亚马逊AWS官方博客
AWS Lambda:不同应用及 I/O 模型的成本效益
引言
AWS Lambda,作为一种极受欢迎的无服务器计算服务,通过其独特的计费方式——根据函数调用次数和执行时间——提供了一种高效的成本管理方式。这种基于事件驱动模型的服务,与传统需要预置计算资源的部署方式相比,能够在许多情况下显著降低基础设施成本。然而,Lambda 的成本效益并非在所有情境下都一样显著。那么,是什么因素导致了 Lambda 在不同工作负载和使用场景下的成本表现出显著差异呢?
在这篇博客中,我们将深入探索 Lambda 在不同应用类型和编程语言上的成本差异。我们的目标是提供清晰的见解,帮助您更有效地评估和设计应用程序的部署策略,以及在其完整生命周期中做出明智的成本效益权衡。
Lambda 运行方式
在同步调用 AWS Lambda 的场景中,如通过 API Gateway 或 Function URL,每一个 HTTP 请求或事件都由一个独立的 Lambda 实例处理。利用其超轻量级虚拟化技术,Lambda 能够在极短的时间内初始化(通常被称为“冷启动”)并执行函数。这种快速启动能力确保了即使在高并发请求下,每个事件都能迅速得到响应。处理完当前事件后,每个 Lambda 实例可以继续处理后续的事件。这种灵活的实例管理机制不仅提高了资源的利用效率,也为不同规模和类型的工作负载提供了强大的支持。
1 个 Lambda 实例处理多个请求/事件:
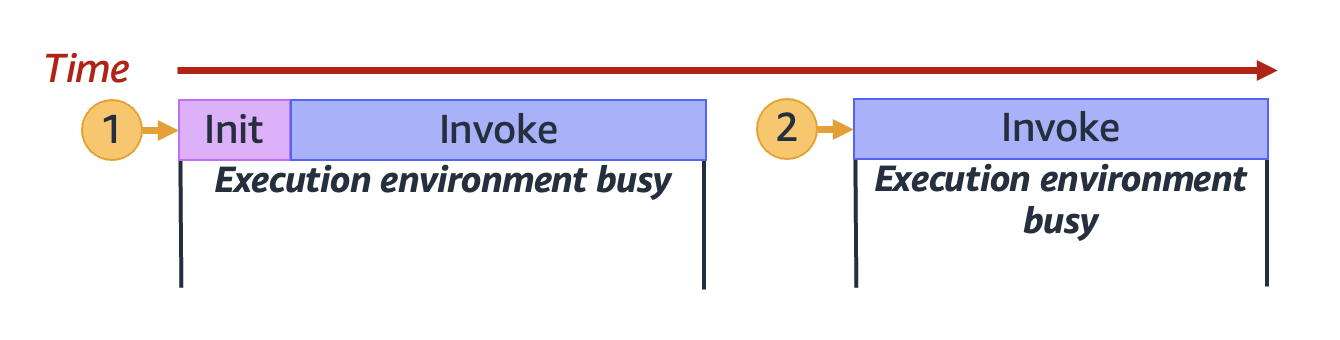
多个 Lambda 实例并行处理多个请求/事件:
我们可以看到,每个 Lambda 实例在处理请求时,执行环境处于忙碌状态,不能处理其他请求。
同步 IO 与异步 IO
不同编程语言处理 I/O(输入/输出)操作的方式在同步和异步机制上有显著差异,这直接影响 Web 应用的性能和响应能力。同步 I/O 操作会导致执行环境在等待操作完成期间阻塞,即在一个操作未完成之前,不会执行下一个操作,在这个阻塞期间,CPU 是保持在空闲状态的。而异步 I/O 则允许在等待一个操作完成的同时执行其他操作,尽可能利用 CPU 去处理其他请求,从而提高了效率和程序的响应能力。
以 Node.js 和 Python 为例,Node.js 以其非阻塞的异步 I/O 模型著称,这意味着它可以在处理大量并发请求时保持高效。当一个 Node.js 应用接收到一个请求,对数据库发起了一次查询(网络 I/O)时,它可以立即处理其他请求,而不必等待当前的数据库 I/O 操作完成。这使得 Node.js 在单线程下依然具备一定的并行处理能力。
相比之下,Python 在其标准库中通常采用同步 I/O 模型。这意味着当一个 Python Web 应用(如使用 Flask 或 Django 框架)执行 I/O 操作(如数据库查询)时,应用会在 I/O 完成前停滞。尽管 Python 提供了如 asyncio 等异步编程库来克服这一限制,但这通常需要额外的编程工作和对异步编程模式的理解。
异步 IO 与 Lambda
每个 Lambda 实例在处理一个请求时会处于忙碌状态并且无法同时处理其他请求,这与异步 I/O 的并行处理能力事实上存在一定冲突。在传统的异步 I/O 模型中,特别是在像 Node.js 这样的环境中,单个实例在同一时刻能够有效地并行处理多个 I/O 操作,从而优化资源使用并提高性能。然而,在 Lambda 的上下文中,这种并行处理能力受到限制。
当一个 Lambda 函数被触发,它会启动一个新的实例来处理那个特定的请求。这意味着,尽管在其他环境中异步 I/O 能够提供高效的并行数据处理,但在 Lambda 中,每个实例仅能在任何给定时刻处理单一请求。这种限制导致在单位计算资源下,Lambda 无法充分发挥异步 I/O 在其他环境中的高并行性能优势。
从一个 Lambda 实例的视角来看,多个请求是串行处理的,约等于:我写的异步 I/O 的代码,在 Lambda 上运行“阻塞”了。
那么这是否意味着在 Lambda 上运行异步 I/O 的代码就会导致资源的完全浪费呢?实际上并非如此。接下来,我们将继续深入探讨 I/O 密集型和 CPU 密集型应用之间的差异。
I/O 密集型与 CPU 密集型应用
I/O 密集型应用和 CPU 密集型应用在资源利用和计算需求上有明显的区别。理解这些差异对于设计和优化应用至关重要,特别是在 AWS Lambda 这样的环境中。
I/O 密集型应用主要以输入/输出操作为主,如文件读写、数据库操作和网络通信。这类应用的性能瓶颈通常在于等待 I/O 操作的完成,而非 CPU 的计算速度。异步 I/O 模型在这种应用中特别有用,因为它允许程序在等待一个 I/O 操作完成的同时继续执行其他任务,提高整体效率。
相反,CPU 密集型应用则主要依赖 CPU 资源来执行复杂的计算任务,如图像处理、数据分析等。这些应用的性能瓶颈主要在于 CPU 的处理能力。在 CPU 密集型任务中,CPU 资源被大量占用以执行计算,留给 I/O 处理的空间极小。
在这种背景下,异步 I/O 在 CPU 密集型应用中的优势就不明显了。由于 CPU 资源被密集计算任务所占据,异步 I/O 的并行处理能力受限,无法充分发挥。因此,虽然异步 I/O 在 I/O 密集型应用中可以显著提升性能,但在 CPU 密集型应用中,它的效果便不如预期。
Lambda 与不同应用类型结合分析
在讨论 AWS Lambda 与不同类型应用的适配性时,重要的是理解 Lambda 的运行特性以及如何与应用类型的需求相匹配。以下是针对 Lambda 与两种应用类型——I/O 密集型和 CPU 密集型——的三种不同组合情况的分析:
- Lambda 与 I/O 密集型应用(异步 I/O 代码):
在这种组合中,存在资源利用的冲突。尽管异步 I/O 代码旨在提高效率和并行处理能力,但 Lambda 的运行模型限制了这一优势。由于每个 Lambda 实例在处理一个请求时不可处理其他请求,因此异步 I/O 的并行处理能力并不能在 Lambda 环境中得到充分利用。尤其是在并发请求较多的场景下,这会表现出资源利用率不高,成本相比在虚拟机或容器中部署更高的情况。
- Lambda 与 I/O 密集型应用(同步 I/O 代码):
Lambda 与同步 I/O 代码的 I/O 密集型应用相结合是一个非常合适的选择。在这种情况下,I/O 操作会阻塞线程,因此需要多个线程或进程来提供更高的并行处理能力(取决于不同编程语言对多线程的支持与优化)。Lambda 的运行方式是每个请求由一个独立实例处理,类似于多进程模型。同时,这种模式为开发提供了额外便利,在传统的多核心虚拟机环境中,充分利用所有计算资源通常需要额外的代码编写和复杂的并发处理逻辑。而在 Lambda 环境中,只需要专注于每个请求的处理逻辑,无需担心底层的资源管理和扩展。
- Lambda 与 CPU 密集型应用:
Lambda 与 CPU 密集型应用非常匹配。在这种场景中,Lambda 能够迅速扩展,在极短时间内提供数百上千个独立的实例来并行处理请求,每个实例都拥有自己独立的计算资源。这种快速扩展的能力特别适合于需要大量并行计算的 CPU 密集型应用,如大数据处理和复杂计算任务。Lambda 的这一特性使得它能够有效地处理高强度的计算需求,同时保持极高的灵活性和成本效益。
几个简单的例子:
| 应用程序 | IO 密集型/CPU 密集型 | 编程语言及 I/O 模型 | 运行环境选择 |
| Python Langchain Agent | IO 密集型
Agent Loop 中包含多次 LLM 接口调用(秒级耗时) |
Python Langchain 同步 I/O | Lambda |
| Python Langchain Agent | IO 密集型
Agent Loop 中包含多次 LLM 接口调用(秒级耗时) |
Python Langchain 异步 IO,同时所有 Tools 等工具都需要支持异步 IO | 虚拟机/容器 |
| Node.js Express API server | IO 密集型
每个请求/事务处理中包含数据库或外部 API 调用 |
Node.js 异步 IO | 虚拟机/容器 |
| Next js Web 应用 | CPU 密集型
在服务端渲染 React 组件/页面比较消耗 CPU 资源(SSR) |
Node.js 异步 IO | Lambda |
| Superset BI 工具 | IO 密集型
通过 Superset 对 Redshift、Athena 等计算引擎做 Ad hoc 查询是非常耗时的 I/O 操作 |
Python Flask 同步 I/O | Lambda |
结论
AWS Lambda 的出现极大地降低了开发者在应用程序扩展方面的成本和复杂性。我们现在可以通过编写 API 并部署在 Lambda 上,轻松扩展至每秒处理数千个请求。这种模型在初期阶段——从 0 到 1 的过程中特别突出其成本效益。然而,随着应用流量的增加,Lambda 的成本效益可能与我们最初的预期产生偏差。
这一现象提醒我们,深入理解我们所编写的应用程序的属性及其 I/O 模型至关重要。为了最大化 Lambda 的效益以及架构整体的拥有成本,我们需要对代码进行深入分析,以便更好地在性能、成本和可扩展性之间做出正确的权衡。
题外话
在探讨完今天这篇内容后,我们可以看到,在处理同步 I/O 或 CPU 密集型应用时,Lambda 的扩容能力和效率是其强大的优势。那么,回头再看我们常说的“冷启动”,是不是突然感觉它不再是那个让人闻风丧胆的“洪水猛兽”了呢?比起在传统服务器或容器集群环境下,需要几十秒甚至几分钟来扩容 1 个新的副本,Lambda 能在几百甚至几十毫秒内启动新的实例并立即执行代码处理用户请求,这可是相当明显的优势!看来,在 Lambda 的世界里,“慢”也有快的时候,就像是在说:“别急,给我几百毫秒,我就能给你一个新世界。”
参考文档
https://docs.aws.amazon.com/lambda/latest/dg/lambda-concurrency.html
https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtime-environment.html
https://aws.amazon.com/blogs/opensource/firecracker-open-source-secure-fast-microvm-serverless/