扩展 DataSet 的类型可以期望具有模式,它们将具有定义该数据集的属性的属性。例如, hive_table 中的 columns 属性。另外,扩展 DataSet 的实体类型的实体参与数据转换,这种转换可以由 Atlas 通过 lineage(血缘)生成图形。
Process:此类型扩展了Referenceable和Asset 。在概念上,它可以用于表示任何数据变换操作。例如,将原始数据的 hive 表转换为存储某个聚合的另一个 hive 表的 ETL 过程可以是扩展过程类型的特定类型。流程类型有两个特定的属性,输入和输出。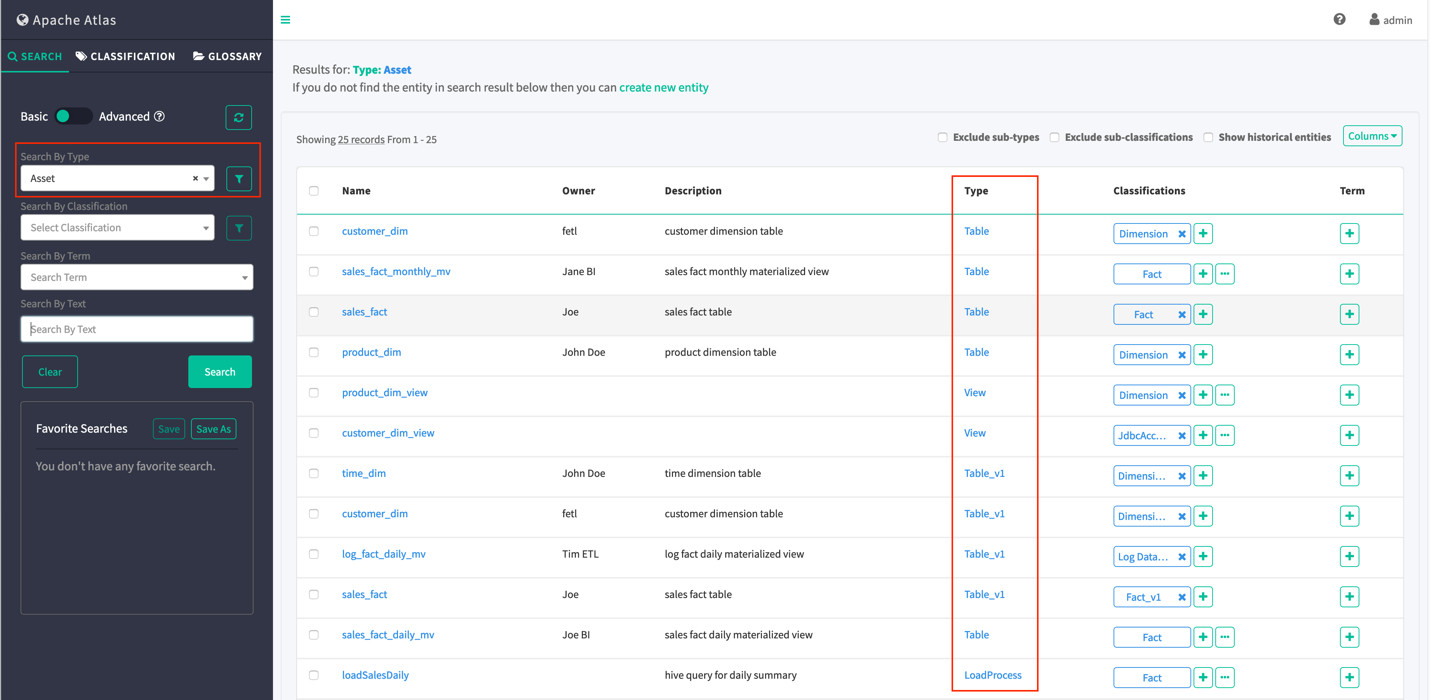
Apache atlas的其中一个核心特性就是可以追溯数据湖中数据的血缘关系(lineage)并以可视化的方式呈现,使用户能够快速了解数据的生命周期,并能够知晓数据是从那里来以及和数据湖中数据之间的关联关系。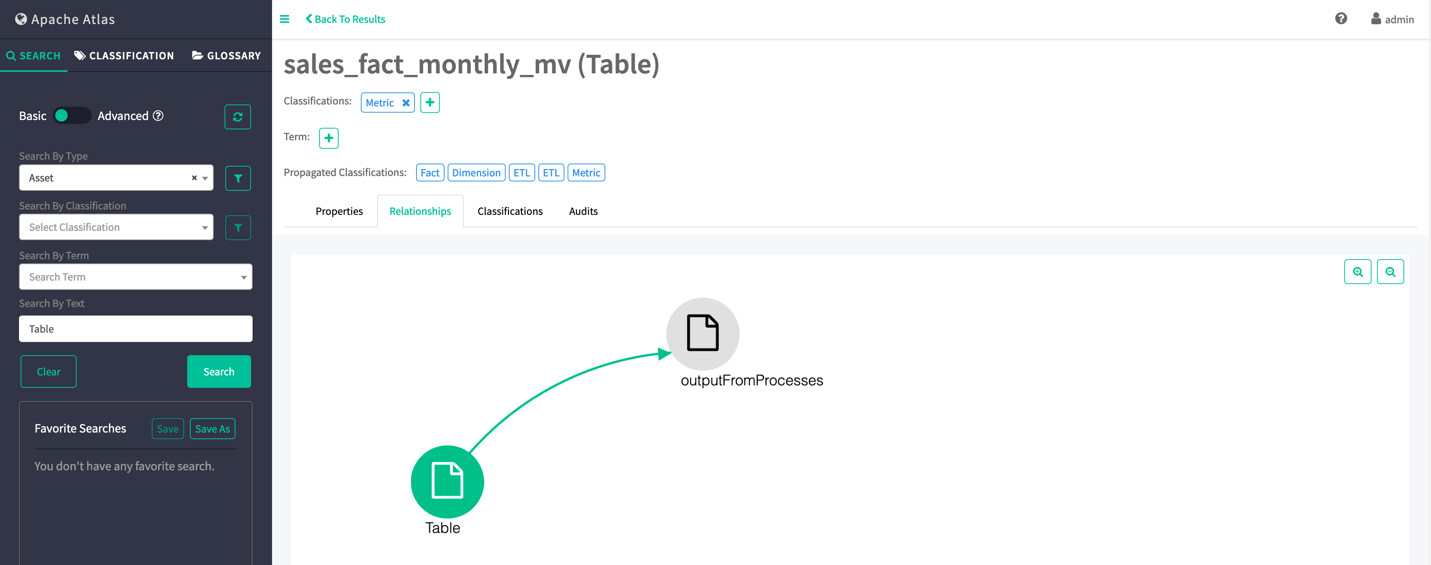
2) 创建实验数据二
我们来创建一些Hive的外表,从如下链接下载一些公开的数据集,并做简单处理(删除几个不需要的字段,和更改字段名称),再将数据文件上传到笔者的名称为aws-bigdata-jerry-blog的S3存储桶中。
https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
登陆到Amazon EMR集群的master节点上,在命令提示符处,输入命令:

创建trip_details表

创建trip_zone_lookup表

查看trip_details和trip_zone_lookup表的数据的条数:

创建一个由trip_details和trip_zone_lookup join的表trip_details_by_zone

这次我们在Atlas中再Search Asset,看到了更多类型(Type)的“实体”(entities),特别是hive_table,hive_column和hive_process.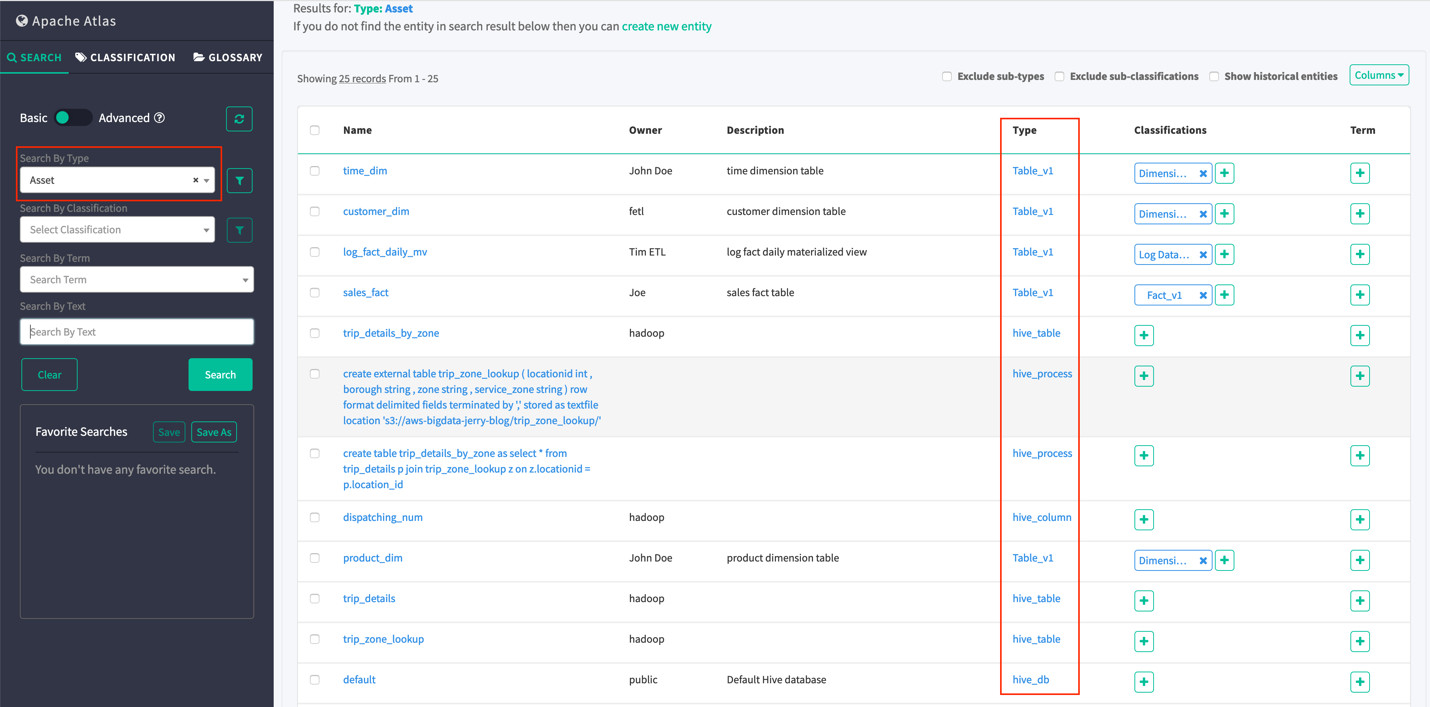
这次我在Atlas左侧选择的SEARCH选项中的“Search By Type”中选择hive_table, “Search By Text”中选择trip_details_by_zone,再Search: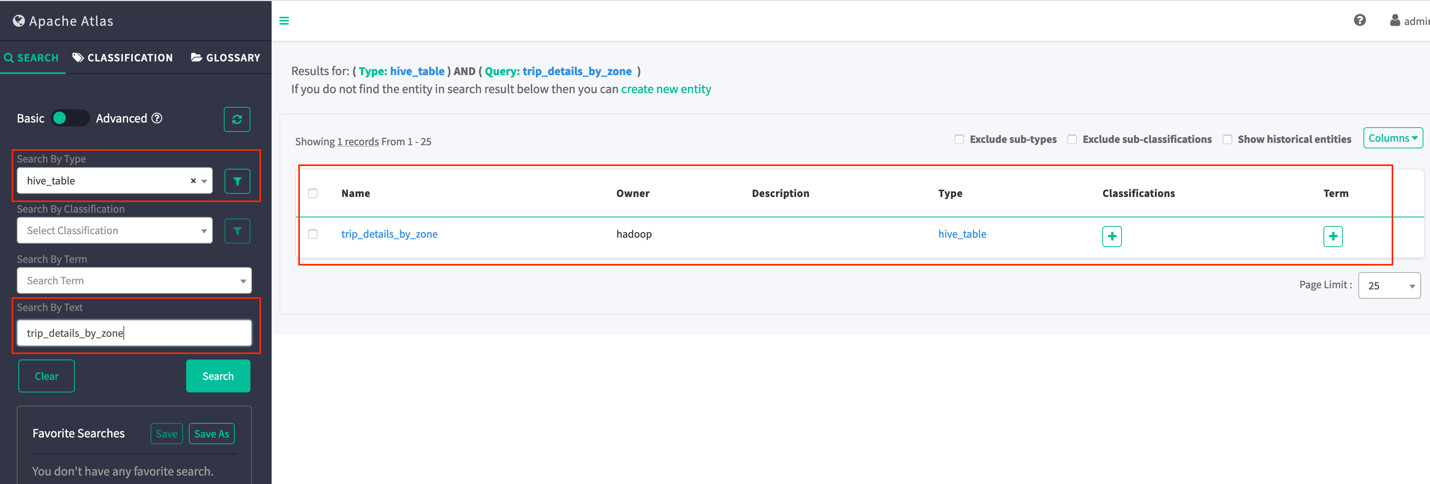
从Properties,我们能看到关于这张表的信息,特别是这张表中的数据字段是什么,什么时间,什么地方发生了变化(创建时间),这个数据的拥有者又是谁,等等。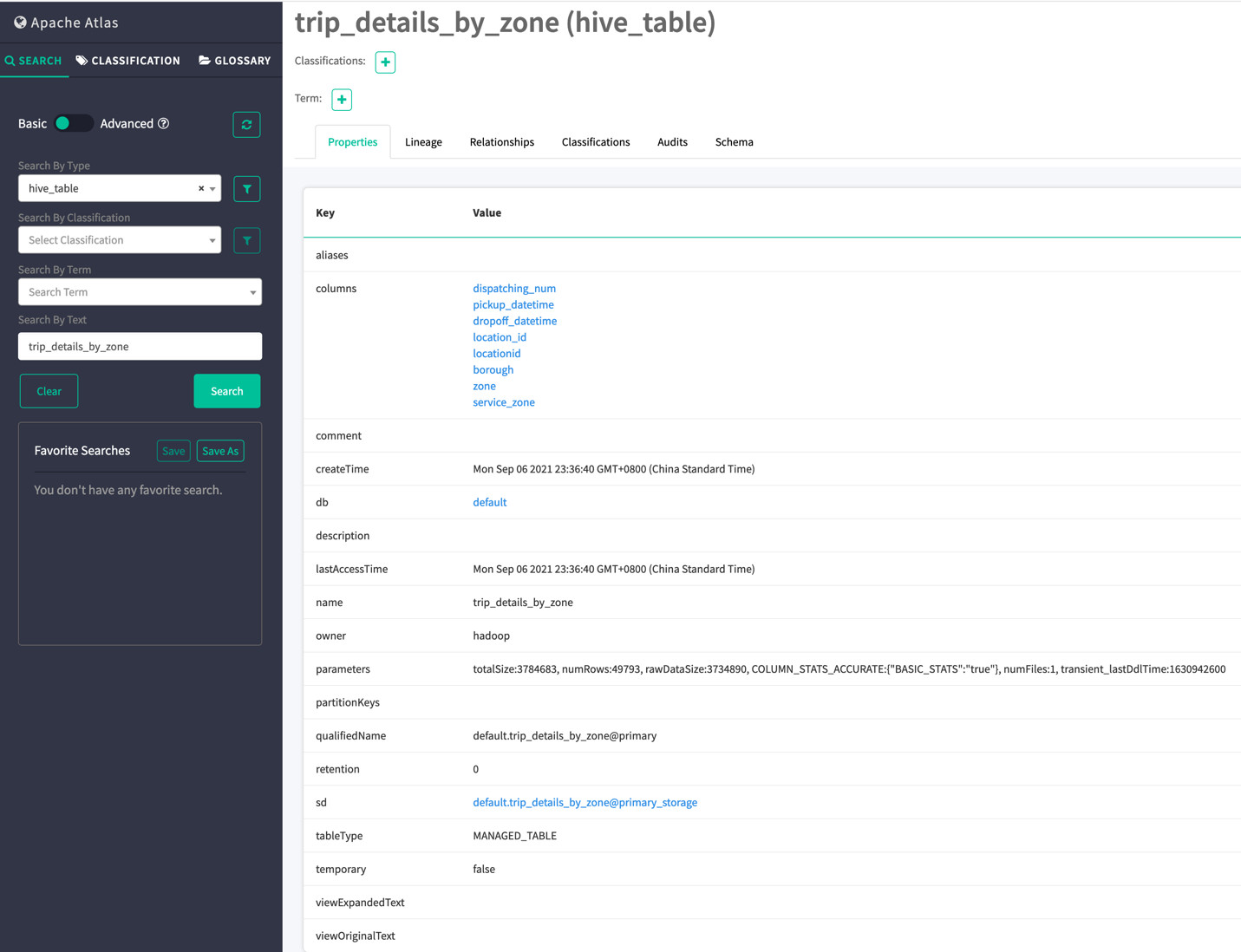
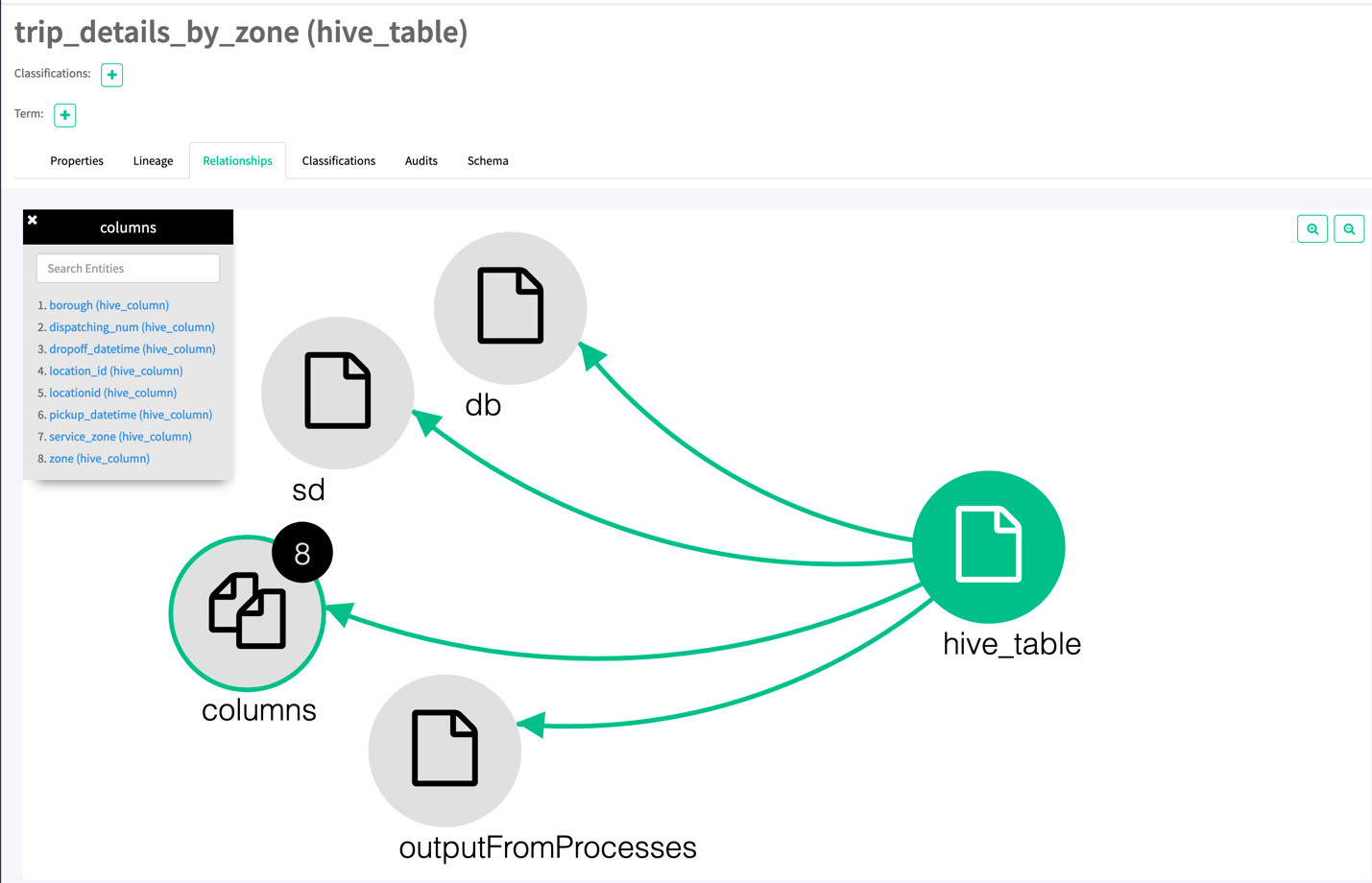
我们再来看一下表trip_details_by_zone的血缘关系(lineage)和关系(Relationships)
五、总结
在这篇博客中,我们概述了通过使用AWS CLI和通过CDK来安装和配置Amazon EMR集群,以及在Amazon EMR集群之上部署和配置Apache Atlas。我们还探讨了如何将数据导入Atlas,并使用Atlas界面来查询和查看相关数据的数据目录和数据血缘。
参考材料:
https://www.jianshu.com/p/c65f54dd5e7d
https://my.oschina.net/sunmin/blog/3064462
https://atlas.apache.org/2.0.0/InstallationSteps.html
https://developpaper.com/getting-started-with-apache-atlas/